In my last post, I shared why enterprises need autonomous, agentic workflow–ready data. But knowing why is only half the story. The next question is: what does it actually take to build agentic AI workflows in the enterprise?
The answer starts with business ROI, but it only succeeds if underpinned by the right technology foundation. Let’s understand this journey.
1. Start with Business ROI: Use Cases That Matter
The promise of agentic AI is not abstract; it’s about hard ROI measured in hours saved, costs reduced, compliance improved, and revenue accelerated. Enterprises that embed AI-driven agents into their workflows are already reporting significant returns.
For example:
- Operational Efficiency & Automation Omega Healthcare implemented AI-driven document processing to handle medical billing and insurance claims at scale. The results: 15,000 hours saved per month, 40% reduction in documentation time, 50% faster turnaround, and an estimated 30% ROI. 👉 Read more
- Labor Reduction & Productivity Gains In accounts payable, agentic automation is now capable of managing up to 95% of AP workflows—covering exception resolution, PO matching, fraud detection, and payments—dramatically reducing manual overhead. 👉 See details
- Topline Revenue Growth & Cash Flow Optimization A mid-sized manufacturer deploying AI invoice automation cut manual effort by 60% and reduced invoice approval cycles from 10 days to just 3 days. This improved supplier satisfaction while accelerating cash flow—a direct driver of topline agility. 👉 Learn more
- Trust & Compliance A South Korean enterprise combined generative AI with intelligent document processing for expense reports, cutting processing time by over 80%, reducing errors, and improving audit compliance—while the system continuously learned from user feedback. 👉 Case study
The business ROI is clear. But ROI only materializes if the technology foundation is strong.
2. The Technology Foundation for Agentic AI
Agentic AI requires more than just a clever model. It needs a robust stack that ensures agents act on data that is accurate, fresh, and explainable. Without this, automation becomes brittle, outputs are untrustworthy, and scaling to new use cases is nearly impossible.
