Building trustworthy RAG pipelines with automated data quality workflows
Learn how to build trustworthy RAG pipelines using AI-driven data quality workflows.

The enterprise AI landscape is undergoing a seismic shift. No longer confined to isolated experiments, enterprise AI implementations are being embedded into the very fabric of business operations, seeking not just automation but true intelligence.Yet, as organizations race to operationalize AI, a fundamental challenge emerges: How can we ensure that our AI models access the most current and relevant information in real time?
Retrieval-augmented generation (RAG) is rapidly becoming the gold standard, enabling AI to draw on real-time business data. However, RAG’s effectiveness hinges on the quality and reliability of the data it retrieves.
In this article, we explore the critical role of RAG in enterprise-grade AI and provide a blueprint for building scalable, trustworthy pipelines, ensuring that your AI initiatives are powered by data you can trust.
What is Retrieval-Augmented Generation (RAG)?

Retrieval-Augmented Generation (RAG) is a hybrid AI architecture introduced by Meta in 2020 that combines the generative capabilities of large language models (LLMs) with the precision of real-time data retrieval.
Unlike traditional LLMs that rely solely on pre-trained knowledge, RAG systems dynamically fetch relevant information from enterprise knowledge bases or curated document repositories before generating a response. This allows AI outputs to be grounded in current, authoritative, and domain-specific data.
Here’s how a typical RAG flow works:
- Query processing: The process begins when a user submits a query. This query serves as the input trigger for the RAG system.
- Data retrieval: Using semantic or keyword-based search, the system retrieves the most relevant documents from a knowledge source, often powered by a vector database.
- Integration with the LLM: The retrieved documents are combined with the original query and passed into the LLM as augmented context.
- Response generation: The LLM then generates a response using both its generative capabilities and the retrieved context, improving factuality and relevance.
This retrieval-augmented design enables enterprise AI systems to deliver responses that are not only fluent and human-like but also factually grounded in up-to-date, trusted information, without the need to retrain the model every time new knowledge emerges.
The Limits of Traditional LLMs in Enterprise Use
While large language models (LLMs) are trained on expansive public datasets and have demonstrated remarkable generative capabilities, their static architecture imposes significant limitations when applied in enterprise settings.
- Real-time knowledge cutoff: Traditional LLMs lack awareness of recent events or dynamic internal changes. This creates blind spots in industries where regulatory updates, financial developments, or operational shifts happen frequently.
- Contextual accuracy: LLMs do not natively understand proprietary content such as internal documentation, customer interactions, or business-specific terminologies, leading to generalized or off-base outputs.
- Factual grounding: Without access to dynamic, real-world data, LLMs can produce plausible-sounding but incorrect responses. These hallucinations undermine stakeholder trust in AI-driven initiatives.
These shortcomings create serious risks for enterprises, especially in use cases like financial reporting, HR policy dissemination, product support, or regulatory compliance. Responses must be not only fluent but also verifiable, traceable, and tailored to domain-specific contexts.
Data Quality Pitfalls in AI Pipelines
Unlike static LLMs, RAG systems rely heavily on the accuracy and integrity of the data they retrieve. If data of low quality or inconsistent data is indexed or embedded, the model may generate misleading outputs with a false sense of confidence.
Here are some of the most common data quality challenges that undermine RAG systems:
- Missing or incomplete data: Sparse fields, null values, or partial records can degrade embedding quality, leading to weak semantic representations and gaps in contextual understanding
- Format inconsistencies: Variations in date formats, schema drift, or unstandardized entries can break downstream processing, misalign fields, and produce faulty embeddings
- Value drift: As business processes evolve, the meaning and distribution of data change over time. If drift goes undetected, embeddings may reflect outdated patterns, producing inaccurate or misleading results
- Conflicting or duplicate records: Redundant or contradictory entries from multiple systems can confuse retrieval mechanisms and reduce the precision of search results
- Poor metadata labeling: Unbalanced or mislabeled data, as well as fragmented data access, can introduce bias, reduce model fairness, and limit the scope of retrieval
Impact on RAG Pipelines:

