There’s a difference between encouraging your team to use AI and rebuilding your engineering process around it. Most leaders do the first. We did both at Telmai.
Here’s what that looks like.
Encouraging Is Easy. It’s Also Not Enough.
We started where most teams start. “Try the tools. Experiment. See what sticks.” A few engineers adopted quickly. Most kept working the same way.
The gap wasn’t motivation. It was structure and process.
When AI tools are optional, engineers use them for the obvious low-risk tasks: generating sample data, writing a script, drafting a commit message. Useful. Not the shift you’re looking for.
Our co-founder and CTO, Max, and I spent a day feeding our product docs, UI screenshots, and notes into an AI and asked it to rebuild a simplified version of our application. It didn’t build everything. But the UX thinking it produced, and the small details it surfaced that our own team had been missing, were jaw-dropping. It also pointed us toward simplifying features we already had. A day of work. More product clarity than we’d gotten in months of sprint planning.
That’s when we decided optional wasn’t working. We had to rebuild around it.
How Adoption Actually Happened
We didn’t flip a switch. We ran a deliberate phased path.
Phase 1 was low-risk and isolated: sample data generation, CLI helpers, small standalone changes. Low stakes, fast feedback. This is where skeptics start seeing the point.
Phase 2 was harder. We rearchitected parts of the codebase carrying too much accumulated debt for AI to navigate effectively, and started building medium-sized features agent-first. We accepted that some code needed to be rebuilt. Not because it was broken. Because it was structured in a way that made it opaque to AI.
Phase 3 is where we are now: major features, built agent-first from the start.
We’re there now. Full end-to-end features, design through testing, built agent-first. That’s not the goal anymore. That’s the baseline.
30% Of The Team Pushed Back. That Was The Right Response
The objections were specific: it hallucinates too much, it doesn’t understand our existing codebase, and I don’t trust what it outputs.
These aren’t wrong. They’re accurate observations about where AI breaks down. We didn’t argue with them. However, we gave those engineers something more useful than a counter-argument: protected time to work through those limitations on real features, not toy examples.
We also accepted that removing technical debt wasn’t a side project. A messy codebase is hard for humans to navigate. It’s worse for AI. Some of what we rearchitected wasn’t about code quality. It was about making the codebase legible enough for AI to reason about it.
The skeptics converted when they saw the output. Not when we made the case for AI.
The Numbers
Our team went from 0% AI-assisted code to 80-90%. Velocity gains range from 5-6x on legacy code to over 10x when the stack is built AI-native from the start. The difference is the codebase, not the AI. We’re pushing toward 100% AI-assisted. Not there yet, but that’s the target.
A core deployment architecture change we had been deferring for two quarters got done in a day. That was the moment the team stopped debating whether this was real.
What Actually Changed
It didn’t change how many engineers we need. It changed what we need from them.
The engineers moving fastest aren’t the ones with the deepest technical expertise alone. They’re the ones who think clearly about what to build, care about what it actually solves for the customer, and can direct AI to get there.
That shows up in how we work now. A feature isn’t just a ticket anymore. It’s a well-written prompt, clear acceptance criteria, and enough context for the AI to reason about intent. The engineers who can write that well ship faster than the ones who can’t.
The question we ask now isn’t “how much can this engineer produce?” It’s “how much value can this engineer drive?” Those aren’t the same question. For a long time, we treated them like they were.
The New Bar
The best engineer on my team today isn’t the one writing the most code. It’s the one who can own a full feature: understands the problem, defines the outcome, and directs AI throughout the process. That scope used to require a team. Now it doesn’t. The bar has moved.
The shift is there for any team willing to make it. Encouragement is the easy path. Rebuilding is the harder one. We chose the harder one. The difference is measurable.
For years, data quality has been framed as a reporting problem. Analysts review dashboards, business leaders ask questions, and when something looks off, someone investigates. That model worked when data was primarily consumed by humans.
In a recent webinar, Max Lukichev, CTO and Co-founder at Telmai, and Saravana Omprakash, Co-founder at DataColor AI, made a compelling case that this approach is fundamentally broken in the age of agentic AI.
Enterprise data usage has fundamentally changed. Data is no longer accessed by a small set of known consumers on a periodic basis. It is now used broadly, continuously, and often autonomously by AI agents embedded across workflows.
This shift alone breaks most traditional data quality models. But it also forces a deeper question. If machines are acting on data directly, what does it actually mean to trust that data?
That question sits at the center of the 2026 data quality blueprint.
Why the Old DQ Playbook Fails in the Agentic Era
The classic data quality model evolved around business intelligence. Data was curated, aggregated, and periodically reviewed through reports. In practice, this meant rule-heavy frameworks that validated tables at the end of the pipeline, typically in the data warehouse. If an issue surfaced, teams had time to investigate, add a rule, and move on.
But agentic AI has shattered that predictability. As Max put it bluntly during the discussion, “Now everyone is building agents, right? You have nearly everyone on a team building something to address a narrow task. The impact of these agents is much broader, given their access to data. You kind of don’t even know how this data is being used, by whom, what decisions are being made.”
Saravana captured another dimension of this failure: many organizations respond by scaling rules instead of strategy. “One of the things I’ve observed is that organizations take a very table-schema focused approach,” he explained. “They say, ‘I’ve got 20 schemas, I’ve got 500 tables—let me run 2000 rules on top of them,’ instead of asking what’s actually important for the business.”
This shotgun approach to blanket rules across every table in the warehouse misses the forest for the trees. It’s reactive, expensive, and ultimately ineffective because it treats all data as equally important. But as both speakers emphasized throughout the conversation, you cannot boil the ocean.
In an agentic environment, data quality can no longer be reactive. Once an agent has acted on bad data, the damage is already done.
From Table-Centric Rules to Business-Centric Trust
So what does a business-first approach look like?
Saravana articulated a principle that became a throughline in their discussion. “What I have seen successfully implemented as DQ initiatives that can translate into business outcomes has been the fact that taking a KPI-first, or a metric-first kind of data quality approach,” he explained. “Because it is not about whether I’ve got the right rules. It is about whether those rules align with your business outcomes. That way, you’re focused with your energies on trying to look for the checks that need to be done on that entire pipeline of the data that matters.”
Once those questions are answered, data quality becomes purposeful. Checks are no longer generic. They are aligned to business impact. When something breaks, teams know why it matters, who it affects, and what needs to happen next.
Max reinforced this idea from a different angle. In complex enterprise environments, trying to validate everything equally is not just inefficient; it is impossible. This business-first, KPI-aligned approach enables the next shift in the blueprint. Rules alone are not enough. Observability is critical for detecting issues as they emerge, often before explicit rules are in place. Changes in volume, distribution, freshness, or structure can be identified early, without writing thousands of downstream checks.
