What’s a data lakehouse? Architecture, benefits & considerations
A data lakehouse seamlessly combines the scalability of data lakes with the organizational efficiency of data warehouses. Are they the solution you need where previous solutions fell short?


There’s undeniable value in storing vast quantities of data, but overwhelming challenges in harnessing it.
On one hand, data warehouses stumble when it comes to handling raw, unstructured, or semi-structured data that forms the bulk of today’s data ecosystem. Their structured nature, while conducive to analysis, is less flexible in accommodating the variety and velocity of modern data streams, leaving a gap between data collection and data insight.
On the other hand, the data lake emerged as a promising alternative, offering an expansive pool for storing data in its native format. The flexibility of data lakes to store unstructured data is unparalleled, but they often lack the governance, discoverability, and querying capabilities needed to transform that data into actionable intelligence efficiently.
This gap between the potential of vast data storage and the practicality of extracting value from it has led to a compelling innovation: the data lakehouse.
A data lakehouse combines the best of both worlds: the expansive, schema-on-read capabilities of a data lake with the structured, schema-on-write framework of a data warehouse. They provide a singular architecture that supports the diverse needs of data storage, management, and analysis without compromising on performance, scalability, or accessibility.
Let’s explore the critical components of data lakehouses that power their impressive capabilities.
The six layers of a data lakehouse architecture
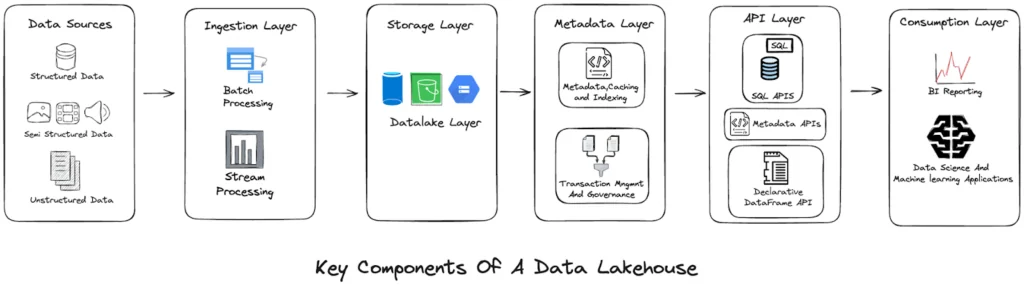
The architecture of a data lakehouse consists of six layers:
- Data Sources: This encompasses all varieties of data — structured (like databases), semi-structured (like JSON or XML files), and unstructured data (like text or images).
- Ingestion Layer: Responsible for bringing data into the system. It includes both batch processing (for large, accumulated data sets) and stream processing (for continuous, real-time data).
- Storage Layer: Acts as the repository for all ingested data. It includes a data lake layer that stores raw data in its native format.
- Metadata Layer: Provides a structure to the stored data through caching and indexing for faster retrieval, as well as transaction management and governance to ensure data integrity and compliance.
- API Layer: This is where the data is made accessible and usable. It includes SQL APIs for structured query language operations, metadata APIs for accessing data about the data, and declarative DataFrame API for more complex data structures.
- Consumption Layer: The final stage where data is utilized. It includes Business Intelligence reporting for analytics and visualization, as well as data science and machine learning applications that leverage the data for predictive models and algorithms.
Together, they form a comprehensive system for storing, managing, and analyzing data within a single, unified framework.
Lakehouses are often organized into a medallion architecture
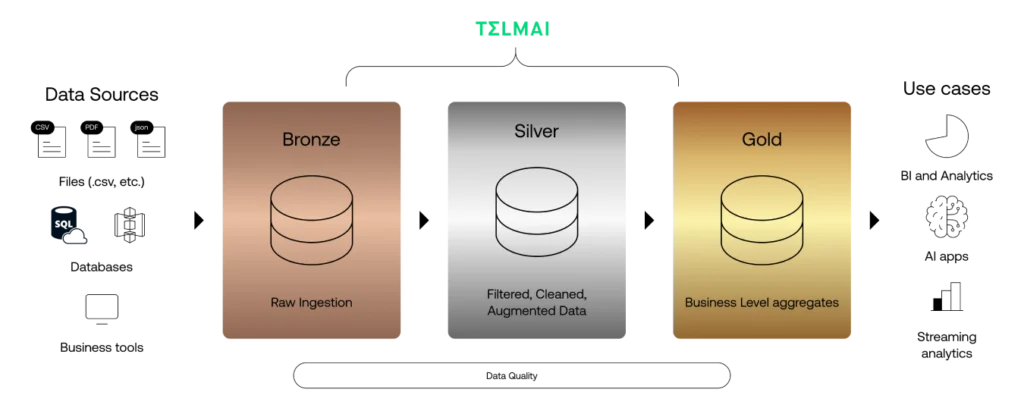
The medallion architecture describes a series of three storage layers – bronze, silver, and gold – denoting the data quality stored in the lakehouse. Popularized by Databricks, this architecture guarantees atomicity, consistency, isolation, and durability as data passes through multiple layers of validations and transformations before being stored in a layout optimized for efficient analytics. The terms bronze (raw), silver (validated), and gold (enriched) describe the quality of the data in each of these layers.
