Demystifying data quality’s impact on Large Language Models
In this experiment, we deliberately introduce errors into the data used to fine-tune a large language model (LLM) and discuss strategies and practices for ensuring high-quality data.


In the evolving landscape of artificial intelligence, Large Language Models (LLMs) have proven to be a cornerstone in harnessing the power of data for various applications, from chatbots to content generation.
These models can understand and generate human-like text, making them invaluable in text summarization, sentiment analysis, and language translation applications.
However, the true magic behind these models lies in their training data, especially when they are being fine-tuned for particular use cases. LLMs learn from vast amounts of text data, which shapes their understanding of language and the world. This is where data quality becomes paramount, as it can make or break their effectiveness. In this blog, we will delve into the world of LLMs, explore the significance of data quality, and demonstrate the tangible impact of poor data quality on model performance. We will also provide you with code snippets to experiment independently and highlight how Telmai can help address these data quality challenges.
Why data quality matters
Imagine a language model as a sponge soaking up knowledge from the text it’s trained on. The model absorbs valuable insights if the text is clear, accurate, and representative of the real world. But what happens when the sponge soaks up murky water?
Poor data quality can introduce noise, biases, and inaccuracies into the training process. This can lead to several undesirable consequences:
- Biased Outputs: LLMs may generate text that reflects the biases present in the training data, perpetuating stereotypes and discrimination.
- Inaccurate Information: If the data contains inaccuracies, the model’s responses may be factually incorrect, leading to misinformation.
- Unintended Consequences: Subtle errors in data can result in contextually inappropriate or nonsensical outputs.
- Reduced Performance: Ultimately, poor data quality hampers the model’s performance and limits its ability to provide meaningful insights.
Setting the stage: understanding our dataset and experiment structure
To better understand the impact of bad data on the performance of Language Learning Models (LLMs), we will experiment with fine-tuning of a common open-source model on datasets with different amounts of noise injected.
We will start with ‘blbooksgenre’ dataset, a rich compilation of books digitized through a joint initiative between the British Library and Microsoft, and try to classify them into Fiction and Non-Fiction categories using LLM. Here is a link to the original experiment where a model is fine-tuned and trained to predict whether a book listed in the same dataset is Fiction or Non-Fiction based on the book’s title.
In our experiment, we deliberately introduce noise – inconsistencies and errors – into the data, mimicking real-world scenarios of data degradation that we’ve observed in various customers’ data pipelines. We utilize DistilBert, a transformer-based language learning model (LLM) designed to process and understand natural language data efficiently and examine the fluctuations in performance metrics as we train it on various datasets with errors and inconsistencies.
While this is a toy example, a similar approach can be applied to harness the potential of your business’s data. For instance, it can help organize legal documents or product documentation into categories relevant to your company or help classify vast tables or datasets in your data ecosystem.
Creating the benchmark model
Step 1: Loading the Dataset and Importing Essential Modules
Let’s start by loading a dataset of book titles and their respective genres. This dataset is very clean and accurate and will serve as a baseline for the experiment. Similarly, you can pick a dataset of your choice.
from datasets import load_dataset
bookgen = load_dataset('blbooksgenre', 'title_genre_classifiction', cache_dir="/mnt/llm/datasets")Step 2: Tokenize the data
We tokenize the data utilizing the powerful DistilBertTokenizer via the HuggingFace client library, thus preparing the data for the model training phase.
#Tokenize the Data
from transformers import DistilBertTokenizer
tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-cased")
#tokenize data
bookgen = bookgen.map(bookgen(data['title'], truncation=True, padding='max_length'), batched=True)Step 3: Segmenting the data & train the model
As we progress, the dataset is segmented into training and testing subsets, adhering to an 80/20 division, 80 for training and 20 for testing.