As Max emphasized, “You cannot boil the ocean. You cannot solve it everywhere. You have to identify and isolate areas where it has the most impact.” What works instead is a decision-first approach:
Identify the KPIs, metrics, and decisions that actually matter
Trace the data paths that feed those decisions
Focus quality, observability, and governance efforts there
This reframes data quality from a volume problem to an impact problem. You don’t need perfect data everywhere; rather, you need trustworthy data where decisions are made. In an agentic world, that prioritization becomes essential. You simply cannot afford to monitor everything equally, nor should you try.
Why Observability Must Shift Left
With the business context established, the conversation turned to architecture: where in the data pipeline should quality checks actually live?
By the time data reaches the warehouse, it has already passed through ingestion, transformations, joins, and aggregations. Simple upstream issues, like schema drift or missing records, are often masked by these layers, leaving teams with fewer signals and more complex failures to debug.
Shifting observability left fundamentally changes the economics of data quality. As Max explains, “The earlier you plug observability into the pipeline—closer to ingestion—the more proactive it becomes. Those simple problems can be detected automatically before transformations hide them. Otherwise, you only have one choice left: writing more rules downstream.”
At the raw data layer, anomalies are easier to detect automatically. A sudden drop in record count or an unexpected schema change at the landing zone takes minutes to detect and investigate. The same issue, discovered three transformations later and buried in aggregated warehouse tables, might take hours or days to trace back to its source. This upstream approach reduces the need for an ever-growing library of downstream rules while enabling teams to act before bad data propagates. The data speaks for itself if you’re listening at the right place.
Saravana expanded on the strategic value of this upstream approach, particularly when combined with lineage tracking. “The lineage view of basically the entire pipeline and incidents that are being tracked at the observable data being observed upfront on the left-hand side could also be a very good way to do root cause analysis of things that happen on the right-hand side.”
But Max emphasized that shift-left doesn’t mean abandoning rules entirely. “You cannot get rid of rules completely. You cannot implement rules everywhere. It requires balance, and you need to bring a lot of observability concepts upstream to the ingestion layer, but you also don’t want to overextend yourself and start monitoring where it doesn’t matter or where the impact is less.”
Saravana summarized this as moving from snapshot-based validation to continuous monitoring. Not just catching issues earlier, but avoiding reactive firefighting altogether.
Trust Scores: Making Data Quality Consumable by AI
Humans are remarkably good at working around imperfect data. They notice trends, ask follow-up questions, and apply intuition. Saravana drew an analogy that crystallized the concept: “It’s like basically taking a diagnostic test on somebody and you have a reference range and you basically have your score to say you are healthy, you’re not healthy.”
“In this new era where data is being used by AI, by AI agents, by ML workloads that are basically taking it without providing objective ways of measuring whether the data is trustworthy or not in a consistent way, on an ongoing basis,” Saravana continued, “these machines will find it difficult to consume and provide reliable answers.”
Max grounded this abstract concept in a concrete example to highlight that the stakes escalate when you automate, which many finance teams would immediately recognize. “Imagine now you have agents that automate these processes for you, automatically paying vendors, automatically making some decisions. If they go unchecked, you can get in big trouble.” This is the fundamental risk of agentic AI: autonomous action exponentially amplifies the impact of data errors.
Max emphasized that trust scoring is at a level of granularity that traditional DQ never contemplated. “The trust scores are now at the record level. It’s not that my table looks good, because now you are taking actions based on individual elements, like individual records, customers, vendors, whatever. So you have to evaluate all of this data at much finer granularity, calculate those trust scores, highlight potential issues, and stop agents from doing something they were not supposed to do to avoid all of those compliance problems.”
This record-level scoring transforms data quality from a passive health check into an active input for decision-making. An agent doesn’t just retrieve a vendor’s payment information—it also receives a trust score indicating whether the record is reliable enough to act on. If the score falls below a threshold, the agent can escalate to human review rather than blindly executing a potentially erroneous transaction.
The 2026 Blueprint: Continuous, Contextual, and Consumable
Saravana crystallized the modern data quality blueprint into three essential characteristics that differentiate it from legacy approaches.
It is continuous, not snapshot-based
It is context-aware, aligned to business decisions
It is machine-consumable, designed for AI systems — not just humans
In AI-native environments, detecting a data issue isn’t enough. The real challenge is how quickly teams can understand the impact, identify the root cause, and take corrective action, often across multiple systems.
This is where modern data approaches converge, integrating:
Data observability
Lineage
Incident context
AI-assisted analysis and remediation
Instead of relying on institutional knowledge scattered across teams, AI systems can now reason over this context, suggest fixes, and even automate parts of the resolution process with humans staying in the loop where it matters. Data quality becomes part of an execution fabric, not a reporting layer.
Building Trust as Infrastructure
As enterprises race to deploy agentic AI across all domains, the organizations that succeed will be those that recognize a simple but profound truth: the agent is only as good as the data behind it.
In the world of autonomous systems making real-time decisions, trust is infrastructure. It must be continuous, contextual, and consumable by the very systems that depend on it. Building that infrastructure requires rethinking data quality from the ground up.The question for most enterprises isn’t whether this transformation is possible, but how quickly they can execute it before their AI initiatives outpace their data quality foundations.
At Telmai, this blueprint directly informs how we approach data quality in AI-native environments.
Rather than treating data quality as a downstream control, our focus is on establishing trust early—at the ingestion layer of the data lake
Extending quality and observability beyond structured tables to unstructured inputs like documents, logs, and conversations
DQ patterns that can surface, isolate, and contain issues before autonomous systems act on them
This is how enterprises will scale agentic AI safely by building on trusted, validated, context-rich data.
Because in the agentic world, it’s not enough for AI to be smart. It has to be confident. Click here to speak with our team of experts to learn how leading enterprises are building trusted data foundations for agentic AI.
As Agentic AI adoption accelerates, the industry conversation is shifting from “Can we build AI?” to “Can we trust it?”
In the latest episode of our Data Quality podcast series, Telmai’s CEO and co-founder, Mona Rakibe, joined Ravit Jain, Alex Merced, and Scott Haines to explore how open lakehouse architectures are becoming foundational for sustainable Agentic AI infrastructures. They also highlighted critical considerations for architecting agentic infrastructures where autonomous systems and workflows don’t just analyze data, but act on it in a deterministic and trusted manner.
“Agentic-Ready” Starts With Reliable Contextual Data
“Agent-Ready” data isn’t something entirely new, it’s simply well-prepared data elevated for a new level of responsibility. Yet as AI systems evolve from analytical to autonomous, the stakes rise dramatically.
