Best data quality tools: Reactive and Preventative
Data quality is not merely a technical hurdle; it’s the bedrock of thriving businesses. As your startup grows, the importance of a comprehensive data quality toolkit to both combat and avert issues becomes paramount.
![Best Data Quality Tools [Reactive AND Preventative]](https://www.telm.ai/wp-content/uploads/2023/10/1.4-6.png)

In the previous blog post, we discussed common data quality challenges at different stages of the data lifecycle. Data quality isn’t just a technical problem; it’s a foundation upon which successful businesses are built. In the early days of a startup, it’s easy to overlook the nuances of data, but as you scale, the stakes get higher. You need a robust data quality toolkit to not only fight fires, but prevent them.
In this article, we’ll take a look at various solutions– not only the fire extinguishers but smoke detectors too – so you’ll never end up in an uncontrollable blaze of data quality issues.
Reactive data quality tools
While we aspire for perfection, the reality is that issues will arise. But it’s not the absence of problems that defines success; it’s how we respond.
a. Detection
The “detection” phase cannot be overstated — it’s the crucial first step in addressing data quality challenges reactively.
Data profiling
One common method is data profiling, the process of examining, analyzing, and creating useful summaries of data. It serves as a foundational technique for gaining insights into your data. Two data profiling tools you should know about are Telmai and Dataplex.
Telmai provides “No code data profiling at scale”. With Telmai you don’t need to sample your data or be limited to a subset. Telmai is built on a Spark architecture, giving you the ability to profile and investigate your data at scale and in its entirety. Telmai’s built-in AI and machine learning can investigate not only structured data, but also data that is typically dark and hard to read and parse. This includes semi-structured, 3rd party information, or user-generated tables that you don’t clearly know about. Telmai’s data profiling investigates nested structures and flags anomalies and inconsistent patterns in your data content in just minutes.

If you are a BigQuery user, Dataplex auto data quality (AutoDQ) lets BigQuery users define and measure data quality. Dataplex provides monitoring, troubleshooting, and Cloud Logging alerting that is integrated with Dataplex AutoDQ. Below is a Conceptual model of how DataPlex works.
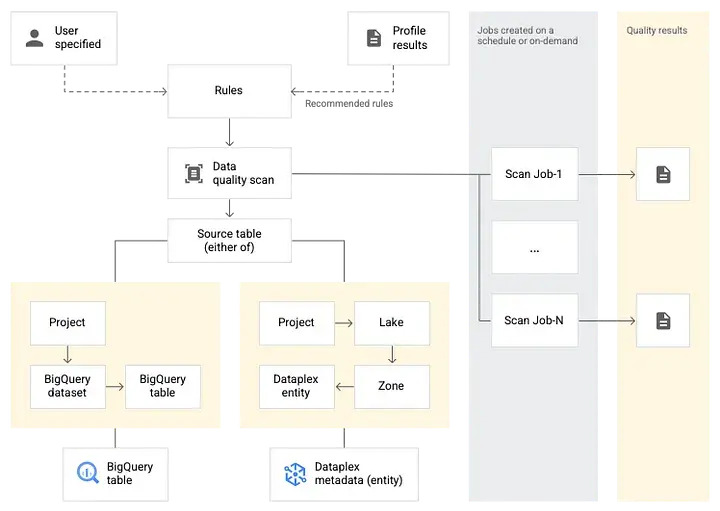
The creation and use of a data quality scan consist of Rule definition, Rule execution, Monitoring and alerting and Troubleshooting. You can learn more about DataPlex here.
Please also note that there are other open-source tools that work pretty well for data profiling, including Deequ, Great Expectations, and Soda. You can find more about the discussion about the open-sourced tools here.
b. Root cause analysis
Data Lineage
Analyzing the root cause of what went wrong requires data lineage tools. These tools enable you to follow the path of data as it passes through different systems and transformations, exposing the possible causes and origins of data quality problems.
Use DataHub as your data lineage tool, an open-source metadata platform for the modern data stack. Types of lineage connections supported in DataHub are:
- Dataset-to-dataset
- Pipeline lineage (dataset-to-job-to-dataset)
- Dashboard-to-chart lineage
- Chart-to-dataset lineage
- Job-to-dataflow (dbt lineage)
Please note that DataHub does not support auto data lineage tracking and you will need to edit data lineage yourself.