For organizations using Delta Lake, it’s a good idea to use Telm.ai with your Delta Lake as an integrated solution to improve data quality management, ensuring reliable use across all storage layers.
Benefits of a lakehouse architecture
By leveraging a lakehouse, organizations can seamlessly combine the scalability of data lakes with the organizational efficiency of data warehouses, with benefits like:
- Organized and Validated Data: A lakehouse provides robust mechanisms to ensure that data is not only stored in an organized manner but is also validated, which helps maintain the quality and integrity of data across the organization.
- Efficient Data Pipelines with Incremental ELT: It supports efficient data pipelines that enable incremental Extract, Load, and Transform (ELT) processes, reducing the time and resources needed to prepare data for analysis.
- Easy to Understand and Implement: The architecture is designed to be intuitive, simplifying the complexities of data management so that it’s easier for organizations to understand and implement.
- Can Recreate Your Tables from Raw Data at Any Time: One of the standout features is the ability to recreate tables from raw data whenever needed. This provides tremendous flexibility in handling and manipulating data without the risk of losing the ability to revert to the original data state.
- ACID Transactions: Lakehouse architectures support ACID (Atomicity, Consistency, Isolation, Durability) transactions, ensuring that all database transactions are processed reliably, and data integrity is maintained even in complex, multi-user environments.
- Time Travel: The “time travel” feature enables users to view and revert back to earlier versions of data, which is invaluable for audit purposes and when dealing with accidental data deletions or modifications.
Ensure data quality in your data lakehouse by pairing it with Telmai
As the advantages of a data lakehouse become increasingly clear— secure, organized storage with efficient processing—the necessity for impeccable data quality comes sharply into focus. This is where Telmai’s data observability platform plays a crucial role.
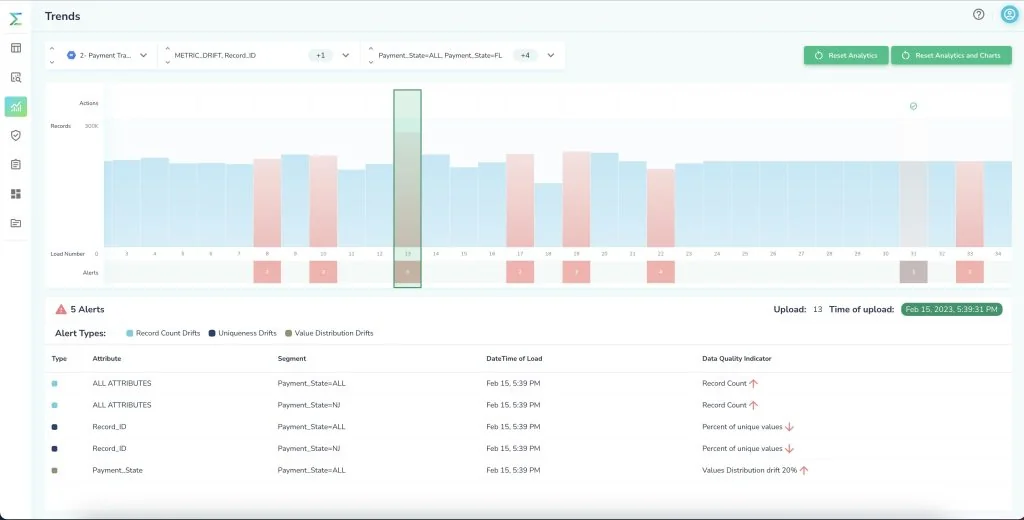
By seamlessly integrating with each layer of the lakehouse’s medallion architecture, Telmai ensures that data quality is not an afterthought but a foundational element. It provides the tools to monitor and validate data at every step, from source to consumption, reducing cloud costs and preventing the ingestion of subpar data.
Moreover, Telmai equips businesses to enact cost-effective data management strategies, such as the circuit breaker pattern, which halts the flow of questionable data, and DQ binning, which isolates potential issues in an economically sensible manner.
With the goal of making data not just available but reliably actionable, Telmai positions organizations to extract the maximum value from their lakehouse investment, affirming that data-driven decisions are based on the highest standard of data quality. Request a demo today.
Passionate about data quality? Get expert insights and guides delivered straight to your inbox – click here to subscribe to our newsletter now.
- On this page
See what’s possible with Telmai
Request a demo to see the full power of Telmai’s data observability tool for yourself.