“At the end of the day, all AI is doing is understanding your data just faster,” said Alex Merced, Head of Developer Relations at Dremio. “It’ll get to the right answer faster or the wrong one faster, depending on your data quality. That means everything we’ve always cared about, accuracy, cleanliness, and semantic definitions, now matters a lot more.”
Mona Rakibe expanded on this idea, “The biggest mental shift is understanding that for agents to be truly autonomous, the data powering them must be reliable and enriched with context. It’s no longer enough to have dashboards; the data pipeline itself needs to be self-healing and self-validating.”
This shift is fundamental, as agents interact dynamically with data across diverse domains, demanding real-time observability and proactive governance. Scott Haines echoed this sentiment, noting how teams are “giving up control” to automated systems, which makes the need for guardrails and testable context even more urgent. “You have to ensure your workflows behave predictably, that’s what makes the difference between a trusted agentic ecosystem and one that’s just automated chaos,” he said.
Building “AI-ready” or “agentic AI-ready” data isn’t just about accuracy, it’s about real-time reliability and contextual awareness. Systems must now deliver machine-consumable metadata, continuous validation, and semantic consistency at the speed of automation. In this world, data trust isn’t an afterthought, it needs to be baked into your data infrastructure.
Open Lakehouses: The Foundation for Trusted and Autonomous AI
If the first step toward Agentic AI is reliable contextual data, the next is an open architecture that makes that trust accessible across every system, use case, and engine. As Mona Rakibe put it, today’s enterprises are moving toward a model where “everything lives in one lake,” but the engines and intelligence around that data are increasingly decoupled and composable.
“Historically, we used to ETL data, model it, and make it fit for purpose for every single use case,” she explained. “Now, what I’m seeing is a shift toward standardized open formats — Iceberg, Delta, Hudi — where data can be dumped into a lake and processed as-is. The models themselves are smart enough to handle JSON or XML, so the transformation moves closer to the use case. That’s where zero-ETL and zero-copy architectures are becoming real.”
Alex Merced expanded on this, noting that the goal isn’t to eliminate data movement entirely, but to reduce redundancy and preserve context throughout the pipeline. “Even if you standardize on Iceberg or Delta,” he said, “you still need to move data between systems. But the transformations themselves can become more logical or virtual. That’s why semantic layers are getting so much attention. Instead of physically transforming data, you engineer meaning over it.”
This architectural evolution, from closed, pipeline-heavy data systems to open, semantically aware ecosystems, enables AI agents to operate with both context and consistency. It ensures that the rules, lineage, and quality signals that define trusted data travel seamlessly, regardless of where or how the data is consumed.
Scott Haines, who leads developer relations at Buf, added another dimension to this openness: data contracts embedded directly into schemas.“At Buf, we created something called Proto Validate,” he explained. “It lets you embed those data contracts right inside your schema definitions, basically adding guardrails at the edge, before data even enters the lake.”This “edge validation” approach ensures that governance begins at ingestion, not after a failure has already propagated downstream. It’s a natural complement to the metadata-driven validation Mona advocates for and the semantic standardization Alex envisions.
Open lakehouses aren’t just about flexibility or performance, they’re about trust at scale. By embracing open formats, shared semantics, and embedded contracts, data teams can finally align what humans understand and what AI agents act upon. In the era of Agentic AI, interoperability becomes the new reliability, and the open lakehouse serves as the foundation for both.
Metadata, MCP, and the Headless Future of Data Quality
If open lakehouses provide the foundation for trust, metadata is what animates that trust in real time. As AI agents begin to interact directly with enterprise data, the challenge isn’t just validating accuracy it’s making validation context available instantly, wherever and whenever agents need it.
Mona Rakibe explained this shift clearly: “Unstructured data has now become a first-class citizen. The moment a PDF or a JSON file enters a pipeline, its validation becomes critical,” she said. “That validation context must also be accessible through an MCP — the Model Context Protocol — because when agents query data, they need to know which records can be trusted and which should be excluded.”
In her view, MCP represents the next evolution of interoperability, serving as a universal protocol that enables AI systems to access not only data but also its context, quality, and provenance in a standardized manner. “It’s almost like REST for AI,” Mona noted. “Everything now has to be accessible to the agent in a standardized format. It’s no longer optional.”
This real-time exposure of metadata marks the beginning of what she called the “headless data quality era.” In this model, validation isn’t something performed within a UI or a tool; it becomes an invisible, autonomous service that continuously surfaces reliability signals across every workflow, both human and machine.
“Data quality needs to become a headless application,” Mona said. “We need to get the context out as soon as data lands, make it part of the MCP so agents can operate on it. That’s the only way to make autonomous systems truly reliable.”
Alex Merced agreed, adding that headlessness isn’t limited to data quality, it’s transforming the entire data stack. “We’re walking into a world where application building is less about designing a user interface and more about building functionality,” he said. “MCP enables that. It decouples how we interact with systems from how those systems actually run.”
Scott Haines tied this back to governance and predictability, reminding that decentralization doesn’t mean disorder. NLP and automation enable teams to manage distributed quality responsibilities without compromising coherence, but metadata must remain the unifying thread. “In a world where agents can run checks and feed that context back into workflows, governance becomes a living process,” he observed — one that’s both autonomous and explainable.
Together, these ideas signal a dramatic transformation: metadata is becoming the interface between humans, machines, and trust. Headless data quality, powered by MCP, ensures that every system, from an LLM querying customer data to an autonomous workflow reconciling transactions, has access to the same trusted, contextual truth.
From Reactive Pipelines to Autonomous Systems
For years, data quality was defined by dashboards, alerts, and manual intervention systems that reacted after something went wrong. However, in an era where AI agents process data in real-time, reactive monitoring can no longer keep pace. Enterprises now need self-governing, self-healing data ecosystems that detect, diagnose, and resolve anomalies autonomously.
Mona Rakibe described this as the natural endpoint of the shift Telmai itself has been preparing for.“We’re moving toward a world where data quality becomes autonomous,” she said. “Nobody loves doing DQ work, and that’s exactly what makes it the perfect candidate for automation. The system should be able to detect drifts, understand patterns, and correct itself without waiting for human approval.”
That autonomy, however, doesn’t mean a loss of control,it means redefining control. The goal isn’t to replace human oversight, but to embed intelligence within the data fabric, making trust continuous and invisible. In this future, metadata, lineage, and validation signals form a living feedback loop that constantly informs both human decisions and AI reasoning.
Alex Merced explained how this evolution changes the way teams build and interact with systems.“We’re walking into a world where application building is less about designing a user interface and more about building functionality,” he said. “With MCP and headless validation, the system itself becomes the interface. The agent can query, interpret, and act — and the data quality layer ensures it does so responsibly.”