c. Remediation
Automating the remediation process for data quality incidents can be challenging, especially when it involves complex root cause analysis and data analysis, but one solution is implementing DataOps principles in your data pipeline.
Implementing DataOps principles with Github actions
DataOps maps the best practices of Agile methodology, DevOps, and statistical process control (SPC) to data. Whereas DevOps aims to improve the release and quality of software products, DataOps does the same thing for data products. DataOps would enable extremely high data quality and very low error rates. After a data quality incident happens, remediation is about using the automation and observability capabilities to resolve it as reliably and quickly as possible. You can use GitHub Actions to automate the remediation process.
Below is a simple example of using GitHub Actions to run the remediation script, in the case of duplicates observed in the data source. The goal is to identify and deduplicate these records to avoid downstream data quality problems.
name: Data Quality Incident Remediation
on:
push:
branches:
- main
jobs:
data_quality_incident:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: 3.8
- name: Install dependencies
run: pip install -r requirements.txt
- name: Data Quality Check
run: python data_quality_check.py
env:
DATA_SOURCE_URL: ${{ secrets.DATA_SOURCE_URL }}
- name: Remediate Data
if: failure()
run: |
echo "Data quality issue detected: Duplicate customer records!"
# Implement a Python script (deduplication_script.py) to deduplicate the dataset.
python deduplication_script.py
# Commit the deduplicated data back to the repository.
git add .
git commit -m "Data quality issue remediated (duplicate records removed)"
git push origin main
- name: Notify Team
if: failure()
run: |
echo "Data quality issue remediated!"
# Notify the data team or relevant stakeholders about the incident resolution.
- name: Notify Success
if: success()
run: |
echo "No data quality issues detected."
# Notify the team that no data quality issues were found.Preventative data quality tools
Foresight is a superpower. Anticipating challenges and building safeguards is often the difference between scaling smoothly and stumbling. The same principle applies to data. Before issues even arise, preventative data quality tools stand as our first line of defense. Think of circuit breakers that halt anomalies in their tracks, the unwavering commitment to data contracts that set clear boundaries, and unit tests that serve as our vigilant sentinels.
a. Circuit breakers
In the context of Airflow, a “circuit breaker” serves as a crucial safety mechanism, akin to its electrical engineering counterpart. Just as a circuit breaker in your home safeguards against overcurrents or shorts to prevent potential hazards like fires, a data circuit breaker in Airflow functions on a similar principle. It acts as an advanced data quality guardian, halting data processing within your Airflow DAG when data fails to meet the predefined quality and integrity criteria. This proactive measure prevents the downstream consequences of flawed data, such as providing inaccurate information to key decision-makers.
The Airflow ShortCircuitOperator can be used to build a circuit breaker. It allows a pipeline to continue based on the result of a python_callable. If the returned result is False or a falsy value, the pipeline will be short-circuited. Downstream tasks will be marked with a state of “skipped” based on the short-circuiting mode configured. If the returned result is True or a truthy value, downstream tasks proceed as normal and an XCom of the returned result is pushed. See Airflow’s documentation here.
b. Strict enforcement of data contracts
Data contracts are API-based agreements between software engineers who own services and data consumers that understand how the business works in order to generate well-modeled, high-quality, trusted, data. Data contracts allow a service to define the entities and application-level events they own, along with their schema and semantics. The implementation of data contracts falls into four phases: defining data contracts, enforcing those contracts, fulfilling the contracts once your code is deployed, and monitoring for semantic changes. Details of implementing a data contract can be found here.
c. Unit tests
Unit tests stand as the vanguard of a proactive approach, ensuring that before data even reaches its final destination, its integrity is affirmed.
dbt unit tests
Tests are assertions you make about your models and other resources in your dbt project (e.g. sources, seeds and snapshots). When you run dbt test, dbt will tell you if each test in your project passes or fails.
There are two ways of defining tests in dbt:
- A singular test is testing in its simplest form: If you can write a SQL query that returns failing rows, you can save that query in a .sql file within your test directory. It’s now a test, and it will be executed by the dbt test command.
