Ensuring data quality for data lakehouse Medallion architecture
Dive into the Medallion Architecture of Data Lakehouses and see how continuous data monitoring ensures integrity and reliability, transforming raw data into valuable business insights.

Introduction
In today’s fast-paced digital landscape, businesses are rapidly adopting modern data stacks and considering data lakehouses as the crux to efficiently manage vast volumes of diverse data. This shift allows organizations to store unstructured and structured data at scale, facilitating advanced analytics and insights that drive strategic decisions. Ensuring high data quality within these lakehouses is fundamental, as failure to validate data quality can lead to incorrect insights, resulting in strategic missteps, revenue losses, customer dissatisfaction, and even legal consequences in regulated sectors. On an operational level, poor data quality can cause inefficiencies and long latencies, underscoring the necessity of a balanced approach that combines people, processes, and technology to manage data quality effectively. Why incur the hefty costs of storing and transferring subpar data, which ultimately requires costly cleanup efforts? Prioritizing data quality from the outset can avert such unnecessary expenditures and streamline your data management workflow.
Let’s explore how it is ensured in Data Lakehouses. First, let’s quickly understand their unique architecture and its benefits.
What are data lakehouses?
A Data Lakehouse is a data architecture that combines the flexibility of data lakes with the robust structure and management capabilities of data warehouses. It is designed to store, manage, and analyze structured and unstructured data in a unified system, using open formats like delta parquet. This architecture allows organizations to leverage the best of both worlds — the schema-on-read flexibility of lakes and the schema-on-write efficiency of warehouses.
To learn more about the general outlook and components of data lakehouses, click here.
Several key characteristics distinguish the data lakehouse architecture:
- Unified Data Management: It eliminates the traditional boundaries between data lakes and warehouses, offering a consolidated view of all data assets.
- Cost-Efficiency: By leveraging low-cost storage solutions and optimizing query execution, data lakehouses reduce the overall expense of data storage and analysis.
- Scalability: The architecture effortlessly scales to accommodate growing data volumes and complex analytical workloads, ensuring that performance remains consistent as demands increase.
- Real-Time Analytics and AI: Data lakehouses enable direct analytics on raw and structured data, supporting advanced use cases like real-time decision-making and artificial intelligence applications.
Managing data quality within the Medallion data lakehouses architecture
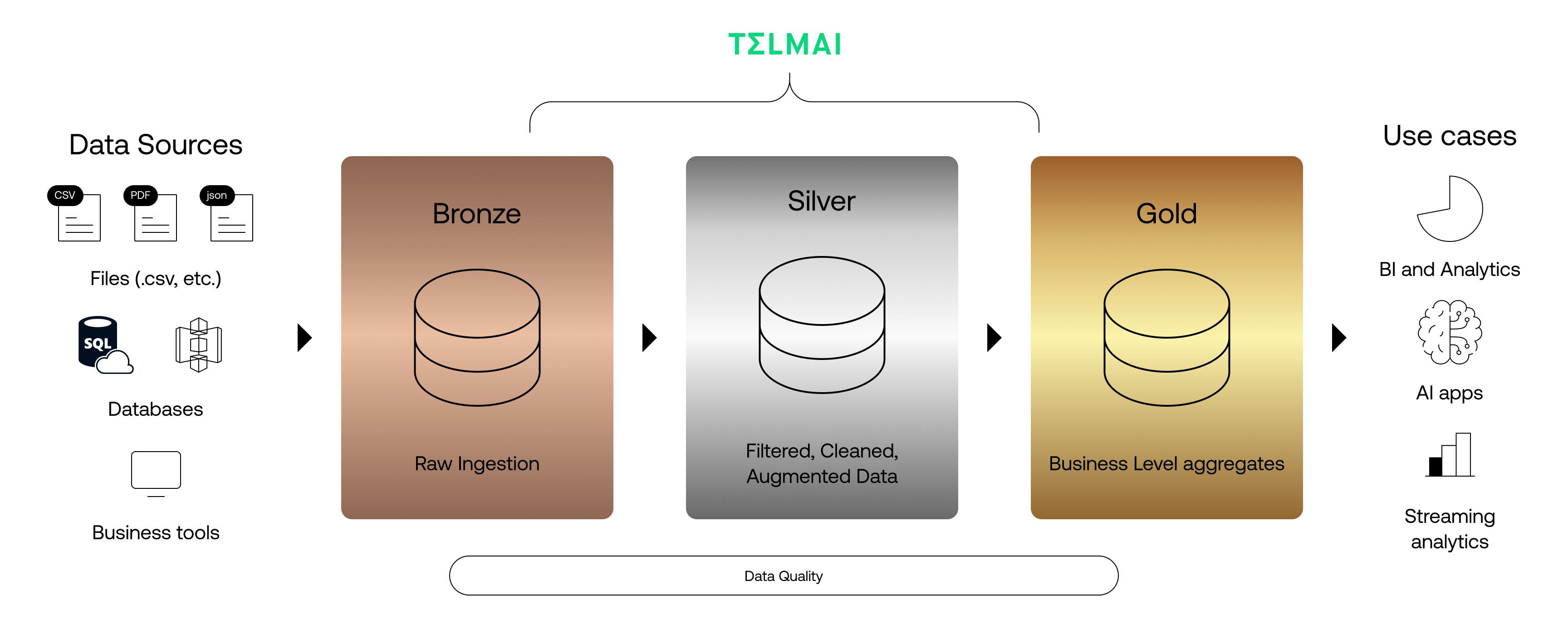
Medallion Architecture is a structured framework within the data lakehouse model, designed to organize data across three distinct layers: Bronze, Silver, and Gold. This tiered approach facilitates efficient data processing, management, and analysis, ensuring that data moves from raw form to analytics-ready with transparent governance and quality checks.