The move toward autonomous trust systems also brings a cultural transformation. Teams must start designing for proactive reliability, not just reactive response. Instead of tracking SLAs and resolution times, success will be measured by how seamlessly systems prevent incidents altogether, by design, not by repair.
In the context of Agentic AI, this evolution isn’t optional; it’s existential. As workflows become more distributed and decisions become more automated, the only sustainable model is one where data quality operates as an autonomous, intelligent service that detects context, adapts to drift, and reinforces trust without human bottlenecks.
Ultimately, this is where observability meets agency. The systems that once monitored data will now reason about it, closing the loop between awareness and action, and transforming trust from a static KPI into a continuously orchestrated state.
Democratizing Data Quality in the Agentic Era
As architectures evolve and data quality becomes autonomous, one challenge persists: who owns trust? For years, organizations have swung between centralized governance and decentralized accountability, both with their trade-offs. Centralization brought standardization but lacked context; decentralization gave teams control but often led to inconsistency.
Mona Rakibe captured this tension perfectly.“Initially, data quality was centralized, which nobody liked — the people who owned it didn’t have the context. So we tried to decentralize. But then the teams who had the context struggled with SQL or with using yet another tool. Data quality wasn’t part of their KPIs; they just wanted to build and ship products.”
Her point underscores a reality that many enterprises face: data quality can’t thrive as an isolated function. It must live within the workflows where data is produced and consumed. And with the rise of natural language interfaces and AI-powered validation, this is finally becoming possible. “Decentralization is possible today because of NLP,” Mona added. “We can make quality checks accessible through simple prompts, allowing agents and business users to participate without deep technical knowledge.”