Following this, we initialize and train the DistilBertForSequenceClassification model on the training set. Class weights are utilized to address potential data imbalance issues. The ‘Trainer’ object further facilitates the smooth training of the model, incorporating specific training arguments for an optimal outcome.
from sklearn.model_selection import train_test_split
# Get the dataset in the form of lists
titles = bookgen['train']['title']
labels = bookgen['train']['label']
# Split the dataset into 80% training and 20% testing
train_titles, test_titles, train_labels, test_labels = train_test_split(titles, labels, test_size=0.2, random_state=42)
# Convert the lists back into datasets
train_dataset = bookgen['train'].filter(lambda example: example['title'] in train_titles)
test_dataset = bookgen['train'].filter(lambda example: example['title'] in test_titles)
#Load pretrained DistilBert model
model = DistilBertForSequenceClassification.from_pretrained('distilbert-base-cased', num_labels=2)
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
warmup_steps=500,
weight_decay=0.01,
logging_dir='./logs',
evaluation_strategy="steps", # Add this to evaluate model periodically
eval_steps=100, # Evaluate every 100 steps
logging_steps=100, # Log every 100 steps
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
)
trainer.train()Step 4: Making predictions using a trained model
from datasets import Dataset
def make_prediction(title_to_predict, trainer, tokenizer):
tokens = tokenizer(title_to_predict, return_tensors='pt', truncation=True, padding='max_length')
single_dataset = Dataset.from_dict({k: [v[0]] for k, v in tokens.items()})
# Make the prediction
prediction = trainer.predict(single_dataset)
# Get the predicted label
predicted_label = 'Fiction' if prediction.predictions[0].argmax() == 0 else 'Non-Fiction'Injecting And creating datasets with noise
For the second part of our experiment, we deliberately infuse controlled noise within the same dataset, simulating conditions of data corruption that resemble real-world scenarios, and then follow the same fine-tuning process but with the affected data to measure the impact.
The following types of data problems are injected:
- Imbalanced Training Data: Often, data used for training or fine-tuning models can over-represent one category or label versus others. In this experiment, we modeled such a situation when Fiction represented 75% of the dataset versus 25% Non-Fiction
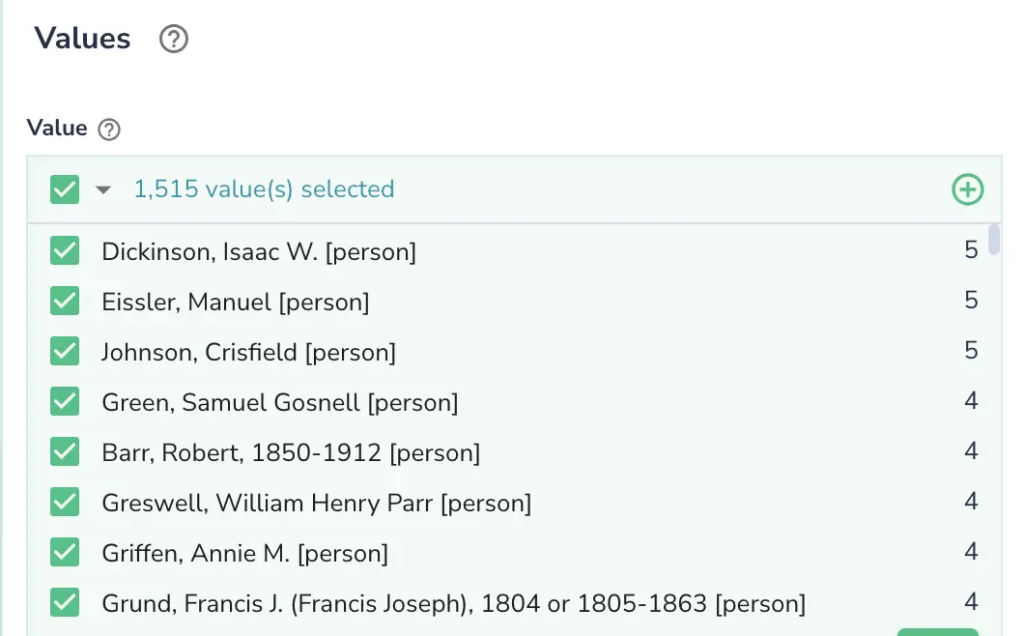
- Attribute mix-up: Sometimes bugs are introduced in the data pipeline code, which may result in data ending up in the wrong attributes. In our experiment, we modeled it by interchanging book authors with book titles in 50% of records
- Value Truncation: Another common problem we’ve seen in the real world is again due to various bugs when values get truncated. To model it we altered 40% of records by truncating the title by at least 50%.
