Data+AI Summit 2025 Recap: How Databricks is reengineering the data stack for trusted AI workloads
Explore key announcements from Databricks Data+AI Summit 2025 through the lens of data quality and observability. Discover what they signal for data engineers, architects, and CDOs.


“AI is not just another tool. It’s transforming how we build applications, how we reason on data, and how we make decisions.” — Ali Ghodsi, CEO of Databricks
That quote set the tone for this year’s Databricks Data + AI Summit, signaling a strategic shift in how modern data platforms are evolving to support enterprise-scale AI workloads. From the launch of Lakebase to the debut of Agent Bricks and upgraded governance in Unity Catalog, Databricks laid out its vision for an architecture purpose-built for AI: open, unified, and trusted by design.
In this blog, we explore the announcements through the lens of data engineers, architects, and CDOs, focusing on scaling trustworthy pipelines, enforcing governance, and confidently enabling AI-native workloads.
1. Lakebase: AI workloads meet OLTP
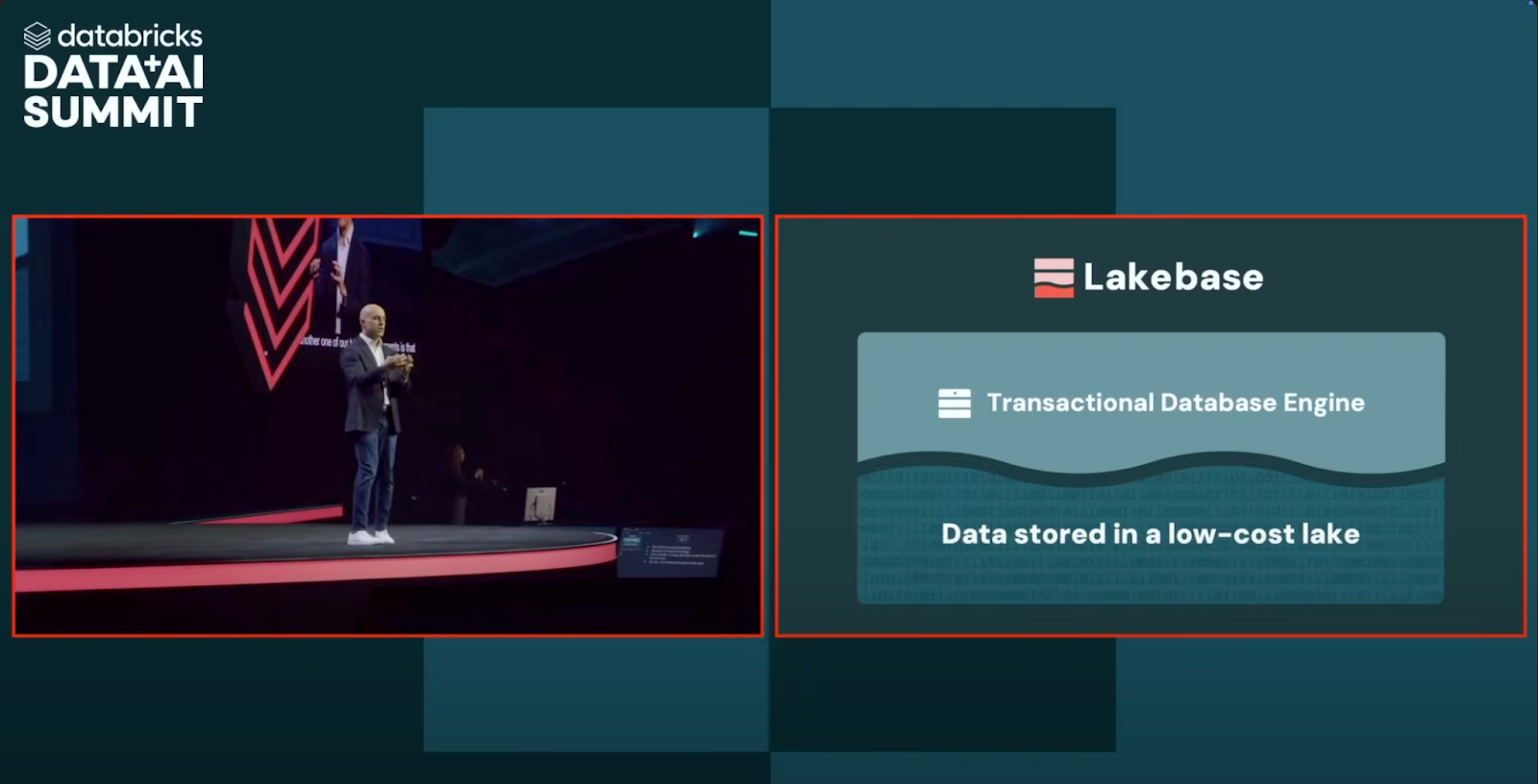
Databricks introduced Lakebase, a fully-managed, Postgres-compatible database natively integrated with the Lakehouse. Designed to power AI-native applications, Lakebase supports real-time transactional updates and unifies OLTP and OLAP under one governed architecture.
As Ali Ghodsi said during the keynote, “What if you can get the performance and simplicity of Postgres, but in a system that scales and shares governance with your lakehouse?” That’s the premise behind Lakebase—a new foundation for operational analytics and intelligent applications built directly into the Databricks platform.

Powered by Neon, Lakebase brings developer-friendly capabilities like branching, autoscaling, and storage-compute separation, while extending Unity Catalog’s governance, security, and lineage model across workloads.
