Telmai, the AI-powered data observability platform, today announced its Agentic offerings to make enterprise data truly Autonomous-Ready. These new capabilities ensure agentic AI workflows can communicate, decide, and execute actions on real-time trusted data with minimal human oversight.
Agentic AI significantly changes the requirements for how organizations manage their data and thus their data quality (DQ). Because Agentic AI requires low-latency and real-time access to validated data, it’s imperative that data quality happens right at the source, not downstream, where most companies focus their DQ efforts today.
But validation alone isn’t enough. AI agents also need to understand whether data is truly fit for purpose in the context of their actions. This involves delivering contextual information about data health as metadata into catalogs and semantic layers that AI agents can access.
Only when trust and context are combined can AI agents operate responsibly and enterprises deploy them with real confidence.
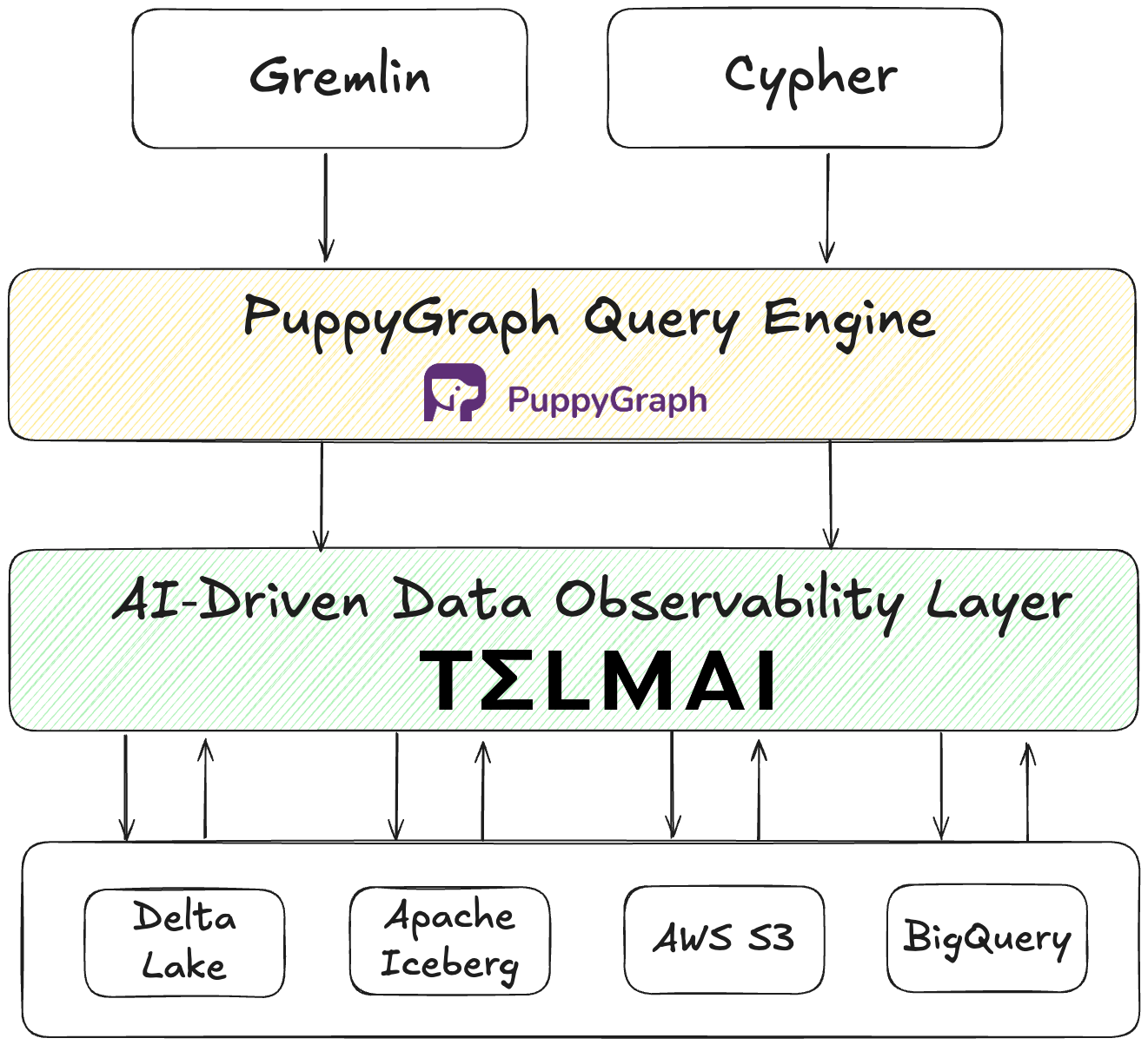
Telmai has the unique ability to continuously validate, monitor, and enrich data with quality signals at the lake and can push that data quality metadata for consumption by agents. This creates the trusted foundation that autonomous AI products need to operate reliably and at scale.
With Telmai’s latest product launch, AI agents can continuously access reliable data and the critical data quality context needed to automate downstream workflows.
Real-Time, Continuous, Agentic AI-Ready Data

At the core of this update is the introduction of Telmai’s MCP-compliant server, which enables LLM-powered agents like Claude, Bedrock, or Vertex to query Telmai directly. Telmai continuously validates data, whether structured, semi-structured, or unstructured. Additionally, it generates comprehensive data quality metadata alongside the validated data, providing essential context on data health to ensure the data is reliable and AI-ready. Through the MCP layer, AI agents can access and retrieve validated data and metadata into their agentic workflows, eliminating the need for third-party transformations or complex workarounds.
“In the era of model commoditization, true competitive advantage will emerge from trustworthy, dynamic, and contextually aware data,” said Sanjeev Mohan, industry analyst and principal at SanjMo. “Telmai’s latest release is a big step in this process. It offers continuous validation and contextual metadata that enable AI agents to act responsibly, while reducing the operational debt that has long hindered enterprise adoption.”
Natural Language AI Assistants & Decentralized Data Trust

Building on this foundation, Telmai is introducing a suite of AI assistants called Data Reliability Agents accessible through natural language interfaces, enabling both technical and non-technical users to interact directly with the platform. This decentralization means that ownership of data reliability no longer sits solely with engineering, accelerating time to value by making platform management and critical data quality insights accessible and actionable to all relevant stakeholders.
Autonomous Detection and Remediation
Telmai’s Data Reliability Agents enable autonomous detection and resolution of data anomalies. These intelligent agents continuously monitor data pipelines for irregularities and provide clear, plain-language explanations of root causes. Identifying and resolving complex data quality issues that once required deep technical expertise are now easily understood and addressed by both technical and business teams. Beyond detection, the Data Reliability Agents provide actionable recommendations and assist in generating data quality rules tailored to newly identified anomalies.
Furthermore, these Data Reliability Agents augment existing automated workflows, such as ticket creation and alert triggers, to help data teams proactively adapt and drive continuous improvement in their data quality processes.
This comprehensive approach closes the loop from detection through triage and remediation, ensuring that data being fed into the downstream processes is not only trustworthy but consistently ready for autonomous consumption and decision-making.
“As AI agents take the reins of decision-making, we believe autonomy should never come at the cost of reliability,” said Mona Rakibe, Co-founder & CEO of Telmai. “With these updates, Telmai is laying the groundwork for true intelligent automation and allowing enterprise data teams to shift their focus to driving measurable business value via Agentic AI.”
For more information or to learn more about Telmai’s Data Reliability Agents, request early access today.
Want to stay ahead on best practices and product insights? Click here to subscribe to our newsletter for expert guidance on building reliable, AI-ready data pipelines.