- Embedding Generation: Poor quality data leads to low-quality embeddings, undermining the entire retrieval process.
- Vector Search Accuracy: Noisy or inconsistent data results in imprecise similarity searches, causing irrelevant or incorrect documents to be retrieved.
- Output Relevance and Trust: If the retrieved context is flawed, the LLM’s response will be less accurate, less trustworthy, and potentially non-compliant.
As enterprises scale their RAG deployments, these data quality issues are magnified by the sheer volume, velocity, and diversity of data sources, making manual validation impossible and automated data quality management becomes essential to ensure the integrity and reliability of AI-generated outputs.
Building Scalable, Trustworthy RAG Pipelines
To realize the full potential of RAG in the enterprise, organizations must architect pipelines that are both scalable and trustworthy. Below are essential strategies to ensure your RAG systems maintain integrity, compliance, and performance as they scale:
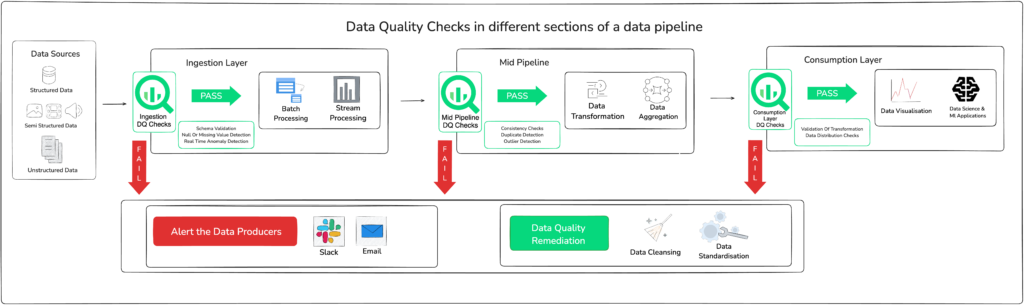
Validating data at source before ingestion – Implement real-time data quality checks and domain-specific validation rules at the ingestion point. Ensure data is cleansed, complete, and compliant, especially for sensitive information like personally identifiable information (PII) or regulated attributes, before it is embedded into a vector database. This preemptive gating mechanism prevents compromised or non-compliant data from entering the RAG pipeline.
Ensure continuous data curation through comprehensive observability – Establish real-time monitoring of data quality metrics and user feedback to detect drift, anomalies, or pipeline failures before they impact production. Configure alerts and circuit breakers to flag or halt ingestion when thresholds are breached. These systems can detect anomalies, automate remediation, and provide root cause analysis without manual intervention. When embedded natively into RAG pipelines, they ensure that only clean, high-confidence data flows into your AI systems, helping you maintain both performance and trust at scale.
Conclusions and Practical Recommendations
As enterprises weave AI deeper into core business functions, Retrieval-Augmented Generation (RAG) is emerging as a critical architecture for delivering relevant, factual, and contextual AI-generated responses. However, the reliability of RAG outputs depends fundamentally on the quality of the underlying data.
To ensure AI implementations successfully deliver business value, organizations must strengthen the reliability of the data pipelines on which their models depend.
This is where modern data observability platforms like Telmai are redefining enterprise data quality management. Purpose-built for complex distributed data ecosystems, Telmai continuously validates structured and semi-structured data at scale without sampling or pre-processing. Its AI-driven engine detects anomalies, schema drift, and value inconsistencies in real time, ensuring high-fidelity data powers downstream systems. With native integration across cloud data warehouses, data lakes, streaming platforms, and message queues, Telmai delivers complete pipeline visibility and automated remediation, without adding complexity to your existing infrastructure.
Discover how Telmai can transform operationalizing data quality in their AI workflows. Take a quick product tour now!
Passionate about data quality? Get expert insights and guides delivered straight to your inbox – click here to subscribe
- On this page
See what’s possible with Telmai
Request a demo to see the full power of Telmai’s data observability tool for yourself.