Monitoring various data workflows in a lakehouse
A data lakehouse serves as a single repository for vast volumes of data from multiple sources, including structured data like databases, semi-structured data like logs, and unstructured data like images, all stored together. Various workflows occur within a data lakehouse, each interacting with different systems and requiring data in specific schemas and formats. These workflows are essential for operations such as business intelligence, machine learning, and AI implementation.
The structure of your data can significantly impact how you manage and ensure its quality. While flat tables are straightforward to handle, semi-structured data with nested arrays requires more advanced tools and techniques to analyze and maintain. Using different tools to monitor each source separately is inefficient and complicated. Instead, having one tool that can oversee all types of data simplifies the process. This unified approach ensures consistent data quality across the entire lakehouse, making it easier to identify and fix any problems quickly.
Ensuring scalability in lakehouse data quality monitoring
A key advantage of modern data architectures, such as data lakehouses and data lakes, is the separation of storage from compute. This allows you to dynamically adjust your computing resources based on your data volume. This flexibility is essential for efficiently performing operations and various calculations, such as real-time analytics, machine learning model training, and data transformations, along with maintaining data quality, without compromising performance.
With a scalable and decoupled lakehouse, your data quality monitoring should also be scalable and adaptable to the changing dynamics of the data lake. As the volume and complexity of your data grow, your monitoring system must be able to scale accordingly. This ensures that your data quality remains high, providing accurate and reliable data for your business needs. By using a single, comprehensive tool that can automatically adjust to these changes, you can maintain consistent data quality across all data types and volumes, making it easier to identify and resolve issues promptly.
Before data is layered into the Medallion architecture, it first passes through critical Pre-Ingestion Data Quality Measures, ensuring foundational integrity as outlined in the following section.
Pre-ingestion data quality measures for source data
Data typically originates from a diverse set of systems, whether stored on-premises or in the cloud. It might be manually inputted through applications, supplied by third-party providers, or generated by machines. Proactively identifying and mitigating issues at the source can greatly enhance Mean Time To Detect (MTTD) and Mean Time To Resolution (MTTR), in some cases entirely preventing data quality issues from impacting end users.
To safeguard against the ingestion of substandard data into the data lakehouse, implementing data quality (DQ) rules at this stage is critical. These rules should ensure the data’s consistency (such as proper formats and valid value ranges) and completeness. Additionally, employing historical analysis and machine learning techniques to spot anomalies—or the so-called unknown unknowns—can predict potential data issues. This preemptive approach, requiring extensive integration capabilities to monitor various systems and sources, lays a solid foundation for maintaining high data quality throughout the data lakehouse’s subsequent layers.

Some examples of the Data Quality rules worth implementing at this layer include
- Accepted values list
- Values in the range from 0 to 100
- Dates in the format ‘M/d/yyyy H:mm’
- Dates within a range of 5 days from time of scan
Using statistical analysis or ML combined with time-series analysis might help identify situations like the disappearance or introduction of a new categorical value or a change in the distribution between them.
Most importantly, this should be provided in the form of simple UX so the Data Quality configuration and responsibility can be shared with teams outside of central Data Engineering, ideally application owners, to significantly increase the organization’s scale and ability to address problems in a timely manner.
A variety of out-of-the-box integrations, the ability to process any data (structured, semi-structured, encrypted, etc.), and low-effort Data Quality allow cross-functional teams and application owners to introduce and measure the quality of the data generated or onboarded by applications to scale the Data Quality effort across the organization and establish a first line of defense in the Lakehouse.