2. Agent Bricks: Low-code, production-ready AI agents
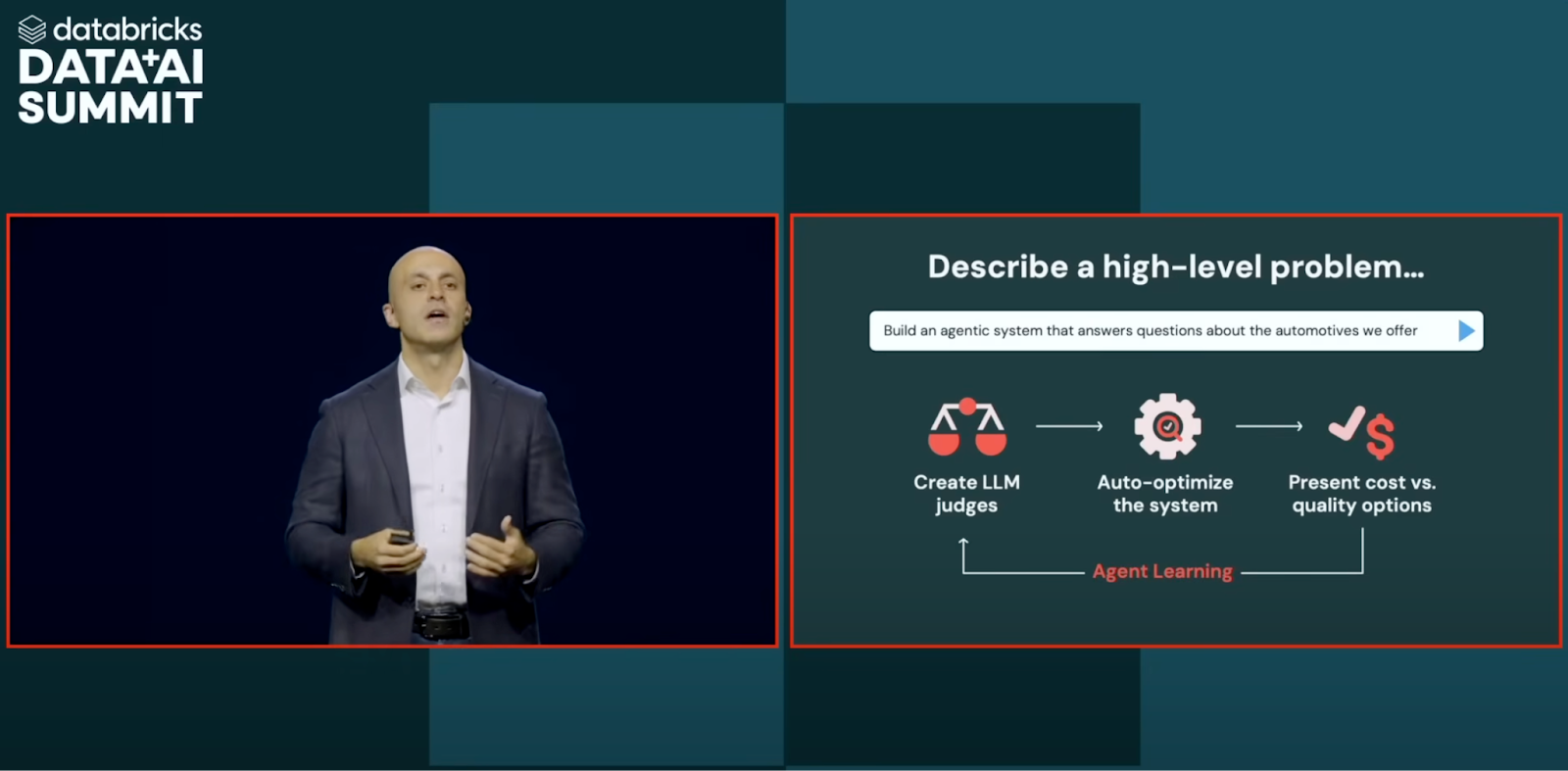
Databricks introduced Agent Bricks, a declarative framework for building reliable, enterprise-grade AI agents without requiring ML expertise. It enables teams to synthesize data, tune prompts, and evaluate LLM outputs through built-in “judges” that automate quality control.
Ali Ghodsi explained the vision clearly: “We want to make it super easy for developers to build agents using their own enterprise data. That’s why Agent Bricks is declarative and production-ready from day one.”
With built-in observability, Agent Bricks helps teams avoid hallucinations and optimize for both performance and cost. Matei Zaharia, Co-founder and Chief Technologist at Databricks, summed it up best: “It’s like having a hundred AI engineers and labelers working under the hood for you—automatically.”