Scott Haines described this as “governance that lives where work happens.” Instead of forcing teams to adopt new tools, observability and validation flow directly into existing workflows — Git commits, notebooks, orchestration platforms, or even chat-based agents. The result is ambient governance: always present, rarely intrusive, and fully traceable.
The broader implication is that trust itself becomes decentralized, but discipline stays centralized.Central teams define the rules, while distributed teams enforce and improve them through automated systems. NLP and agentic validation create a collaborative loop in which humans guide intent, and systems ensure consistency.
Closing Thoughts: Trust Is Your Data Moat
In the rush to operationalize Agentic AI, it’s easy to focus on compute power, model accuracy, or prompt engineering. But as every enterprise soon discovers, the true differentiator isn’t intelligence, it’s integrity.
Agentic AI doesn’t just consume data; it inherits its flaws. In an autonomous ecosystem, even a minor inconsistency can amplify into a systemic failure. That’s why building trust as infrastructure is no longer optional. From contextual validation to open lakehouses, from metadata-rich MCP layers to headless observability, every architectural decision now shapes how confidently your systems can operate independently.
As enterprises design for autonomy, this trust fabric becomes their most enduring moat. It’s what enables AI agents to reason responsibly, what gives teams confidence in automation, and what allows innovation to scale without fear of fragility.In the end, trust isn’t a checkpoint in the pipeline, it’s the currency of intelligent systems. The organizations that invest in reliable, contextual, and explainable data today will be the ones defining how AI behaves tomorrow.
Want to learn how Telmai can accelerate your AI initiatives with reliable and trusted data? Click here to connect with our team for a personalized demo.
Want to stay ahead on best practices and product insights? Click here to subscribe to our newsletter for expert guidance on building reliable, AI-ready data pipelines.
Telmai, the AI-powered data observability platform, today announced its Agentic offerings to make enterprise data truly Autonomous-Ready. These new capabilities ensure agentic AI workflows can communicate, decide, and execute actions on real-time trusted data with minimal human oversight.
