Every enterprise that adopts and builds on AI today faces the same invisible problem. The models are good. The agents are capable. Somewhere upstream, a pipeline is quietly delivering data that should never have reached production.
The failure does not announce itself. There is no crash, no error code, no alert from the system that just acted on three days of drifted values. The agent reasons fluently on what it receives and produces outputs that look coherent, feeding into business decisions. Someone eventually notices a demand forecast that is consistently off. A customer cohort that stopped reflecting reality. They trace it back. The data was broken the whole time. The agent never knew.
This is what “garbage in, garbage out” looks like in an agentic system. Not obviously wrong. Precisely, silently wrong. And the gap between when it started and when anyone found out is where the real damage lives.
Agents Consume Anomalous Data With the Same Confidence As Clean Data
Every data team has someone who just knows. This individual knows the pipeline that feeds the board dashboard ran late last Tuesday, and the numbers need a second look before they go anywhere important. He or she knows the revenue table that finance actually trusts is not the one marked as the official source of record. This individual knows when a volume looks thin, when a distribution has shifted, and when something passed validation checks but should not have. That instinct took years to build. It lives entirely in her head.
An AI agent has access to the same tables, schemas, and catalog entries. What it does not have is any of that instinct. It cannot smell when something is off. It will consume anomalous data with exactly the same confidence it consumes clean data, because from its position, there is no visible difference.
This is where the failure modes that data teams actually hit in production come from.
A pipeline delivers 15% of its expected row volume. The agent builds a downstream forecast based on a statistical fragment and does not flag the input as unusual because nothing in its context indicates the volume is wrong. A column is silently renamed in an upstream schema change. The agent maps null values across thousands of records, treats them as meaningful, and produces outputs that are structurally coherent but semantically broken. A training distribution shifts as upstream sources evolve, and the model continues extrapolating from a pattern that no longer exists in the data it is consuming.
In each case, the agent proceeds. A data engineer reviewing the same input would have stopped. The agent does not stop because it has no quality signal indicating that it should. And by the time a business stakeholder surfaces the anomaly, the agent has already acted on that data hundreds of times across every downstream system it touches.
Anomaly Detection At the Access Layer Is Structurally Too Late for Agentic Pipelines
When data teams discover this problem, the standard response is more monitoring downstream. Quality dashboards. Anomaly reports. Stewards are assigned to review signals after the pipeline completes. This approach was designed for a BI world and it fails entirely in an agentic one.
Autonomous systems do not run one query and wait. They make thousands of micro-decisions per second, each one reading from the same tables that a downstream dashboard has not yet flagged. The interval between ingestion and detection is not a gap you can engineer away at the monitoring layer. It is structural. And in an agentic pipeline, everything that happens inside that interval is already done by the time any downstream signal fires.
Late-stage detection was a tolerable delay when a broken dashboard was a contained incident that a data steward could fix before the next reporting cycle. In an agentic architecture, a broken signal at ingestion is a cascading event. The damage does not sit in one place waiting to be found. It propagates silently through every downstream system the agent touched before anyone knew to look.
The fix cannot live downstream. It has to move to where the data is born.