3. Lakeflow Designer: ETL for the no-code era
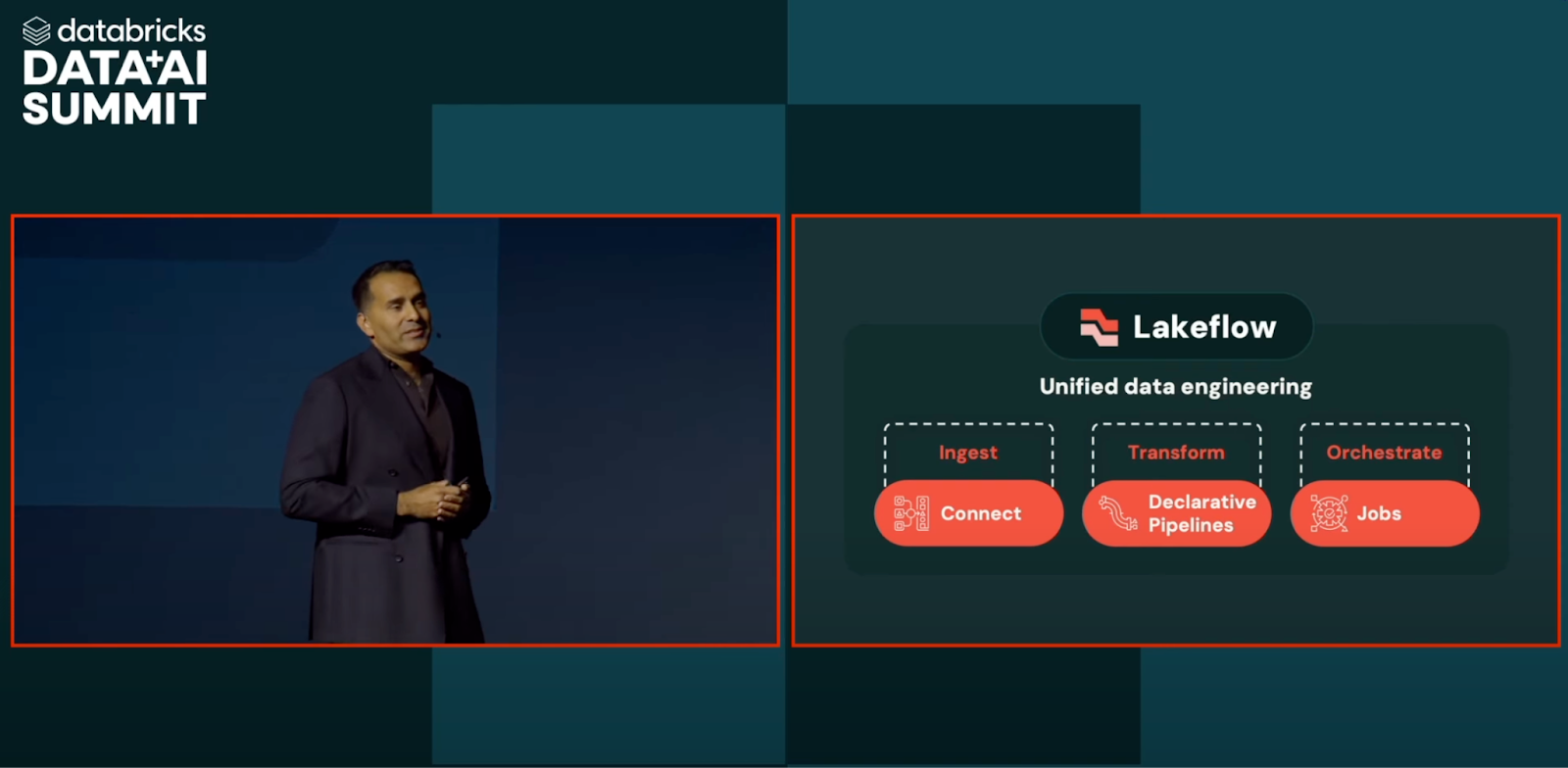
Databricks introduced Lakeflow, a unified orchestration layer that simplifies pipeline creation across batch, streaming, and unstructured data sources. During the keynote, Bilal Aslam, Principal Product Manager at Databricks, showcased its visual interface by saying: “You can drag, drop, and orchestrate the entire workflow visually, whether it’s streaming, batch, or unstructured sources.”
This drag-and-drop capability, known informally as the Lakeflow Designer, lowers the barrier to building enterprise-grade pipelines, making it easier for non-engineering teams to automate data workflows. It complements the GA release of Lakeflow, which also includes native connectors for GA4, SQL Server, and other sources, enabling faster time-to-value for data engineering teams working across hybrid data estates.