Agentic AI significantly changes the requirements for how organizations manage their data and thus their data quality (DQ). Because Agentic AI requires low-latency and real-time access to validated data, it’s imperative that data quality happens right at the source, not downstream, where most companies focus their DQ efforts today.
But validation alone isn’t enough. AI agents also need to understand whether data is truly fit for purpose in the context of their actions. This involves delivering contextual information about data health as metadata into catalogs and semantic layers that AI agents can access.
Only when trust and context are combined can AI agents operate responsibly and enterprises deploy them with real confidence.
Telmai has the unique ability to continuously validate, monitor, and enrich data with quality signals at the lake and can push that data quality metadata for consumption by agents. This creates the trusted foundation that autonomous AI products need to operate reliably and at scale.
With Telmai’s latest product launch, AI agents can continuously access reliable data and the critical data quality context needed to automate downstream workflows.
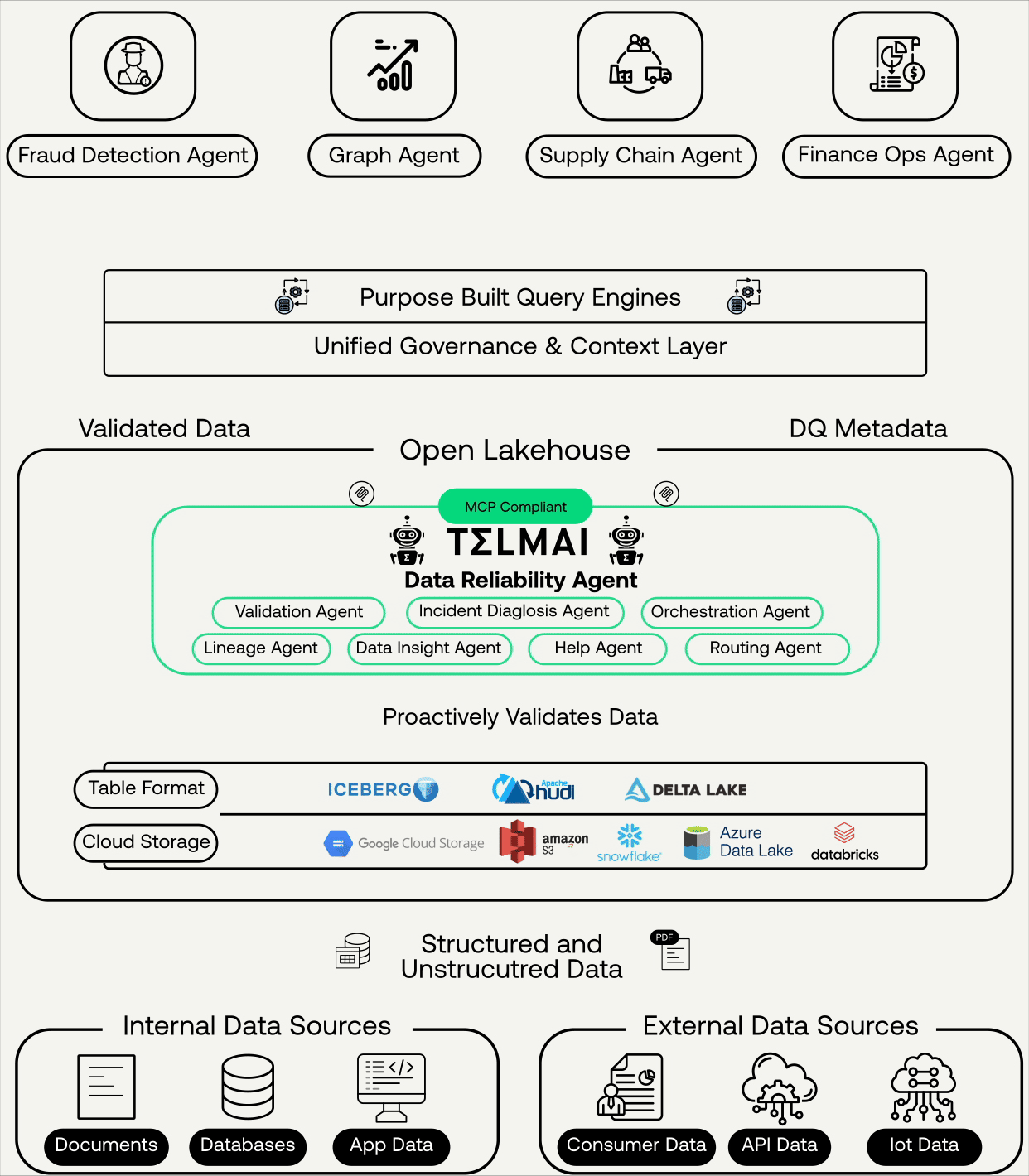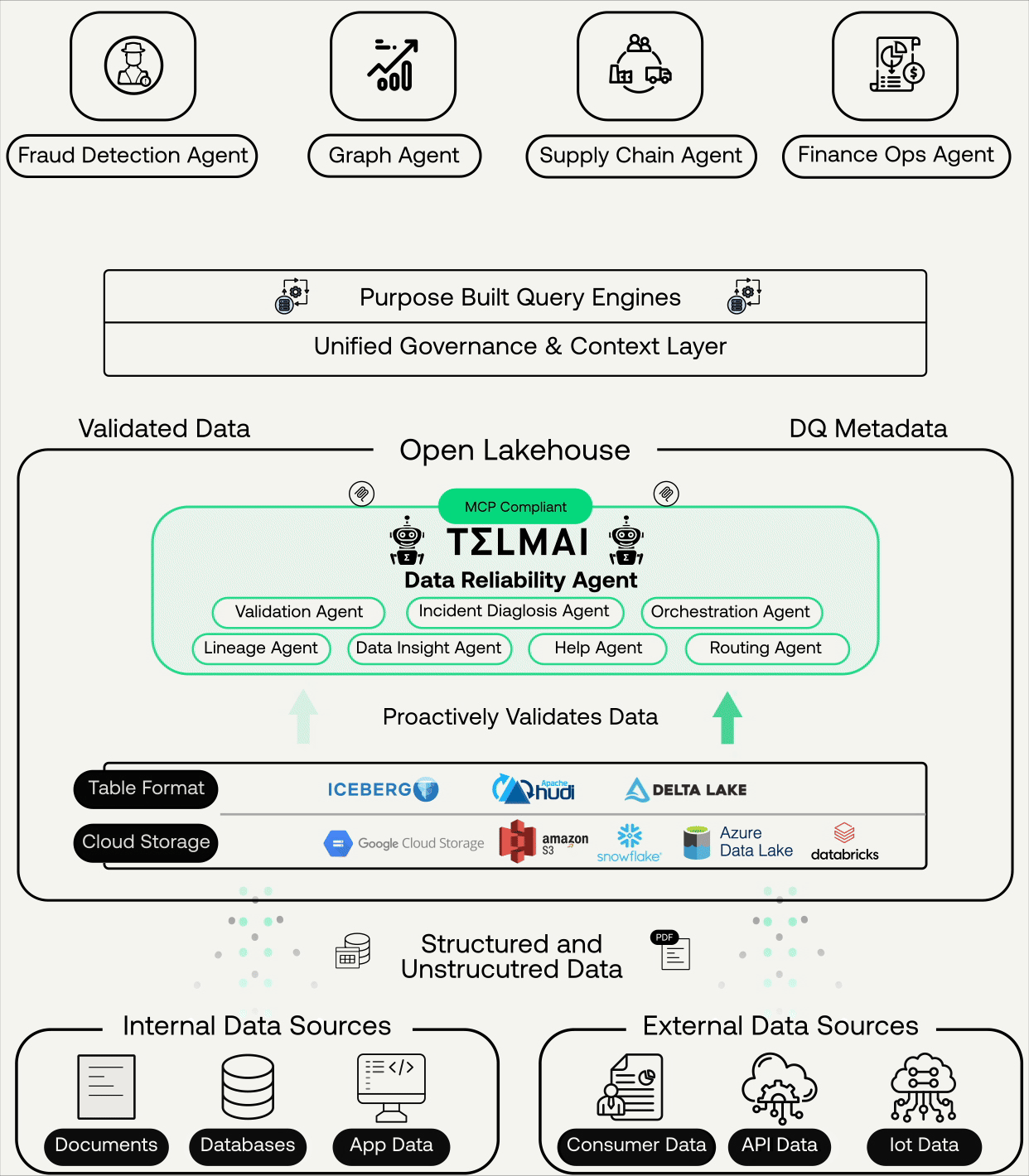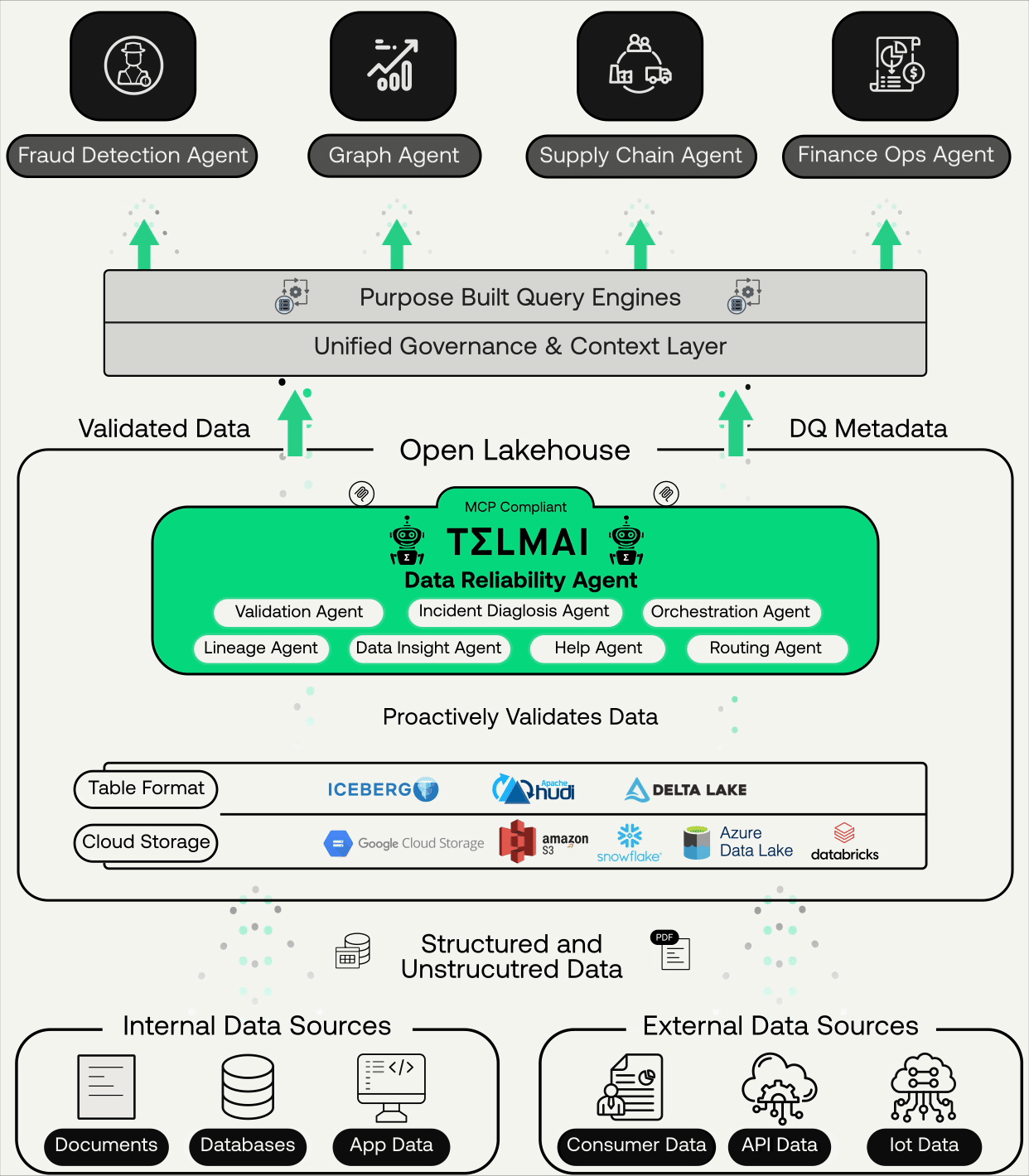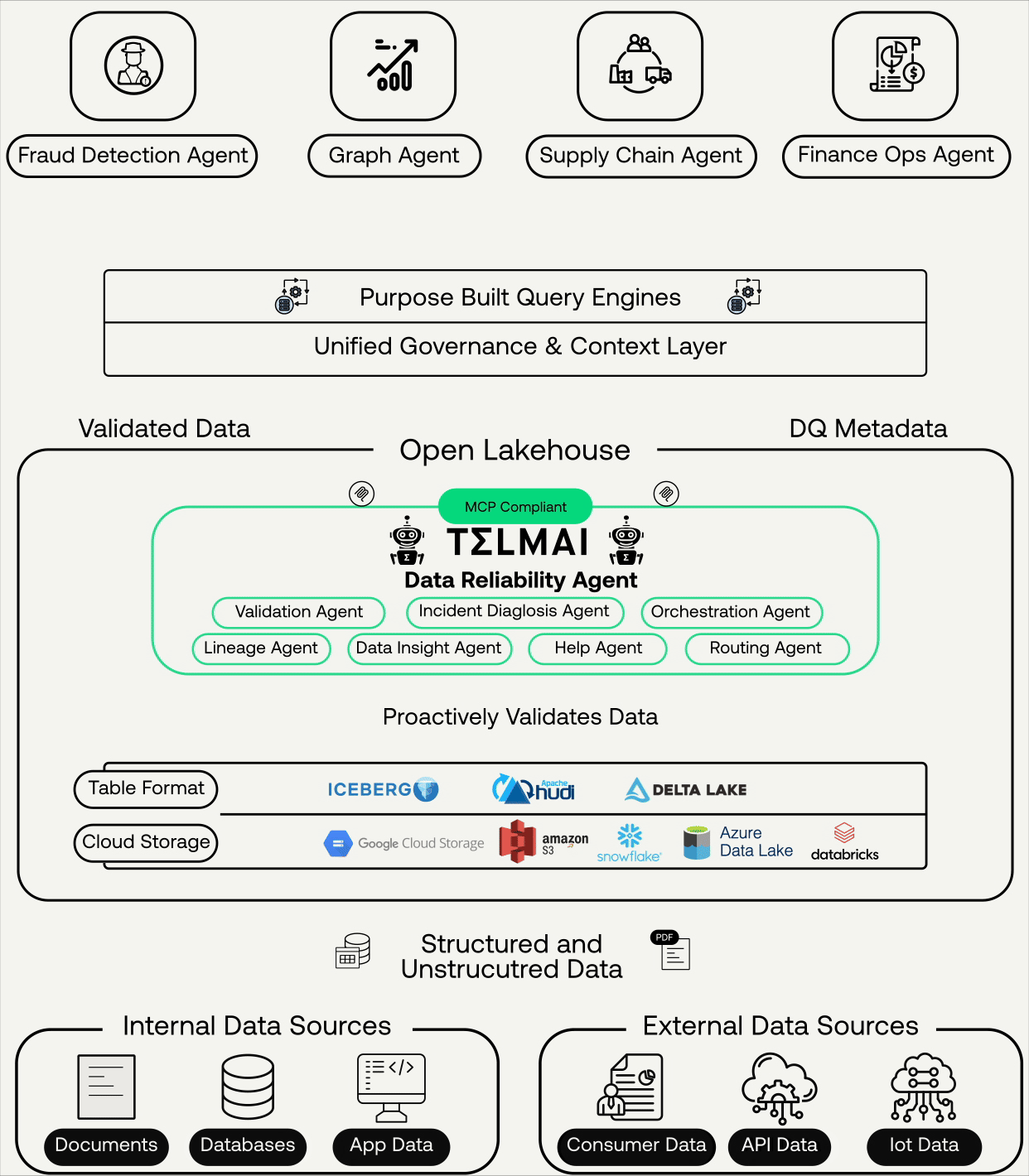
Real-Time, Continuous, Agentic AI-Ready Data
Telmai’s Data Reliability Agents ensures continuous validation, context, and governance across open lakehouses
At the core of this update is the introduction of Telmai’s MCP-compliant server, which enables LLM-powered agents like Claude, Bedrock, or Vertex to query Telmai directly. Telmai continuously validates data, whether structured, semi-structured, or unstructured. Additionally, it generates comprehensive data quality metadata alongside the validated data, providing essential context on data health to ensure the data is reliable and AI-ready. Through the MCP layer, AI agents can access and retrieve validated data and metadata into their agentic workflows, eliminating the need for third-party transformations or complex workarounds.
