How to solve data quality issues at every lifecycle stage
Data quality issues, whether they stem from missing values or transformation inconsistencies, can greatly influence downstream decision-making. To safeguard your data as a crucial resource, we’ll explore frequent data quality challenges that arise throughout the data journey and their solutions.


Whether it’s missing values from data sources or inconsistencies during transformation, data quality issues can significantly impact decision-making downstream.
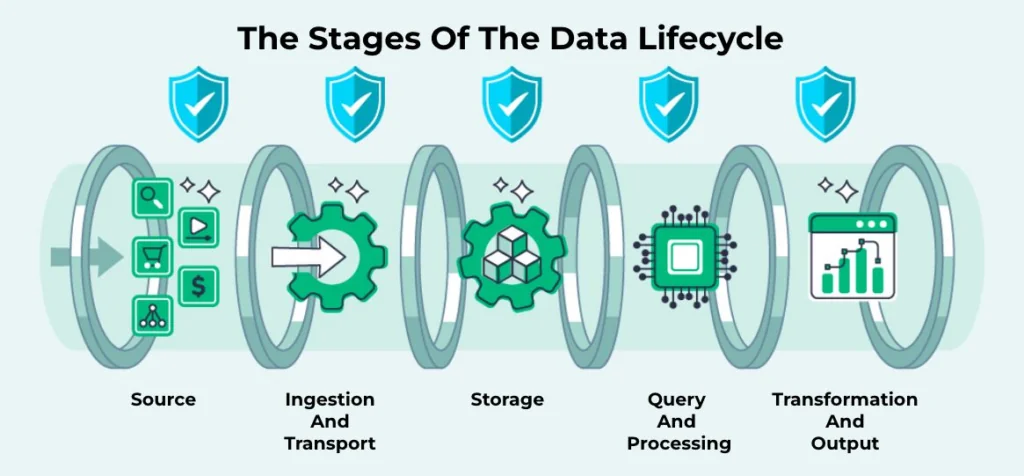
To ensure your data remains a valuable asset, let’s look at the most common data quality problems that pop up at different points in the data journey and how to solve them.
Data quality issues at the data source
Imagine you’re an owner of an e-commerce shop. Potential data quality issues you would face from data sources include:
- Null Values: Data sources may contain missing or null values, which can impact data completeness and affect downstream analysis. For instance, in the customer database, some customer records may have missing email addresses or incomplete contact information. These null values can hinder personalized marketing efforts and affect customer communication.
- Volume: Data volume inconsistencies can occur when a broken token, changes in third-party APIs, or the failure of a single microservice results in incomplete records. This can lead to sudden drops in data volume, impacting the reliability of analytics and reporting. For instance, if an e-commerce platform experiences a token issue with a payment gateway, it may fail to capture transaction data, causing an unexpected decrease in sales data volume.
- Uniqueness: Ensuring data uniqueness is essential to avoid duplications and maintain accurate records. For example, in the product table, each Stock Keeping Unit (SKU) should ideally have one unique record. The SKU serves as a distinct identifier for each product and is used for inventory management, order processing, and tracking. Without proper deduplication, the platform may erroneously count the same customer multiple times, leading to inaccurate customer metrics and sales reporting.
- Accuracy: For example, in the product table, the sales price of a product cannot be negative. It would be an anomaly for the price and may cause problems for the downstream revenue analysis.
Data quality issues during ingestion
During this stage, raw data is captured from its origin, whether it be sensors, applications, databases, or external data providers, and is then transferred to a centralized data repository, such as a data warehouse or data lake. Proper handling during this stage is crucial to maintain data quality throughout the entire data lifecycle.
Some issues you have to watch out for during ingestion include:
- Data Format Incompatibility: When customer data is ingested from different sources, each source may use varying data formats, such as CSV, JSON, or XML. Integrating and processing data with incompatible formats can lead to parsing errors and data loss during ingestion, hindering the platform’s ability to create a cohesive view of customer information.