Bronze layer: the ingestion stage
The Bronze layer marks the entry point for all raw data into the lakehouse, serving as the foundational stage where data in its native form is stored. This layer accommodates a wide array of data from diverse sources such as logs, IoT devices, and transactional systems, channeling it into storage solutions like AWS S3, Google’s Cloud Storage, or Azure’s ADLS. At this stage, the data remains unprocessed, retaining its original state, which allows for the incremental addition of data in either batch or streaming form. It acts as a comprehensive historical record, capturing all collected information.
To uphold data integrity from the outset, enterprises must set up data quality checks to ensure the unprocessed data’s completeness, consistency, and accuracy. Such checks, often intrusive, are crucial for validating the technical aspects of the data pipeline, preventing data from moving to subsequent stages without meeting established quality criteria.
It’s also essential to ensure that all relevant data from the source systems is delivered and not lost in transit, and hence, it’s the right place to enable data difference checks.
Data owners, application owners, and data engineers are responsible for managing this critical layer. Collectively, they form the second line of defense in data quality assurance, ensuring that the data fulfills the quality requirements set by the lakehouse’s users. The tools they typically require include profiling, rules, and metric time-series anomaly detection.
Proactive monitoring, which can detect and alert on anomalies in established data patterns, data loss, and rule violations, plays a critical role at this layer. Being non-intrusive in nature, this can be combined with an intrusive approach when pipelines automatically stop, restart, or bad data is split from good data to further improve the velocity and reliability of the entire system while reducing pressure on the data engineering team.
Silver layer: the processing stage
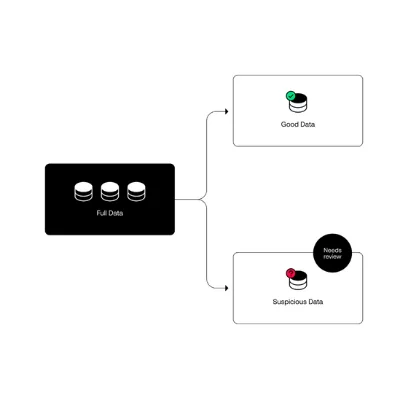
As we move up the Silver Layer, which is often omitted in practice, data is refined and enriched through cleansing, deduplication, joining, and other transformations. The primary goal at this stage is to refine the data, enhance its quality, and make it primed and ready for downstream usage.
Enriching data also has its own set of challenges, such as discrepancies in join keys or lookup values, underscoring the importance of monitoring completeness and uniqueness at the attribute level. As well as circuit breaker methods to isolate and prevent the influx of Bad Data into the Silver layer.
By effectively profiling and binning bad-quality data, cloud compute costs are reduced since this erroneous data will not be subjected to queries. Furthermore, this approach ensures that only reliable data progresses to the Gold layer, where it’s utilized for critical business insights. Hence, data quality binning, profiling, and circuit breaker methods not only mitigate the risks associated with poor data quality but also scale operational efficiency while keeping your cloud cost in check.
Gold layer: the analytics-ready stage
The Gold layer represents the pinnacle of the Lakehouse architecture, where data is transformed into clean data in business-ready formats. It accommodates a complex array of tables and pipelines designed for BI and reporting functionalities. Like the Silver layer, Data quality checks at this level concentrate on accuracy, consistency, completeness, and timeliness but in a much more business-specific form.
Since the data is already in the shape prepared for the consumers, i.e. business teams, the DQ rules are often owned by the same teams. To ensure the scalability of the solution, since the rules became very specific and at a large number, these teams should be able to modify, implement and monitor the performance of the rules without pushing it down to the central data engineering team. Some of the examples of the rules can be:
- Validate if “is_taxable” attribute is true, then “sales_tax” value is non-missing and above 0
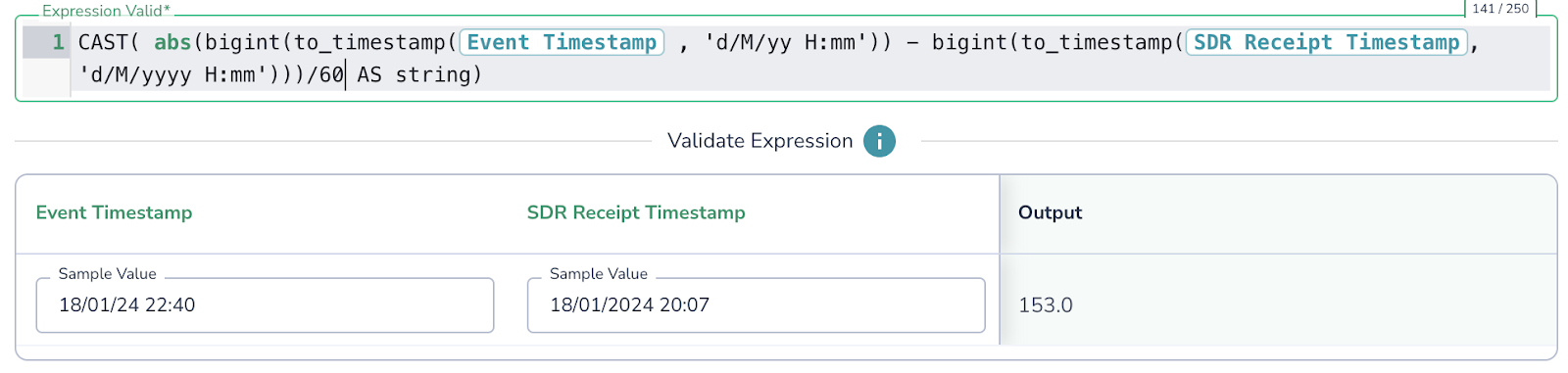
- Validate timestamp accuracy by measuring the difference between ‘Event Timestamp’ and ‘SDR Receipt Timestamp’ to ensure it falls within an acceptable range as depicted below.