“In the era of model commoditization, true competitive advantage will emerge from trustworthy, dynamic, and contextually aware data,” said Sanjeev Mohan, industry analyst and principal at SanjMo. “Telmai’s latest release is a big step in this process. It offers continuous validation and contextual metadata that enable AI agents to act responsibly, while reducing the operational debt that has long hindered enterprise adoption.”
Natural Language AI Assistants & Decentralized Data Trust
Building on this foundation, Telmai is introducing a suite of AI assistants called Data Reliability Agents accessible through natural language interfaces, enabling both technical and non-technical users to interact directly with the platform. This decentralization means that ownership of data reliability no longer sits solely with engineering, accelerating time to value by making platform management and critical data quality insights accessible and actionable to all relevant stakeholders.
Autonomous Detection and Remediation
Telmai’s Data Reliability Agents enable autonomous detection and resolution of data anomalies. These intelligent agents continuously monitor data pipelines for irregularities and provide clear, plain-language explanations of root causes. Identifying and resolving complex data quality issues that once required deep technical expertise are now easily understood and addressed by both technical and business teams. Beyond detection, the Data Reliability Agents provide actionable recommendations and assist in generating data quality rules tailored to newly identified anomalies.
Furthermore, these Data Reliability Agents augment existing automated workflows, such as ticket creation and alert triggers, to help data teams proactively adapt and drive continuous improvement in their data quality processes.
This comprehensive approach closes the loop from detection through triage and remediation, ensuring that data being fed into the downstream processes is not only trustworthy but consistently ready for autonomous consumption and decision-making.
“As AI agents take the reins of decision-making, we believe autonomy should never come at the cost of reliability,” said Mona Rakibe, Co-founder & CEO of Telmai. “With these updates, Telmai is laying the groundwork for true intelligent automation and allowing enterprise data teams to shift their focus to driving measurable business value via Agentic AI.”
For more information or to learn more about Telmai’s Data Reliability Agents, request early access today.
Want to stay ahead on best practices and product insights? Click here to subscribe to our newsletter for expert guidance on building reliable, AI-ready data pipelines.
In my last post, I shared why enterprises need autonomous, agentic workflow–ready data. But knowing why is only half the story. The next question is: what does it actually take to build agentic AI workflows in the enterprise?
The answer starts with business ROI, but it only succeeds if underpinned by the right technology foundation. Let’s understand this journey.
1. Start with Business ROI: Use Cases That Matter
The promise of agentic AI is not abstract; it’s about hard ROI measured in hours saved, costs reduced, compliance improved, and revenue accelerated. Enterprises that embed AI-driven agents into their workflows are already reporting significant returns.
For example:
Operational Efficiency & Automation Omega Healthcare implemented AI-driven document processing to handle medical billing and insurance claims at scale. The results: 15,000 hours saved per month, 40% reduction in documentation time, 50% faster turnaround, and an estimated 30% ROI. 👉 Read more
Labor Reduction & Productivity Gains In accounts payable, agentic automation is now capable of managing up to 95% of AP workflows—covering exception resolution, PO matching, fraud detection, and payments—dramatically reducing manual overhead. 👉 See details
Topline Revenue Growth & Cash Flow Optimization A mid-sized manufacturer deploying AI invoice automation cut manual effort by 60% and reduced invoice approval cycles from 10 days to just 3 days. This improved supplier satisfaction while accelerating cash flow—a direct driver of topline agility. 👉 Learn more
Trust & Compliance A South Korean enterprise combined generative AI with intelligent document processing for expense reports, cutting processing time by over 80%, reducing errors, and improving audit compliance—while the system continuously learned from user feedback. 👉 Case study
The business ROI is clear. But ROI only materializes if the technology foundation is strong.
2. The Technology Foundation for Agentic AI
Agentic AI requires more than just a clever model. It needs a robust stack that ensures agents act on data that is accurate, fresh, and explainable. Without this, automation becomes brittle, outputs are untrustworthy, and scaling to new use cases is nearly impossible.
As a founder, I can’t help but see the parallel to building a company. Every wise founder, investor, or YC advisor repeats the same lesson: scaling before product–market fit is risky. You can grow fast in the short term, but without nailing the fundamentals, you eventually hit a wall.
The same is true for AI: scaling before nailing is risky. And here, what needs to be nailed is data infrastructure and AI infrastructure.
You can launch impressive AI pilots, but without reliable data and context, failures show up quickly—hallucinations, inconsistent outputs, compliance gaps.
By investing first in the foundation—valid, explainable, governed data pipelines—you enable AI to scale safely and accelerate into new use cases with confidence.
The foundation determines how fast and how far you can grow.