As a founder, I can’t help but see the parallel to building a company. Every wise founder, investor, or YC advisor repeats the same lesson: scaling before product–market fit is risky. You can grow fast in the short term, but without nailing the fundamentals, you eventually hit a wall.
The same is true for AI: scaling before nailing is risky. And here, what needs to be nailed is data infrastructure and AI infrastructure.
You can launch impressive AI pilots, but without reliable data and context, failures show up quickly—hallucinations, inconsistent outputs, compliance gaps.
By investing first in the foundation—valid, explainable, governed data pipelines—you enable AI to scale safely and accelerate into new use cases with confidence.
The foundation determines how fast and how far you can grow.
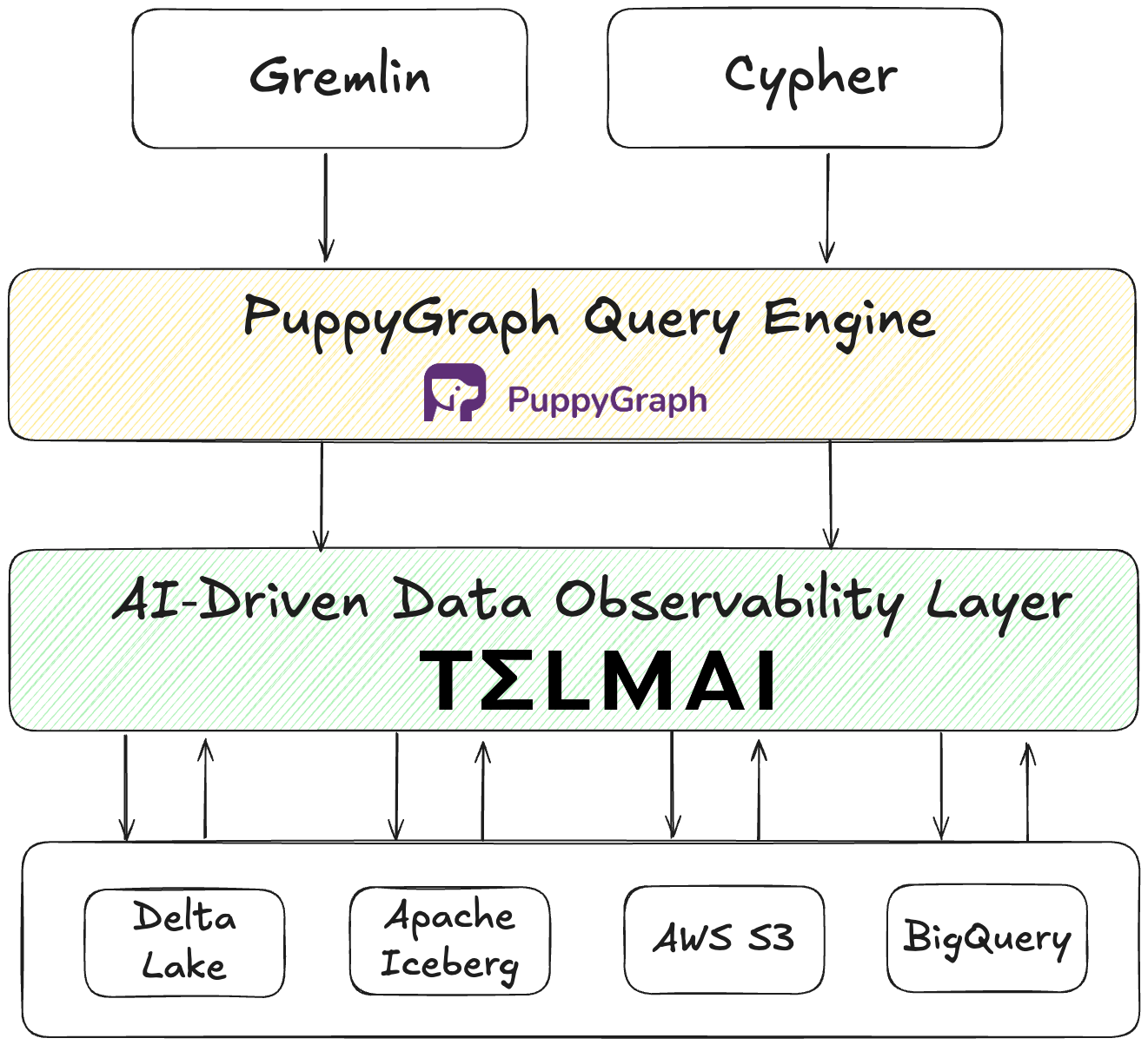
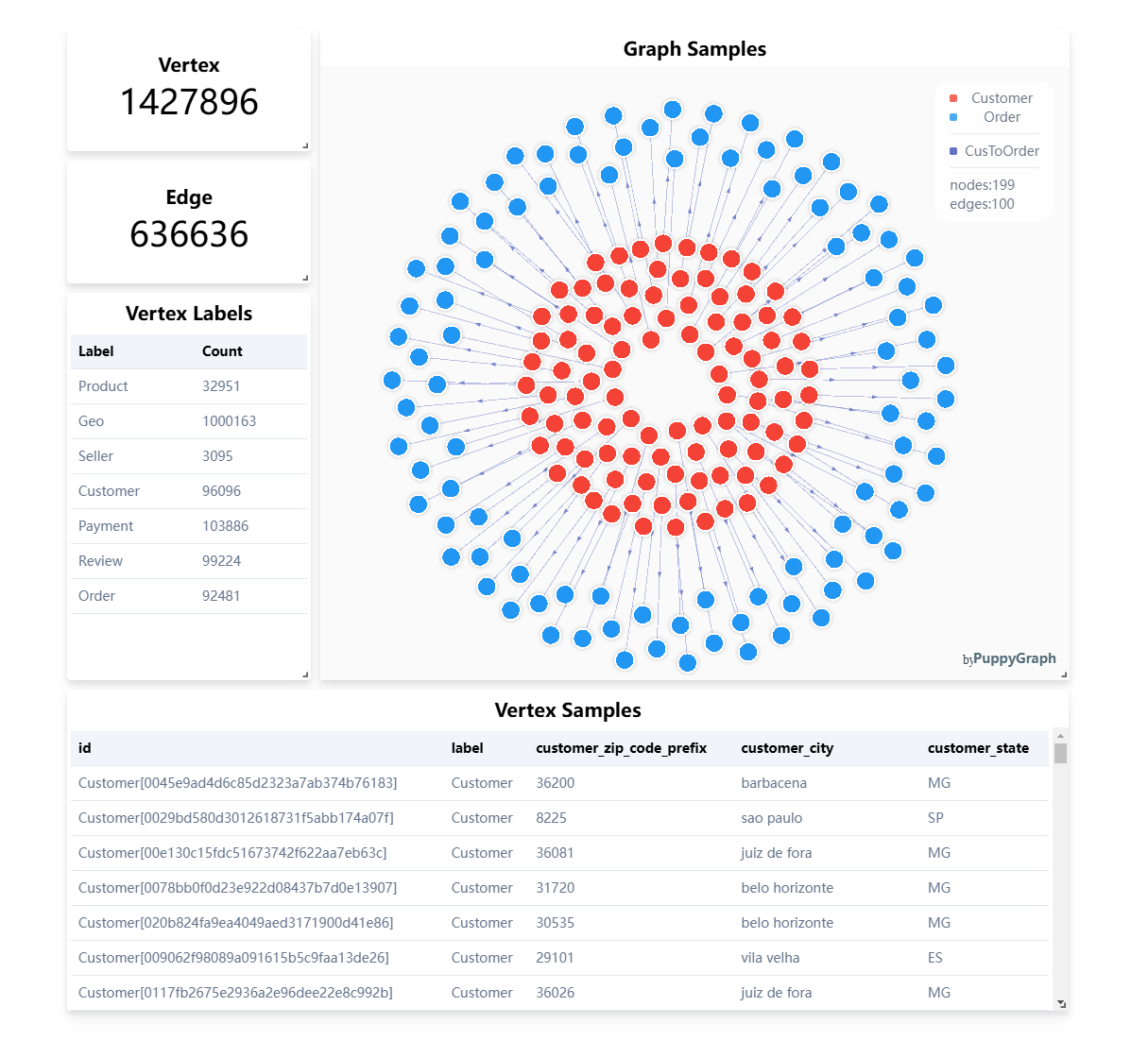
At the heart of this foundation is the Lakehouse architecture. Why? Because agentic workflows rely on low-latency access to both structured and unstructured data, and the Lakehouse unifies both in open formats like Iceberg, Delta, and Hudi.On top of this foundation, enterprises layer:
- Purpose-built query engines (Trino, Spark, proprietary engines) that allow federated access to diverse sources.
- A context layer: governance, lineage, semantics, and—critically—data quality signals.
Just as startups succeed by nailing the core before scaling, AI succeeds by nailing its data and infrastructure foundation before attempting ambitious, agentic workflows.
3. The Three Pillars of Agentic AI Technology
When you strip it down, the technology requirements for agentic AI come down to three pillars: Data, Models, Queries, and Context.

Data
Data is not just about landing rows in a table—it spans the entire lifecycle:
- Storage in scalable, cost-effective object stores (S3, ADLS, GCS).
- Transfer across batch or streaming pipelines.
- Access & Discovery through catalogs and metadata systems.
- Querying for analytics, training, or real-time decisioning.
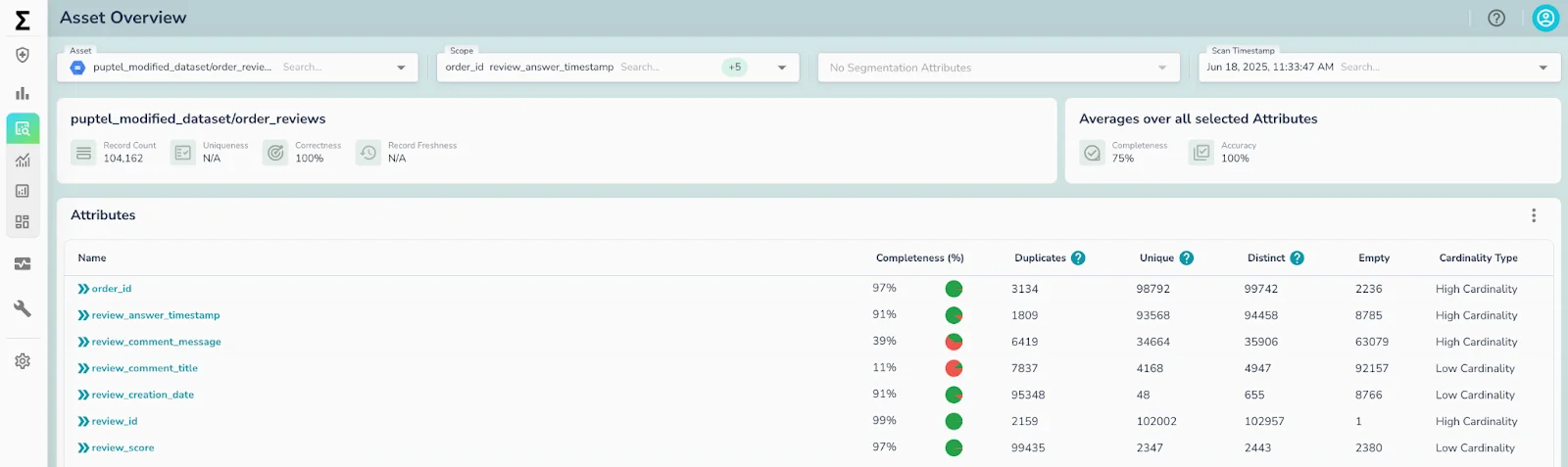
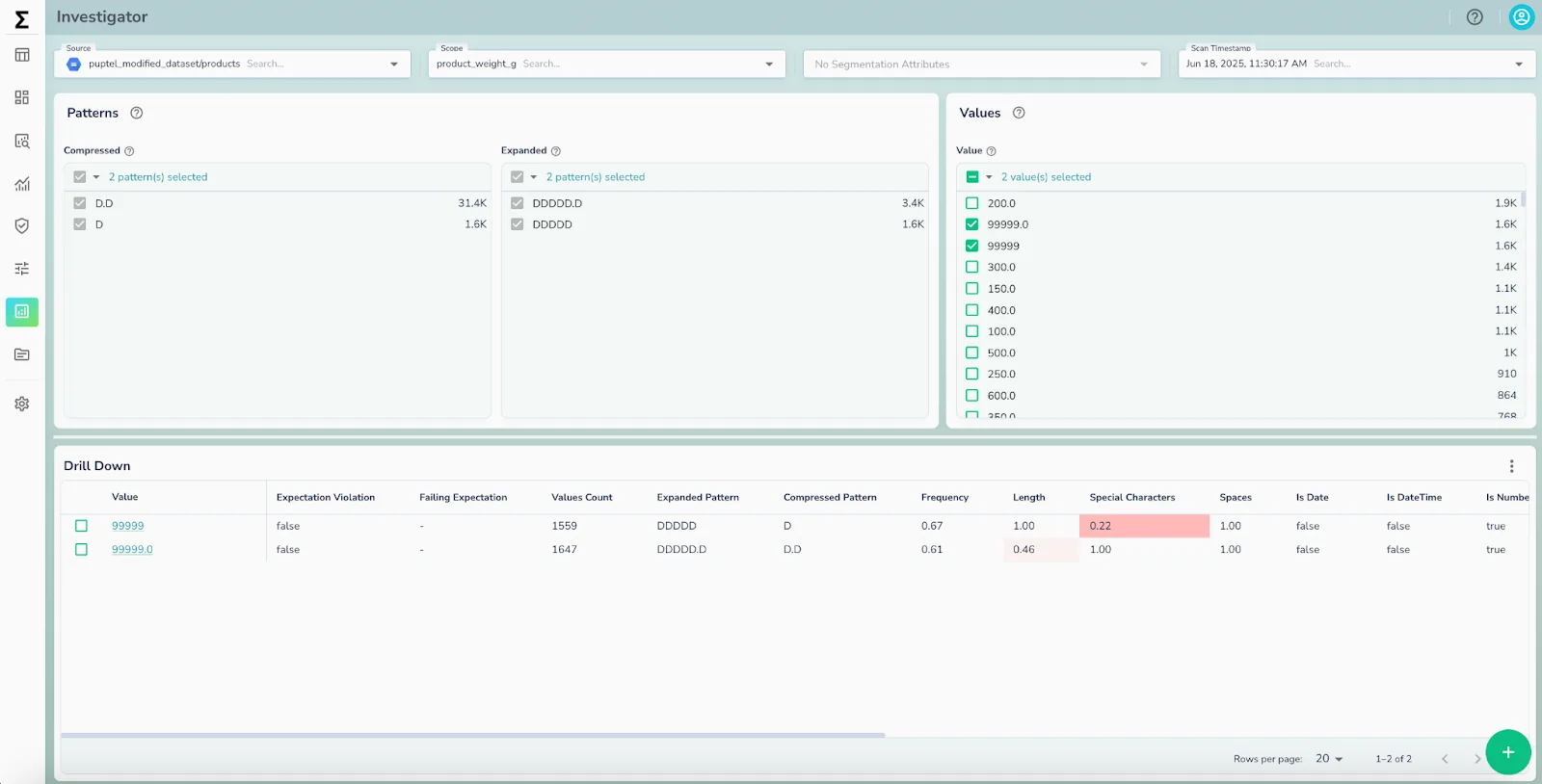
- Validation for freshness, completeness, conformity, and anomalies.
