Data lakes vs data warehouses – explained simply
A data warehouse is akin to a well-organized box of LEGO bricks, each with its designated place, primed for specific tasks. In contrast, a data lake resembles a large tub filled with a variety of toys, representing a diverse range of raw, unstructured data ready for exploration.


A data warehouse serves as a repository for structured, processed data primed for specific analytical tasks, while a data lake is a vast reservoir holding a diverse range of raw, unstructured data, awaiting potential exploration.
Imagine you have a big box of LEGO bricks. Each brick has its own place, and there’s a specific way they fit together to build a castle. This organized box is like a data warehouse. It’s neat and structured, so when you want to build a new tower for your castle, it’s easy to find the pieces you need.
Now think of a giant tub filled with different toys – LEGO bricks, action figures, crayons, and more. Everything is mixed together, and there’s no specific place for anything. This tub is like a data lake. It holds a lot more types of toys (or data), but it’s not as organized.
Both data warehouses and data lakes have the same purpose of storing data, yet they differ in how data is collected, organized, and used.
When to use each can significantly impact data management and decision-making in modern businesses. Stick around as we delve deeper into the structural designs, components, and use cases of data warehouses versus data lakes.
Data warehouses
A data warehouse stores clean, subject-oriented data from sources like transactional systems and relational databases. They’re usually accessed by business analysts seeking to generate reports and dashboards or by data engineers for machine learning purposes. Data in a data warehouse is highly structured, hence SQL (Structured Query Language) is predominantly used to query the data, either directly by using an SQL client or indirectly by using a Business Intelligence (BI) tool.
The benefits of data warehouses are that they are:
On the other hand, the pitfalls of using a data warehouse are they have:
Data warehouse architectures
A data warehouse architecture establishes the principles governing data collection, storage, and management within the system. It comes in three distinct models:
- The single-tier architecture is a one-layer model. It reduces data storage and eliminates redundancy. Its con is the absence of a mechanism separating analytical and transactional processing. Hence, it is rarely used in practice.
- The two-tier architecture introduces a physical separation between data sources and the data warehouse via a staging area. This ensures that data loaded into the warehouse are cleansed appropriately. But, its downside is that it is not scalable. Moreover, it supports limited end-users and suffers from connectivity issues.
- The three-tier architecture consists of three layers. It is the most commonly used architecture. The bottom tier handles data cleansing, transformation, and loading. It serves as the warehouse database. The middle tier is online analytical processing (OLAP) and online transactional processing (OLTP) servers It offers an abstract database view, mediating between end-users and the database. The top tier includes tools and APIs for interacting with the data warehouse. It includes query and reporting tools, analysis tools, and data mining tools.
Components of a data warehouse architecture
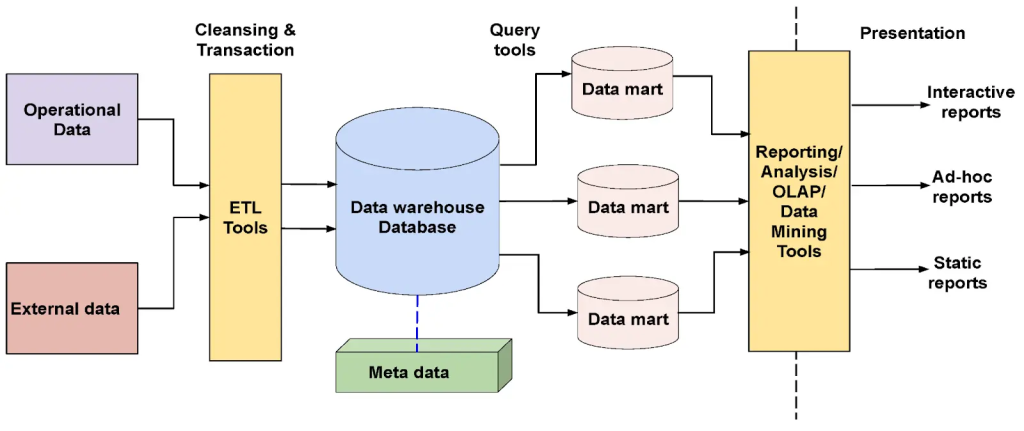
Data warehouse database
A data warehouse’s core foundation is its central database. The central database typically utilizes RDBMS technology. But, traditional RDBMS systems’ limitations stem from their optimization for transactional rather than data warehousing tasks. Parallel relational databases, new index structures, and multidimensional databases overcome these limitations. The structure within a data warehouse comprises multiple databases. The data is organized into tables and columns inside schemas. Query tools use these schemas to access and analyze the correct data tables.
ETL tools
ETL tools enable data conversion and summarization for a unified format. The extraction process collects necessary analytical data from various sources, such as spreadsheets. Transformation converts the extracted data to a standard format. Loading imports this transformed data into the data warehouse.