4. Unity Catalog Enhancements: Unified Semantic Layer and Iceberg Interoperability
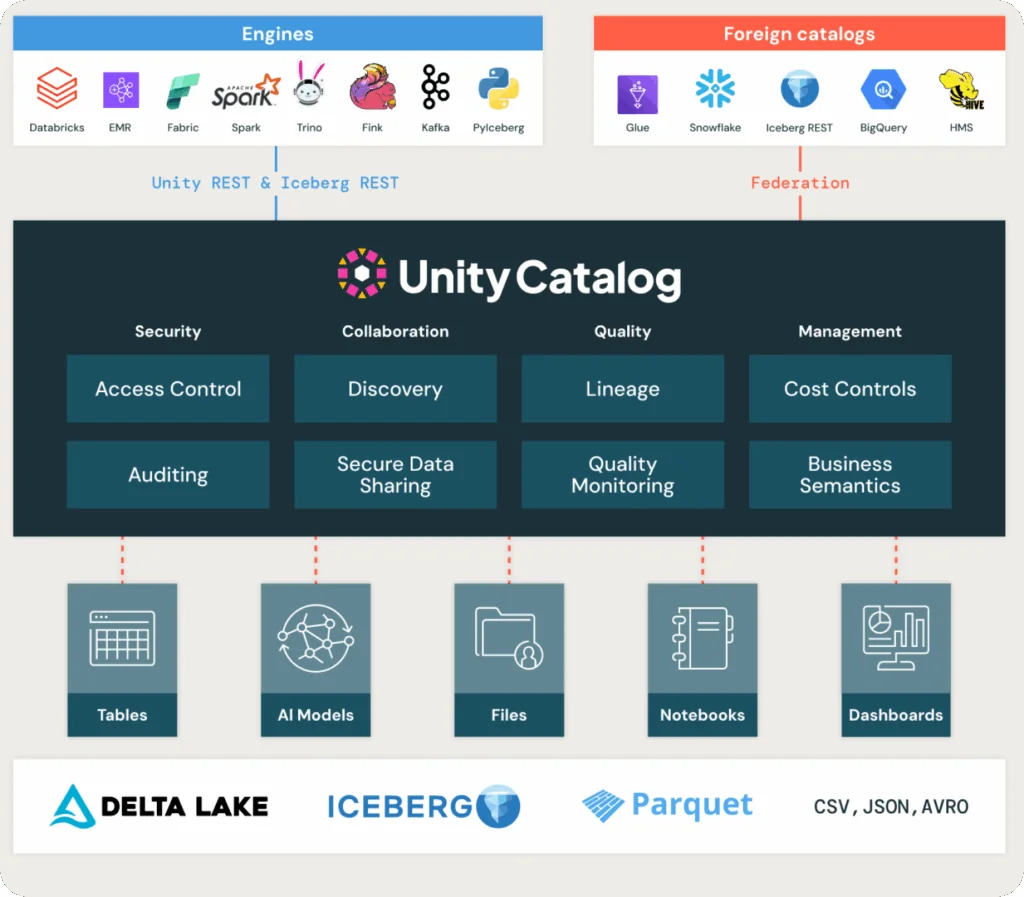
Unity Catalog received major updates that solidify its role as the unified governance layer for multi-format and AI-centric data environments:
- Full support for Apache Iceberg, including read/write capabilities and REST APIs for enhanced interoperability
- Metric definitions as first-class objects, letting teams define, standardize, and query KPIs and business metrics within the catalog
- A new Discovery UI for semantic search, easier lineage exploration, and improved navigation across federated data assets
Michelle Leon, Director of Product Management at Databricks, explained how these capabilities offer enterprises “a single control plane to manage structured, unstructured, and streaming data—while unifying governance across all formats.”
Databricks also reaffirmed its open standards strategy by extending full support for Delta Lake, Apache Iceberg, and Parquet. As Michelle noted during the keynote, these enhancements allow teams to “work with multiple formats natively, while applying consistent governance and lineage across all of them.”These updates position Unity Catalog as more than a governance solution—it now serves as a semantic layer that bridges formats, clouds, and workloads. Whether managing data in Iceberg, Delta, or Parquet, teams can enforce governance and deliver trusted, AI-ready architectures with interoperability and composability at scale.