Observations
As the noise level in the dataset increases, we notice a gradual decrease in precision and accuracy, showcasing the impact of data quality on model performance.
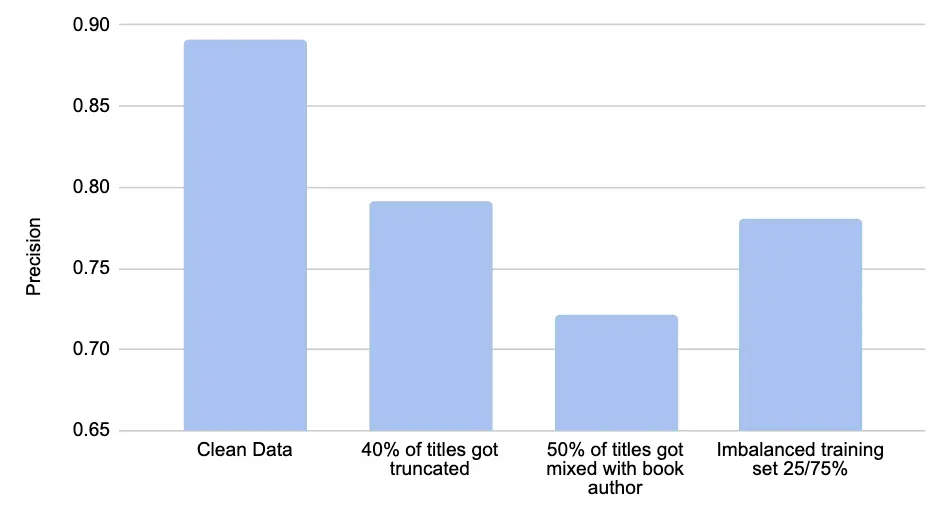
This simple experiment shows a significant drop in the quality of predictions with the noise in the training data, from 89% precision down to 72%. But what’s even more important, through recent research, it was shown that LLMs require much smaller training datasets to achieve certain quality when using higher quality data for fine-tuning, drastically reducing the costs and time required for development.
Unlock your AI’s potential with data-quality solutions

Data quality is the foundation of successful Generative A, traditional ML, and data-driven projects. Teams using data quality tools like Telmai can greatly increase the likelihood of success with their ML and LLM projects while not blowing up project budgets unexpectedly, having to build tools, or spending time wiring queries to discover unknown anomalies in the data.
The noise instances highlighted above can be efficiently identified using Telmai’s robust profiling and data monitoring features. These include:
- Detecting imbalanced labels through comprehensive pattern and value distribution analysis.