A Quality Signal That Does Not Reach the Context Layer Does Not Exist for the Agent
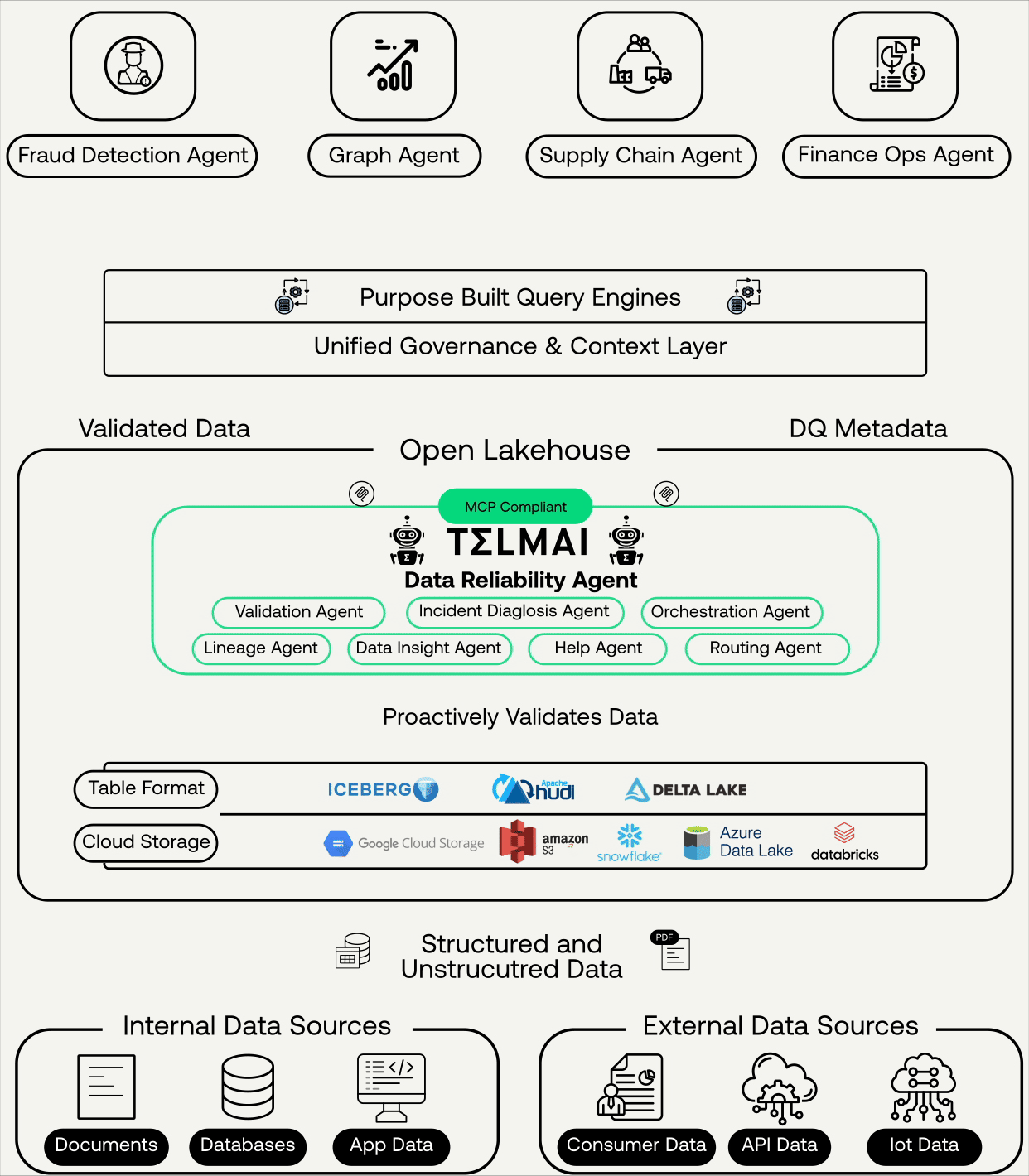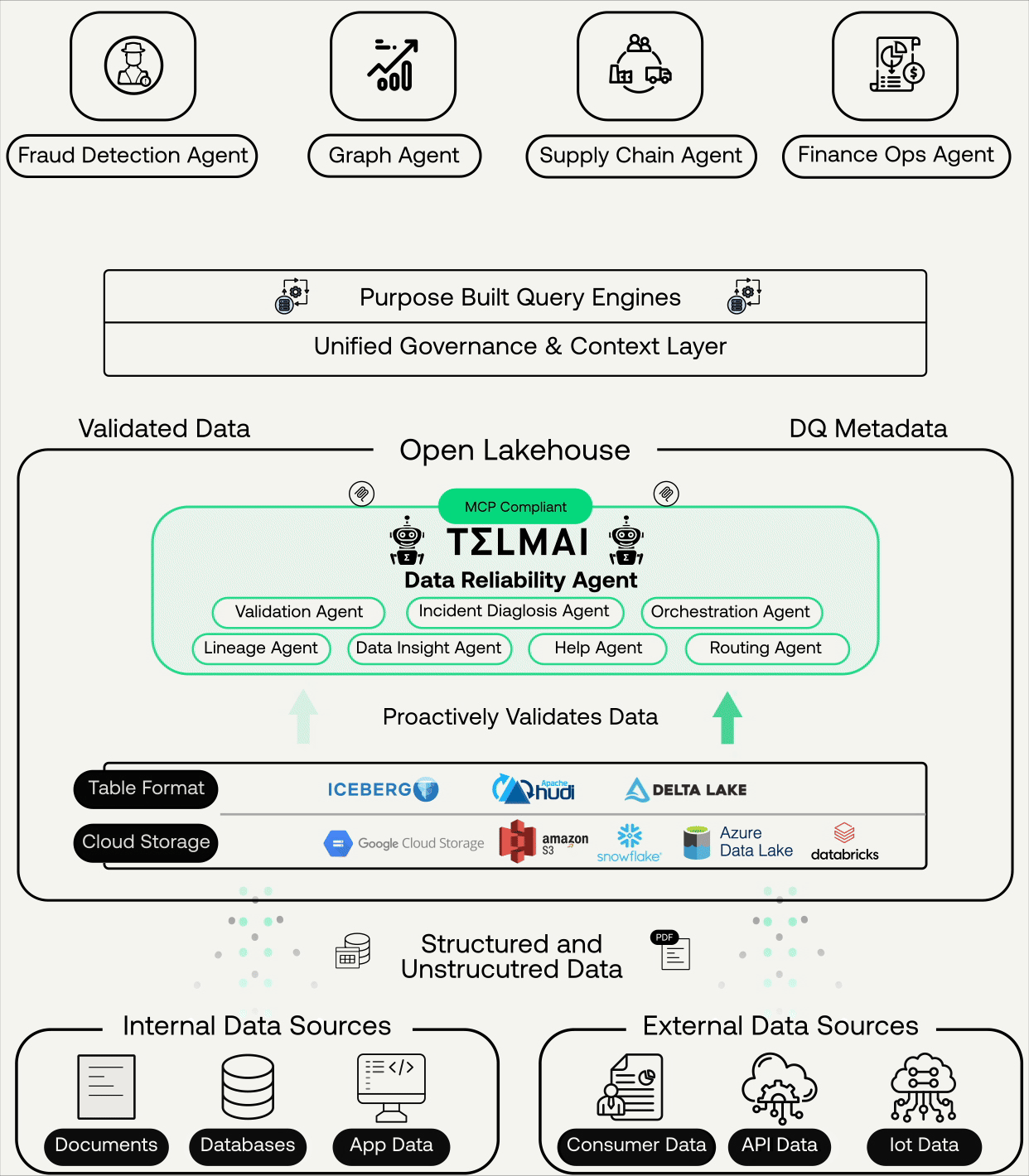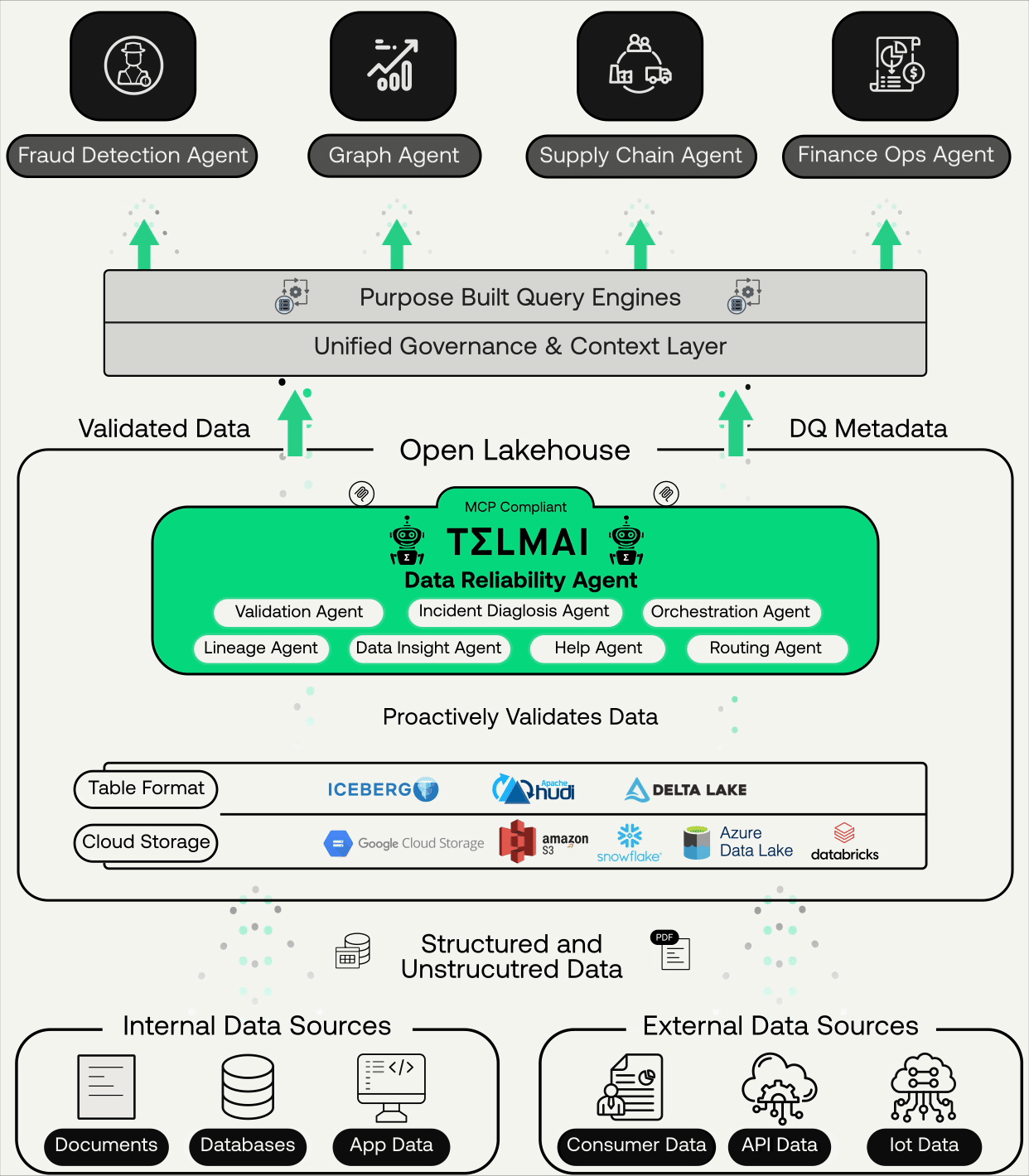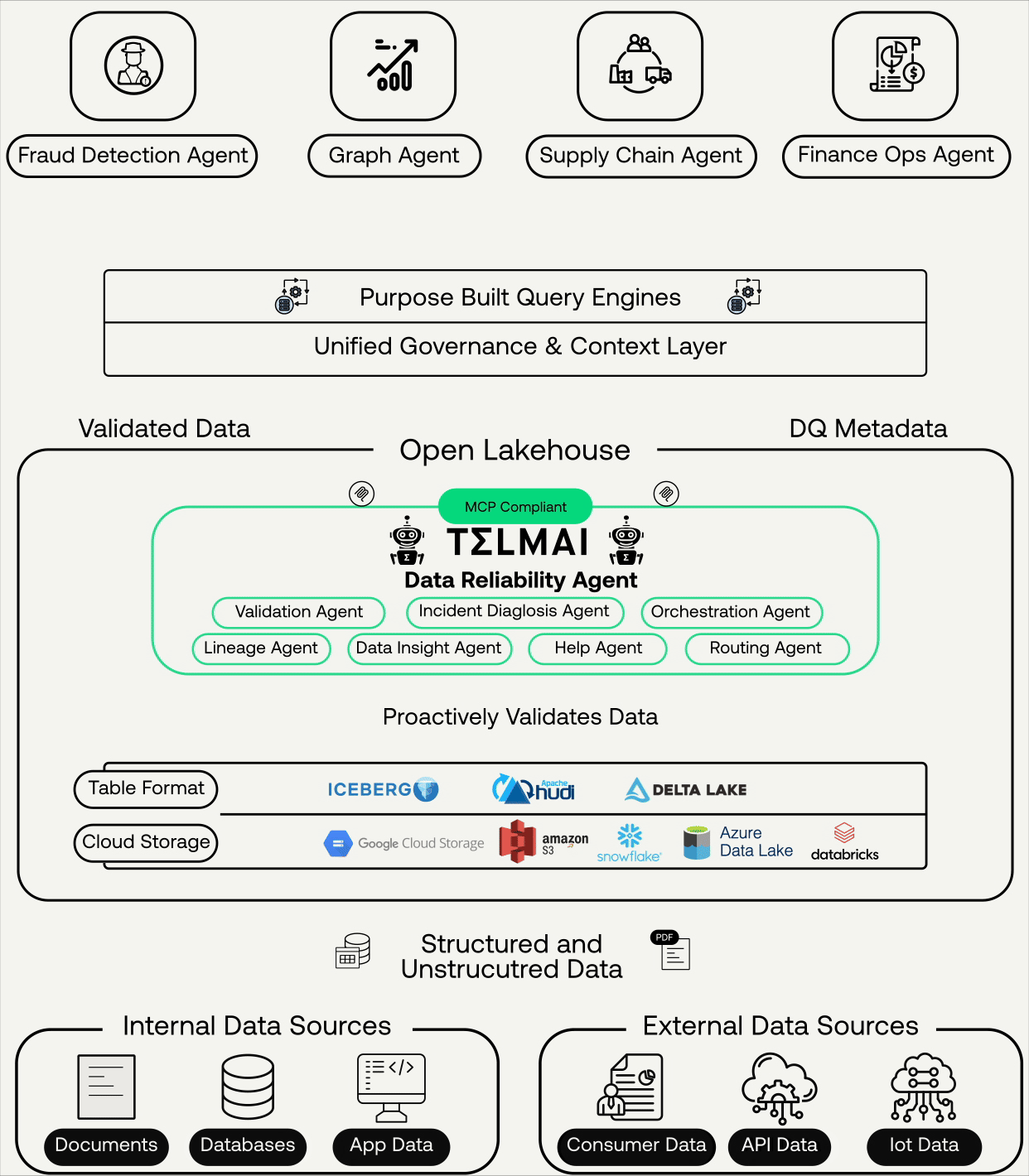
For agents to act correctly on data, trust has to be established when the data lands, not after it has already been committed to production tables. That means validating data as it arrives in open table formats like Apache Iceberg and Delta Lake at the ingestion layer. It means running ML-driven anomaly detection, schema drift checks, and volume validation before a dataset is published downstream. Each of the failure modes described above, the volume drop, the silent schema change, the distribution shift, is detectable at ingestion.
But a quality signal generated at ingestion and sitting inside an observability tool solves only half the problem. An agent querying a dataset does not consult your observability platform before it acts. It consults whatever context layer it has access to at inference time. If the trust signal does not travel with the data into that context layer, the agent operates without it.