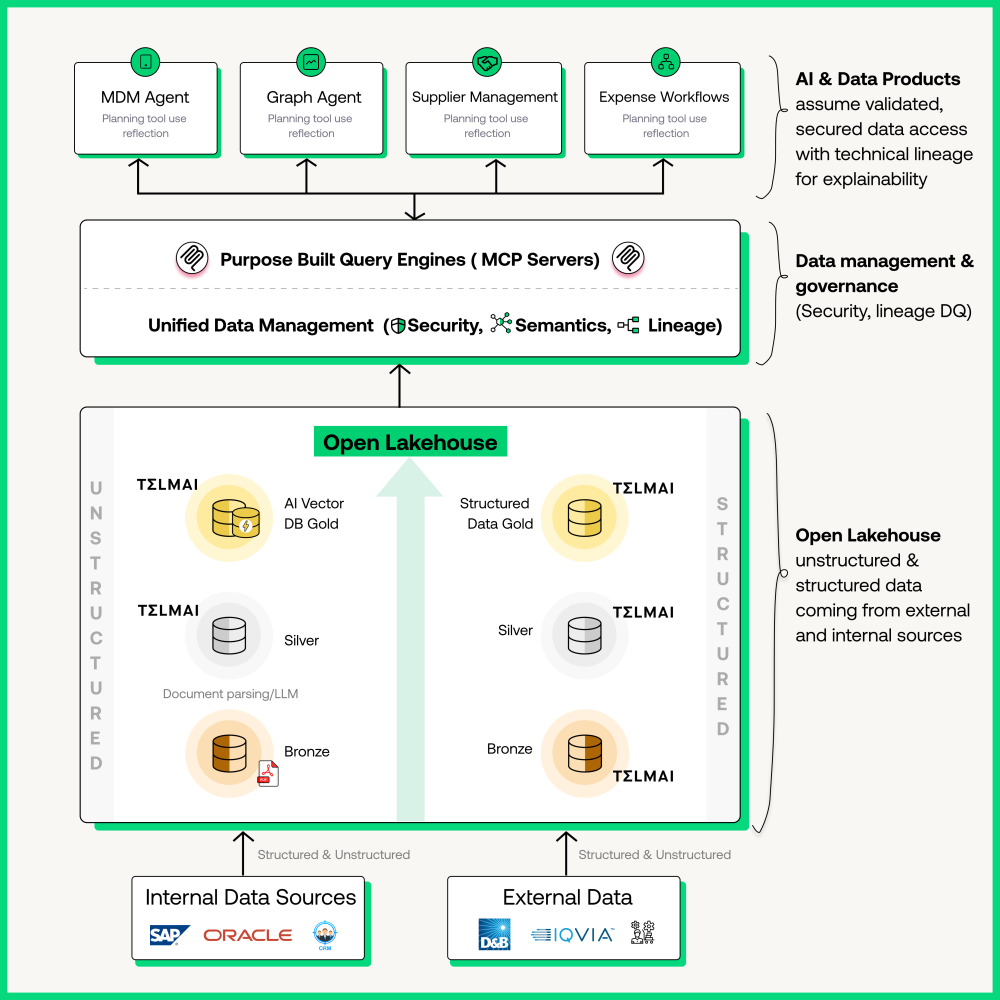
At the heart of this foundation is the Lakehouse architecture. Why? Because agentic workflows rely on low-latency access to both structured and unstructured data, and the Lakehouse unifies both in open formats like Iceberg, Delta, and Hudi.On top of this foundation, enterprises layer:
Purpose-built query engines (Trino, Spark, proprietary engines) that allow federated access to diverse sources.
A context layer: governance, lineage, semantics, and—critically—data quality signals.
Just as startups succeed by nailing the core before scaling, AI succeeds by nailing its data and infrastructure foundation before attempting ambitious, agentic workflows.
3. The Three Pillars of Agentic AI Technology
When you strip it down, the technology requirements for agentic AI come down to three pillars: Data, Models, Queries, and Context.
Trusted data + lakehouse architecture + context signals = the foundation for agentic AI.
Data
Data is not just about landing rows in a table—it spans the entire lifecycle:
Storage in scalable, cost-effective object stores (S3, ADLS, GCS).
Transfer across batch or streaming pipelines.
Access & Discovery through catalogs and metadata systems.
Querying for analytics, training, or real-time decisioning.
Validation for freshness, completeness, conformity, and anomalies.
Modeling (if needed) into marts or cubes, historically required for every new use case.
This is why the Lakehouse and open formats (Iceberg, Delta, Hudi) fundamentally change the game. In the old world, every new consumer meant another round of transfer → transform → model → consume—bespoke, brittle, and expensive.
With open formats:
You dump/land once in the Lakehouse.
You consume many times, across engines (SQL, ML, vector search) and contexts (BI dashboard, LLM, agent).
You preserve lineage and metadata so every consumer knows not just what the data is, but how trustworthy it is.
This enables zero-copy, zero-ETL architectures—where data is queried in place, and pipelines are replaced by shared, governed access.
Models & Queries
Now that the Lakehouse addresses storage, movement, and transformation, responsibility shifts upward. The old world of pre-building marts and semantic models is giving way to runtime query and modeling.
Agents, SQL, and ML/LLMs can dynamically model, filter, and query data at runtime.
Runtime query engines (Trino, Spark, Fabric, Databricks SQL) enable federated, ad hoc queries across massive datasets.
AI models themselves (LLMs and SMLs) can consume embeddings, metadata, and joins directly to answer questions or trigger actions.
Analytical engines like PuppyGraph make complex graph queries over Iceberg tables feasible—without needing a separate graph database.
In short, the Lakehouse stabilizes the base, while agents and models provide runtime intelligence on top.
Context
If Data is the fuel and Models are the engine, Context is the navigation system. It ensures agents don’t just move fast, but move in the right direction.
Provided Context: prompts, system instructions, agent-to-agent communication.
Derived Context: metadata from lineage, governance, and semantics.
And this is essential because agents are, by definition, autonomous. With great power comes great responsibility—an agent empowered to act without context can cause more harm than good.
That’s why Telmai focuses here: enriching every dataset with reliability metadata. Agents don’t just know what to do—they know whether it’s safe to act.
4. Industry Alignment: The Lakehouse + Context Story
As enterprises adopt agentic AI, industry leaders are converging on a common foundation: Lakehouse architectures, open query engines, and context-rich catalogs. The direction is clear—data must be unified, governed, and contextualized before agents can act reliably.
Microsoft (Fabric, OneLake & Purview): Unified storage and governance. Next Horizon → real-time trust signals for Copilot and Data Agents.
Databricks (Delta + Unity Catalog): Open formats and metadata governance. Next Horizon → continuous reliability context for “Agentic BI.”
Snowflake (Horizon): Governance and discovery. Next Horizon → runtime reliability metadata.
GCP (Dataplex): Metadata-first governance. Next Horizon → embedded reliability checks across streaming.
Atlan & Actian + Zeenea: Metadata lakehouse and hybrid catalog tools. Next Horizon → dynamic catalogs enriched with live trust signals.
Across all these ecosystems, the trajectory is clear: governance and semantics are rapidly maturing. The next horizon is weaving in a real-time reliability context.
5. Closing: Building Agentic Workflows on Trusted Data
The lesson is simple:
The use cases (automation, efficiency, revenue growth, compliance) are compelling.
The foundation (Lakehouse + engines/models + context) is non-negotiable.
The pillars (Data, Models, Context) define the architecture.
And the Next Horizon is context – especially derived reliability metadata that tells agents whether data is fit for use.
At Telmai, our product path is aligned with this future:
MCP server to deliver AI-ready, validated data where agents operate.
Support for unstructured data and NLP workflows, so agents can reason across PDFs, logs, and chat.
Write–Audit–Publish + DQ binning to automate real-time quarantine of suspicious records.
This is how enterprises will scale agentic AI safely—by building on trusted, validated, context-rich data.
Because in the agentic world, it’s not enough for AI to be smart. It has to be confident.
Want to learn how Telmai can accelerate your AI initiatives with reliable and trusted data?Click here to connect with our team for a personalized demo.
Want to stay ahead on best practices and product insights? Click here to subscribe to our newsletter for expert guidance on building reliable, AI-ready data pipelines.