A generic test is a parameterized query that accepts arguments. The test query is defined in a special test block (like a macro). Once defined, you can reference the generic test by name throughout your .yml files—define it on models, columns, sources, snapshots, and seeds.
-- Refunds have a negative amount, so the total amount should always be >= 0.
-- Therefore return records where this isn't true to make the test fail
select
order_id,
sum(amount) as total_amount
from {{ ref('fct_payments' )}}
group by 1
having not(total_amount >= 0)Generic tests
Certain tests are generic: they can be reused over and over again. A generic test is defined in a test block, which contains a parametrized query and accepts arguments. It might look like this:
{% test not_null(model, column_name) %}
select *
from {{ model }}
where {{ column_name }} is null
{% endtest %}Deequ
Deequ is being used internally at Amazon for verifying the quality of many large production datasets. Dataset producers can add and edit data quality constraints. The system computes data quality metrics on a regular basis (with every new version of a dataset), verifies constraints defined by dataset producers, and publishes datasets to consumers in case of success. In error cases, dataset publication can be stopped, and producers are notified to take action- So that data quality issues do not propagate to consumer data pipelines, reducing their blast radius.
Here is an example of defining assertions on the data distribution as part of a data pipeline. For writing tests on data, we start with the VerificationSuite and add Checks on attributes of the data. In this example, we test for the following properties of our data:
- There are at least 3 million rows in total.
- review_id is never NULL.
- review_id is unique.
- star_rating has a minimum of 1.0 and a maximum of 5.0.
- marketplace only contains “US”, “UK”, “DE”, “JP”, or “FR”.
- year does not contain negative values.
import com.amazon.deequ.{VerificationSuite, VerificationResult}
import com.amazon.deequ.VerificationResult.checkResultsAsDataFrame
import com.amazon.deequ.checks.{Check, CheckLevel}
val verificationResult: VerificationResult = { VerificationSuite()
// data to run the verification on
.onData(dataset)
// define a data quality check
.addCheck(
Check(CheckLevel.Error, "Review Check")
.hasSize(_ >= 3000000) // at least 3 million rows
.hasMin("star_rating", _ == 1.0) // min is 1.0
.hasMax("star_rating", _ == 5.0) // max is 5.0
.isComplete("review_id") // should never be NULL
.isUnique("review_id") // should not contain duplicates
.isComplete("marketplace") // should never be NULL
// contains only the listed values
.isContainedIn("marketplace", Array("US", "UK", "DE", "JP", "FR"))
.isNonNegative("year")) // should not contain negative values
// compute metrics and verify check conditions
.run()
}
// convert check results to a Spark data frame
val resultDataFrame = checkResultsAsDataFrame(spark, verificationResult)Great Expectations
Great Expectations (GX) helps data teams build a shared understanding of their data through quality testing, documentation, and profiling. It offers a collection of standard “unit tests” that can be utilized for data, simplifying the process of applying these tests in versatile manners. For example, you can use expect_column_distinct_values_to_be_in_set to check the set of distinct column values to be contained by a given set. Here is an example:
# my_df.my_col = [1,2,2,3,3,3]
>>> my_df.expect_column_distinct_values_to_be_in_set(
"my_col",
[2, 3, 4]
)
{
"success": false
"result": {
"observed_value": [1,2,3],
"details": {
"value_counts": [
{
"value": 1,
"count": 1
},
{
"value": 2,
"count": 1
},
{
"value": 3,
"count": 1
}
]
}
}
}For a deeper dive into the comparison of these three tools, you can find my previous article here.
The crown jewel in your toolbox? Data observability platform Telmai

In our exploration of data quality tools, one overarching theme emerges: the paramount importance of visibility and insight into your data ecosystem. While individual tools play crucial roles in detection, prevention, and testing, the crown jewel in your toolbox should be a data observability platform. I invite you to experience the transformative power of data observability with Telmai. Request a demo today.
Passionate about data quality? Get expert insights and guides delivered straight to your inbox – click here to subscribe to our newsletter now.
- On this page
See what’s possible with Telmai
Request a demo to see the full power of Telmai’s data observability tool for yourself.