To ensure accuracy of key reports certain specific business metrics, which are in essence aggregations grouped by key dimensions, must be evaluated for unexpected drifts and anomalies..
As the image below and general business scenarios demonstrate, these checks typically involve rules that track substantial variations in key business metrics. For example, they may verify that aggregated figures, like total volume of transactions broken down by their type, remain within a defined threshold (in this case a 10% range vs previous value) , maintaining consistent data trends over specified time frames.
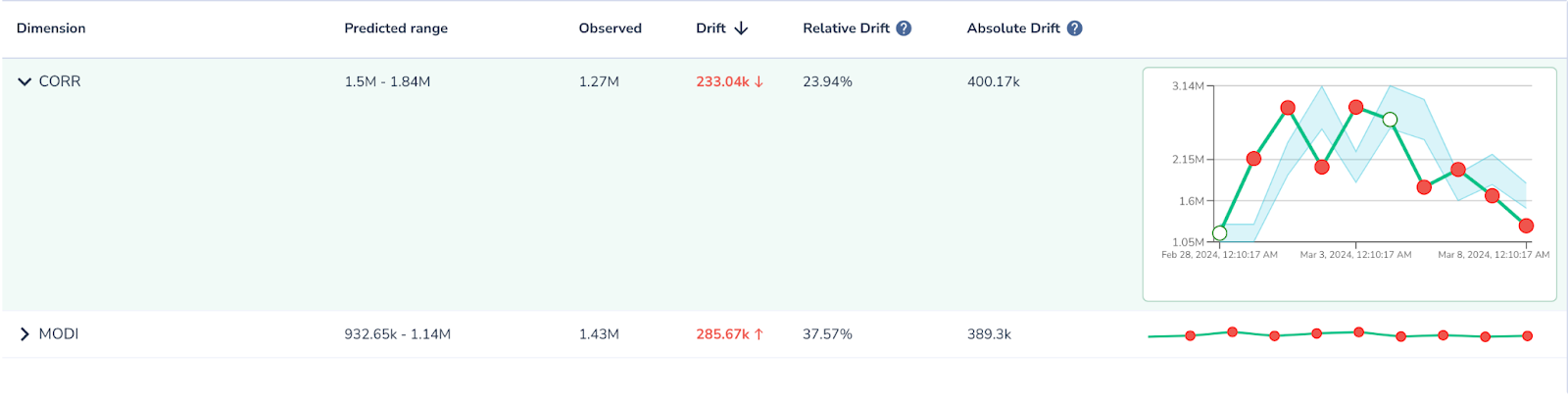
Data stewards play a crucial role in this stage, overseeing the integration of diverse sources and applying rigorous data quality standards.
Closing notes
To ensure that your data remains a valuable asset rather than a liability, remember that data quality management is an ongoing journey, not a one-time checkpoint. After establishing a solid framework and architecture, it’s crucial to continuously monitor, validate, and update to maintain data integrity. This iterative process ensures that your data ecosystem remains robust and trustworthy, empowering your decision-making with accurate and timely information.
Incorporating an advanced, machine learning-driven data observation tool becomes indispensable to harnessing the full potential of data lakehouses. AI-driven data quality monitoring would aid in predicting and preemptively tackling potential data quality issues. They enable users to easily track their data health using quality metrics and trace lineage to ensure the highest data integrity within Data Lakehouses.
Discover how such solutions can make your data ecosystem more dynamic and value-driven, enhancing operational efficiency and strategic insights.
Click here to talk to our Data Lakehouse expert about transforming your data management strategy.
Passionate about data quality? Get expert insights and guides delivered straight to your inbox – click here to subscribe to our newsletter now.
- On this page
See what’s possible with Telmai
Request a demo to see the full power of Telmai’s data observability tool for yourself.