5. MLflow 3.0 and MosaicML: Observability and performance tuning for GenAI
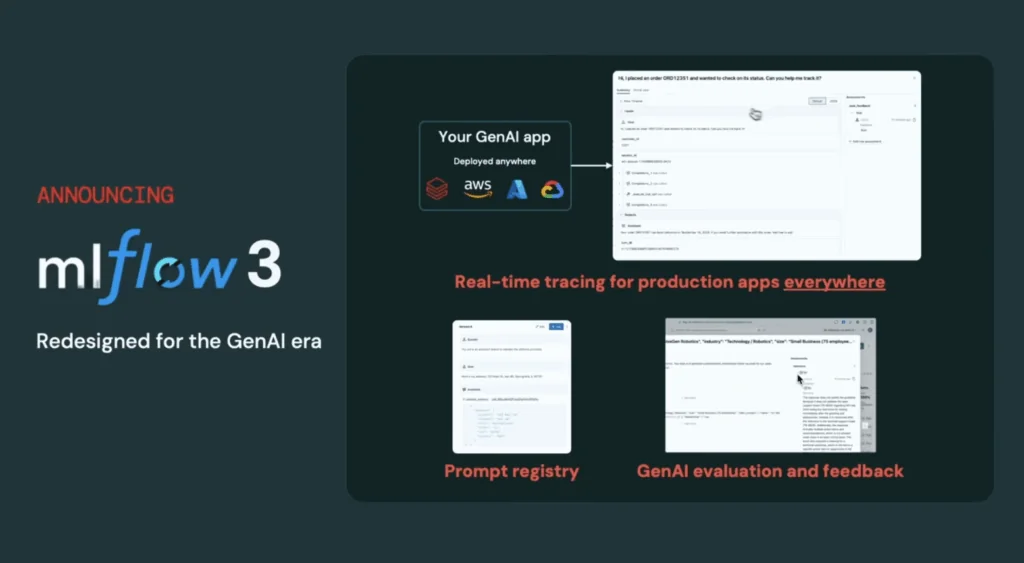
Databricks unveiled MLflow 3.0, expanding its capabilities beyond traditional ML to support end-to-end GenAI observability. New features include prompt tracking, output evaluation, cost tracing, and feedback loops, giving teams complete visibility into model behavior.
“MLflow gives you full visibility into your GenAI pipeline—so you can optimize performance and reduce hallucinations” said Matei Zaharia, Databricks Co-founder and Chief Technologist.
Alongside this, MosaicML introduced new infrastructure for scalable, high-performance inference:
- Vector search (now in preview)
- Serverless GPU clusters for simplified deployment
- TAO (test-time optimization) to improve inference speed and cost-efficiency for open-source LLMs
These enhancements position Databricks as a unified platform not just for model training, but for managing the lifecycle, quality, and cost of GenAI in production, making reliability measurable at every step.
Final Thoughts: Building AI-ready lakehouses requires native data trust
The 2025 Databricks Summit made one thing clear: the future of enterprise data architecture is open, composable, and AI-native by design.
With innovations like Lakebase, Agent Bricks, MLflow 3.0, and Unity Catalog, Databricks is unifying storage, governance, and AI into a single intelligent foundation. AI-native applications now demand governed, real-time access to both transactional and analytical data, delivered through a unified control plane.As organizations adopt Apache Iceberg, Delta Lake, manage hybrid data pipelines, and deploy AI agents on operational data, the room for error narrows. A single schema drift or freshness issue can skew predictions and erode trust in AI systems.
That’s why trust must be embedded at the data layer, not added after the fact. This is where Telmai adds critical value:
- Enforce governance and trust without sampling or manual intervention
- Natively monitor and validate data across Apache Iceberg, Delta Lake, and Hudi without duplication or overhead
- Detect anomalies, schema drift, and freshness gaps before they degrade AI and analytics outputs
Reliable AI starts with reliable data. Click here to talk to our team to learn how Telmai can accelerate access to trusted and reliable data in your databricks ecosystem.
Passionate about data quality? Get expert insights and guides delivered straight to your inbox – click here to subscribe to our newsletter now.
- On this page
See what’s possible with Telmai
Request a demo to see the full power of Telmai’s data observability tool for yourself.
Articles
See all articles