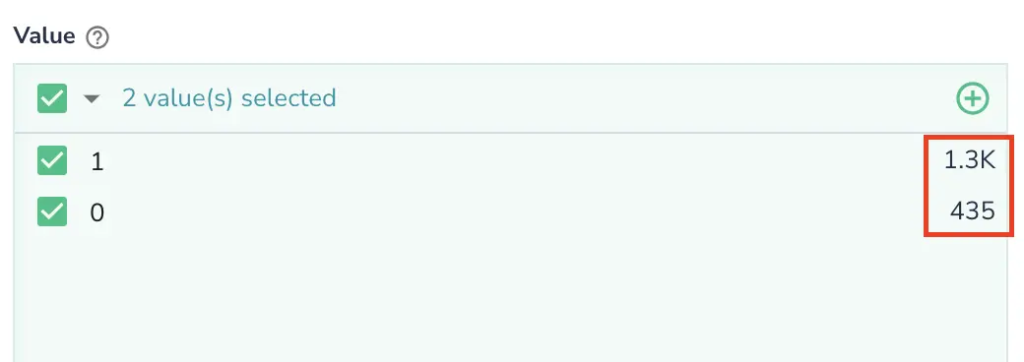
- Identifying attribute mix-ups by emphasizing irregularities in pattern and value frequencies
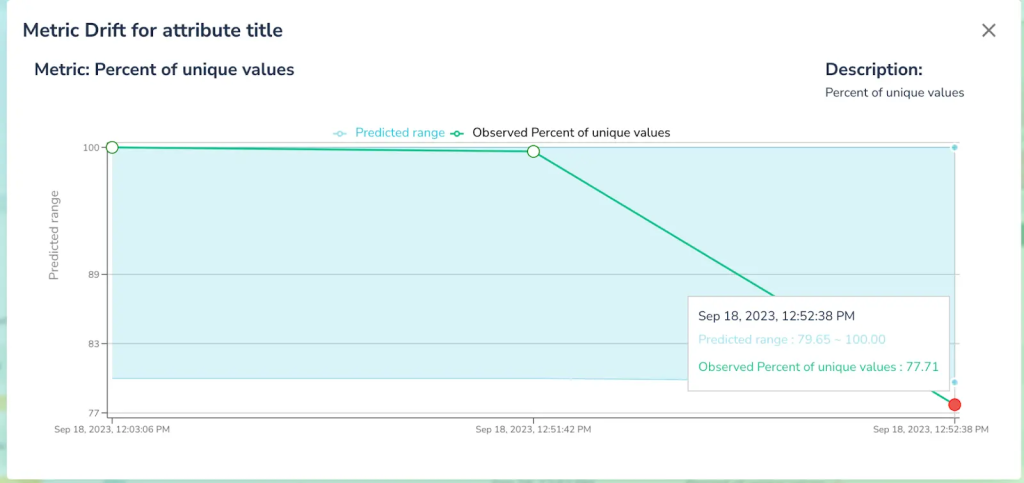
- Spotting value truncations by analyzing anomalies associated with value lengths
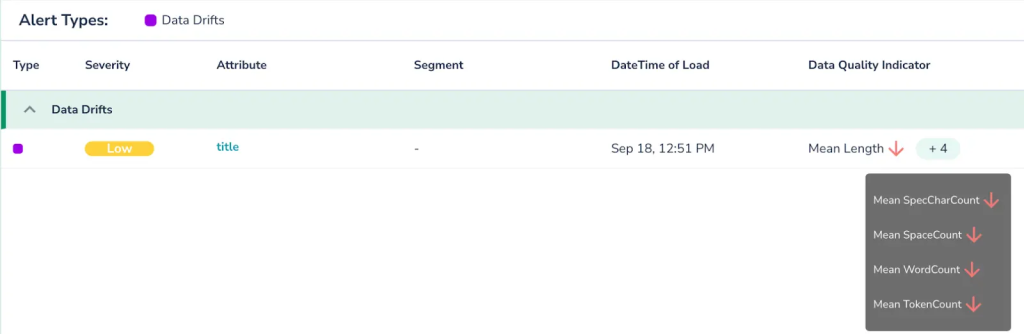
What sets Telmai apart is its ability to facilitate all these functions without writing a single line of code. Telmai is transforming the landscape of data quality management by introducing a no-code setup that automatically alerts users to unexpected drifts, including changes in row counts, schema changes, and unusual variations in value distribution. Further, Telmai arms users with sophisticated tools for swift and precise identification of root causes of data discrepancies. It also provides visual indicators of value distributions, pattern structures, and anomaly ratings, facilitating a more in-depth analysis.
Click here to discover how Telmai can boost your data quality and AI initiatives. Unlock your AI’s full potential with Telmai!
Don’t miss Max Lukichev’s webinar on how data quality shapes the effectiveness of LLMs, featuring hands-on experiments and insights. Click here to watch now.
Are you looking to explore how data quality can drive better AI outcomes? Check out our Data Quality for AI Guide and uncover actionable strategies to ensure trustworthy data.
Passionate about data quality? Get expert insights and guides delivered straight to your inbox – click here to subscribe to our newsletter now.
- On this page
See what’s possible with Telmai
Request a demo to see the full power of Telmai’s data observability tool for yourself.