Metadata
Metadata defines and organizes data in a data warehouse. It includes technical details for administrators and business-related information for users.
Data warehouse query tools
Query tools enable interaction with data warehouses for decision-making. They include reporting, application development, and data mining tools. Moreover, OLAP tools offer complex multidimensional data analysis. These tools help in transforming data into actionable insights.
Data warehouse use cases
- Data warehouses are ideal for analyzing large volumes of historical data. They facilitate trend analysis over time. This provides valuable insights for data-driven decision-making.
- Data warehouses combine data from multiple sources and transform it into a standardized format. This data integration ensures business users have a single version of the truth. This reduces data discrepancies and enables accurate reporting.
- IoT devices produce big data that must be collected in relational formats for real-time and historical analysis. Utilizing a data warehouse, this data can be condensed and filtered into fact tables.
Data warehouses ensure data quality through well-defined schemas and data cleaning processes. This makes them ideal for tasks that require high data integrity tasks, such as regulatory compliance and financial reporting.
Data lakes
A data lake hosts a vast amount of raw, diverse data from various sources including social media, logs, and real-time data streams, among others. They’re typically navigated by data scientists and big data engineers who are on exploratory missions or aiming to develop machine learning models with rich, unfiltered data.
Unlike the structured nature of data warehouses, data lakes contain unstructured or semi-structured data, embracing a schema-on-read approach. This means the structure is applied only when the data is read, providing a flexible environment for data analysis. However, this approach can lead to complexities and potential inefficiencies as it may require more time and effort to structure and understand the data before it can be effectively used.
Use a data lake for its:
- Vast Variety: Like a tub filled with all kinds of toys, a data lake can store a wide variety of data (structured, semi-structured, and unstructured) enabling more creative projects.
- Exploration and Discovery: Just as you might discover a forgotten action figure at the bottom of the tub, data lakes allow for exploratory analysis and new insights.
- Scalability: As it’s easy to toss more toys into the tub, data lakes can easily scale to accommodate growing amounts of data.
But also realize that data lakes have pitfalls:
- Disorganization: Finding the exact LEGO brick you need amongst all the toys can be challenging, similar to finding specific data in the unstructured environment of a data lake.
- Requires More Preparation: Before building, you might need to spend time sorting through your toys (or preparing your data), which can delay your project.
- Potential for Mess: Just as toys can get lost or damaged in a chaotic tub, data in a data lake can become siloed or degrade in quality if not managed properly.
Data lake architecture
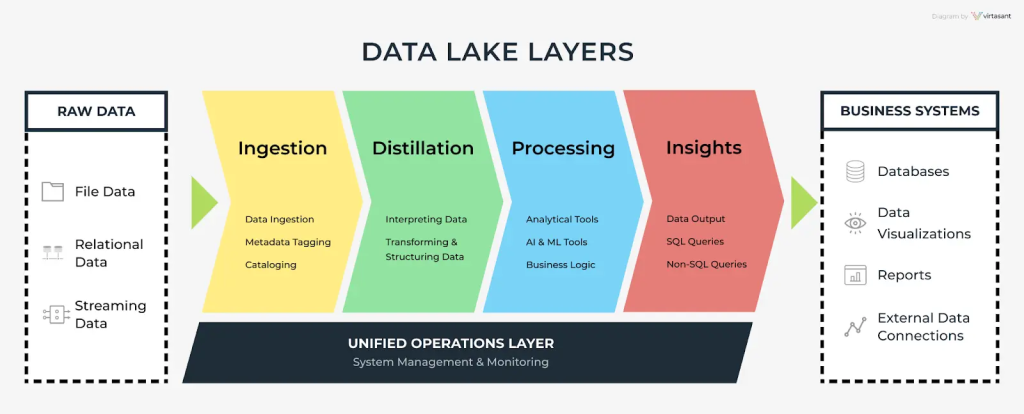
The key architectural components of a data lake are as follows:
Data ingestion layer
Data ingestion unifies all data from various sources into a data lake. The data can either be in real-time or in batches. Data sources include IoT devices, logs, geolocation data from mobile phones, social media posts, etc. The data is then organized in a logical folder structure. Tools used for data ingestion include Apache NiFi, Apache Flume, etc.
Distillation layer
The distillation layer converts raw data to a structured form ready for analysis. In this layer, the data is made consistent regarding data type, formatting, and encoding.
Processing layer
The processing layer takes cleansed data from the distillation layer and applies complex transformations. The purpose of these transformations is to customize data for analysis.
Insights layer
The processed data is available to end users in this layer for analysis and modeling. SQL or NoSQL can be used to access the data.
Data lake use cases
- Metadata Enrichment: Metadata – data about data – is essential in managing the data stored in a data lake. Metadata enrichment involves enhancing the data with additional context. For example, if you have image data, metadata might include where and when the image was taken, the type of camera used, etc.