This is the seam most enterprises are missing. Governance platforms, semantic layers, and quality tools are all present in the stack. But an agent does not experience those systems as a unified context. It experiences three separate APIs, three separate schemas, maintained by three separate teams, none of which were designed to speak to each other at the moment of decision. The fragmentation that a skilled data engineer can reason through in ten minutes is invisible, unresolvable noise to an agent operating in milliseconds.

The integration between Telmai and Atlan’s Enterprise Context Layer closes exactly that seam. Telmai’s quality metadata, freshness indicators, anomaly flags, schema change history, and volume drift signals flow into Atlan and become part of the enterprise context layer, joining semantic context, knowledge relationships, and policy rules to form the complete picture an agent needs at inference time. When an agent accesses a dataset, it sees whether the data passed validation on the last ingestion run, whether anything drifted overnight, and whether the table carries an active quality flag from the pipeline layer. That reconciliation happens once, upstream, through Atlan’s App Framework, so agents receive a single coherent trust signal rather than three partial ones they have no way to synthesize at inference time.
Trust built at the source. Context that carries it forward. That is the sequence that makes agents reliable in production, not just capable in pilots.
Without Quality Context Agents Treat Every Input as Valid by Default
Without this foundation, agents operate on assumptions that never get surfaced. They assume the table is current and the schema matches what they were trained on. They assume the volume is within normal bounds. A data engineer reviewing the same input checks, questions, and knows which pipelines to distrust on which days of the week.
An agent does not distrust anything. It consumes. And each silent assumption is a small, compounding bet that the data is fine. Most of the time it is. When it is not, nothing slows down. The agent just proceeds.
The companies that are moving from AI pilots to AI production have one thing in common. They stopped treating data quality context as instrumentation and started treating it as infrastructure. Not a dashboard to review after the fact. A signal generated at ingestion, carried through the context layer, and available at the moment an agent needs to make a trust decision.
Atlan Activate on April 29 is where that infrastructure conversation is landing, with Atlan making its most significant product announcements around the Enterprise Context Layer, the foundation that gives AI agents the business meaning, relationships, and rules they need to act on enterprise data correctly. Data quality signals are not one input among many into that layer. They are the input that determines whether every other piece of context can be trusted.
Build trust at the source. Carry it forward with context. Everything else depends on those two steps being done in sequence.
To learn more about how Telmai can help you build trusted, AI-ready data pipelines, book a tailored demo with our team of experts today.
Want to stay ahead on best practices and product insights? Click here to subscribe to our newsletter for expert guidance on building reliable, AI-ready data pipelines.