- Modeling (if needed) into marts or cubes, historically required for every new use case.
This is why the Lakehouse and open formats (Iceberg, Delta, Hudi) fundamentally change the game. In the old world, every new consumer meant another round of transfer → transform → model → consume—bespoke, brittle, and expensive.
With open formats:
- You dump/land once in the Lakehouse.
- You consume many times, across engines (SQL, ML, vector search) and contexts (BI dashboard, LLM, agent).
- You preserve lineage and metadata so every consumer knows not just what the data is, but how trustworthy it is.
This enables zero-copy, zero-ETL architectures—where data is queried in place, and pipelines are replaced by shared, governed access.
Models & Queries
Now that the Lakehouse addresses storage, movement, and transformation, responsibility shifts upward. The old world of pre-building marts and semantic models is giving way to runtime query and modeling.
- Agents, SQL, and ML/LLMs can dynamically model, filter, and query data at runtime.
- Runtime query engines (Trino, Spark, Fabric, Databricks SQL) enable federated, ad hoc queries across massive datasets.
- AI models themselves (LLMs and SMLs) can consume embeddings, metadata, and joins directly to answer questions or trigger actions.
- Analytical engines like PuppyGraph make complex graph queries over Iceberg tables feasible—without needing a separate graph database.
In short, the Lakehouse stabilizes the base, while agents and models provide runtime intelligence on top.
Context
If Data is the fuel and Models are the engine, Context is the navigation system. It ensures agents don’t just move fast, but move in the right direction.
- Provided Context: prompts, system instructions, agent-to-agent communication.
- Derived Context: metadata from lineage, governance, and semantics.
- Critical Context: runtime reliability signals (freshness, completeness, anomalies).
And this is essential because agents are, by definition, autonomous. With great power comes great responsibility—an agent empowered to act without context can cause more harm than good.
That’s why Telmai focuses here: enriching every dataset with reliability metadata. Agents don’t just know what to do—they know whether it’s safe to act.
4. Industry Alignment: The Lakehouse + Context Story
As enterprises adopt agentic AI, industry leaders are converging on a common foundation: Lakehouse architectures, open query engines, and context-rich catalogs. The direction is clear—data must be unified, governed, and contextualized before agents can act reliably.
- Microsoft (Fabric, OneLake & Purview): Unified storage and governance. Next Horizon → real-time trust signals for Copilot and Data Agents.
- Databricks (Delta + Unity Catalog): Open formats and metadata governance. Next Horizon → continuous reliability context for “Agentic BI.”
- Snowflake (Horizon): Governance and discovery. Next Horizon → runtime reliability metadata.
- GCP (Dataplex): Metadata-first governance. Next Horizon → embedded reliability checks across streaming.
- Atlan & Actian + Zeenea: Metadata lakehouse and hybrid catalog tools. Next Horizon → dynamic catalogs enriched with live trust signals.
Across all these ecosystems, the trajectory is clear: governance and semantics are rapidly maturing. The next horizon is weaving in a real-time reliability context.
5. Closing: Building Agentic Workflows on Trusted Data
The lesson is simple:
- The use cases (automation, efficiency, revenue growth, compliance) are compelling.
- The foundation (Lakehouse + engines/models + context) is non-negotiable.
- The pillars (Data, Models, Context) define the architecture.
- And the Next Horizon is context – especially derived reliability metadata that tells agents whether data is fit for use.
At Telmai, our product path is aligned with this future:
- MCP server to deliver AI-ready, validated data where agents operate.
- Support for unstructured data and NLP workflows, so agents can reason across PDFs, logs, and chat.
- Write–Audit–Publish + DQ binning to automate real-time quarantine of suspicious records.
This is how enterprises will scale agentic AI safely—by building on trusted, validated, context-rich data.
Because in the agentic world, it’s not enough for AI to be smart. It has to be confident.
Want to learn how Telmai can accelerate your AI initiatives with reliable and trusted data? Click here to connect with our team for a personalized demo.
Want to stay ahead on best practices and product insights? Click here to subscribe to our newsletter for expert guidance on building reliable, AI-ready data pipelines.