- Analytics: For Analytics, data lakes offer a comprehensive view of data. Data lakes facilitate sophisticated analysis and data-driven decision-making. The data available can also be used for building machine learning models.
- Query-Based Data Discovery: A significant advantage of data lakes is the ability to hold massive amounts of raw data in its native format. This means data can be queried in a customized way. This allows for flexible data discovery.
- Tracking Lineage in Raw Data: Data lineage is about understanding where data comes from, how it moves over time, and how it changes. It’s crucial for data governance, compliance, and troubleshooting. Tracking lineage is essential in a data lake, where vast amounts of data from various sources are stored.
Bridging the divide: the rise of data lakehouses
A data lakehouse represents a hybrid model that combines the structured, ready-for-analysis environment of a data warehouse with the raw, extensive data storage capacity of a data lake.
Imagine a large, modular toy organizer where LEGO bricks, action figures, and crayons each have their designated drawers, yet they can also be mixed in one large bin if needed. This setup gives you the flexibility to either grab specific toys quickly or dive into the mixed bin for creative play. Similarly, a data lakehouse provides structured, well-managed data environments for specific analytical needs while also allowing the exploration of raw data for unexpected insights.
Data lakehouses are especially effective because they allow:
- Unified Platform: They merge the best features of data lakes and warehouses, reducing the need for multiple systems and easing the data management process.
- Cost-Effectiveness: By consolidating data operations into a single platform, you can significantly cut down on operational costs and complexity.
- Openness and Flexibility: Data lakehouses support various data types and structures, from structured to semi-structured to unstructured, all while maintaining high standards of data governance and quality control.
- Performance and Scalability: They’re designed to scale efficiently and perform high-speed analytics, crucial when dealing with large volumes of data.
However, transitioning to a data lakehouse architecture can present challenges:
- Integration Complexity: Merging existing data management systems into a lakehouse architecture requires careful planning and execution.
- Learning Curve: Adapting to new tools and practices involved in managing a lakehouse takes time.
- Upfront Investment: Although cost-effective in the long run, initial investments in technology and training can be substantial.
In essence, data lakehouses aim to provide a best-of-both-worlds solution by maintaining the meticulous structure of data warehouses while embracing the vast, explorative nature of data lakes. This innovative approach can dramatically enhance the agility and capability of data-driven organizations, paving the way for more sophisticated and comprehensive data analysis strategies.
Read more about the architecture and considerations behind lakehouses →
Unlock your data’s full potential with Telmai
Question of the day:
How can you gauge the quality and compliance of your data in a data warehouse or data lake architecture?
Telmai helps you do that. Telmai has more than 40 KPIs to monitor data, such as schema, pattern drifts, and controlled lists. Telmai is a no-code platform that creates alerts on unexpected drifts in the data metrics. Once alerted, it allows for faster identification of root problems. You can also create customized alerts.
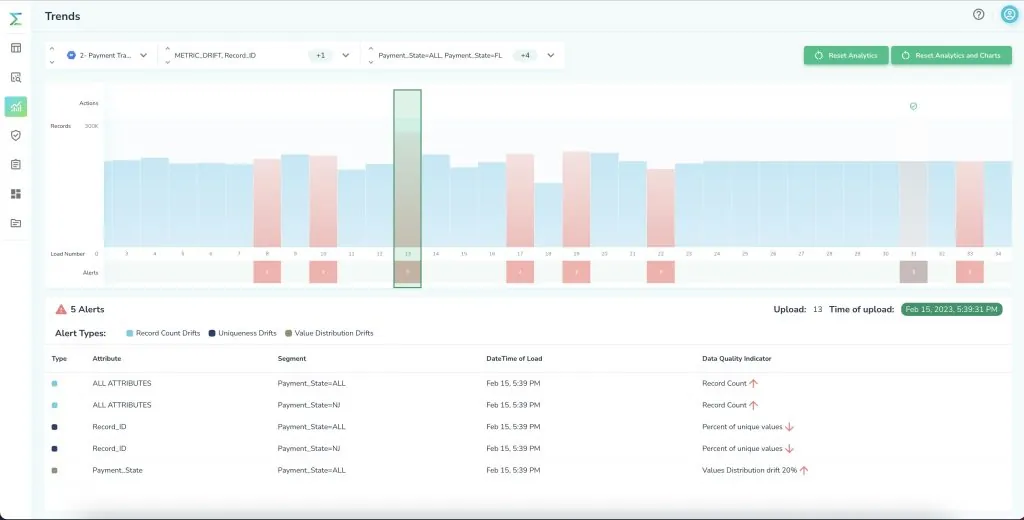
Interested in seeing Telmai in action? Request a demo today.
Passionate about data quality? Get expert insights and guides delivered straight to your inbox – click here to subscribe to our newsletter now.
- On this page
See what’s possible with Telmai
Request a demo to see the full power of Telmai’s data observability tool for yourself.