- Data Loss or Duplication: Insufficient error handling during data ingestion can result in data loss or duplication. For instance, if a connection error occurs during the ingestion process, some sales transaction data might be lost, leading to incomplete sales records. Conversely, if data ingestion processes are not carefully managed, duplicated data entries may be created, leading to redundant customer records and skewed analytics.
- SLA / Freshness not met: The Service Level Agreement (SLA) for data freshness may not be met during data ingestion. For example, if real-time data is required for analyzing customer behaviour, delays in data ingestion may lead to outdated insights and impact the platform’s ability to make timely decisions.
- Data Schema Mismatches: Differences in data schema between the source and destination systems can cause data mapping errors during ingestion. For instance, if product attributes are named differently in the source and destination databases, this could lead to incorrect data interpretation.
Data quality issues during transport and storage
Proper data transport mechanisms are essential to prevent data breaches, corruption, or loss during transit. Then once data reaches its destination, it has to be stored in a way that’s both accessible and scalable, while guarding against potential threats to ensure its longevity and usability.
The two most common issues you may run into:
- Data Inconsistency: Data inconsistency can occur when data is stored in different storage systems, such as S3 and Snowflake, leading to mismatched or conflicting data. This can happen due to differences in data formats, data transformations, or data processing pipelines between the source and destination systems. Also when data is replicated between storage systems, errors may occur, resulting in discrepancies and inconsistencies in the replicated data.
- Partial Write Job Failures: Network issues, such as data pipeline failures or write jobs running only partially before failing, can disrupt data transportation. These issues result in incomplete data transfers, leading to inaccuracies in the destination systems. For example, if network interruptions occur while transmitting customer order data, it can result in incomplete or missing order records in the database, impacting the downstream data pipeline and the related analysis.
Data quality issues during transformation
Transformation is a bridge between raw, often messy data and structured, usable data. It’s a stage where data is molded, refined, and prepared for its end purpose, be it analytics, machine learning, or any other form of data utilization. Properly transformed data ensures that subsequent stages in the data lifecycle, like analysis and visualization, are effective and meaningful.
Data quality issues you may encounter during the transformation process include:
- Data Loss: Incorrect data transformation logic or mapping can lead to data loss, where essential information is unintentionally omitted during the transformation process. Suppose during the transformation process of the “Order” table, there’s an error in the transformation logic responsible for consolidating order information. If this logic is not designed to properly capture and integrate shipping addresses, it may inadvertently omit critical shipping address information when consolidating order records. As a result, the e-commerce platform may end up with incomplete order records that lack essential details needed for accurate order fulfillment and delivery tracking.
- Data Inconsistency: Inconsistent transformation rules applied to different datasets can lead to discrepancies and inconsistencies in the transformed data. Considering the “Product Catalog” schema within the e-commerce platform, inconsistent transformation rules may lead to varying product categorizations and naming conventions. For instance, naming conventions for products might vary, with similar items being referred to differently causing discrepancies in product listings.
- Data Format Errors: Incorrect data formatting during transformation can result in issues like date format discrepancies or numeric data stored as text.
- Data Duplication: Improper transformation logic can cause data duplication, leading to redundant entries in the transformed dataset. Suppose the transformation process involves merging customer data from multiple sources into the “Customer” table. If the transformation logic lacks proper deduplication mechanisms, it may inadvertently create duplicate customer entries for individuals who exist in more than one data source.
- Data Aggregation Errors: Aggregating data using incorrect methods or criteria can lead to erroneous summary statistics and analysis. Consider the “Sales Reports” table within the e-commerce platform, where monthly sales totals are calculated. If there are errors in aggregating sales data using incorrect methods or criteria, it can significantly impact the accuracy of summary statistics.
- Business Rule Violations: Data transformation processes that do not adhere to defined business rules or constraints can lead to data quality issues and misinterpretation of results. In the “Pricing” schema of the e-commerce platform, an erroneous transformation process results in negative prices for products. For instance, a product originally priced at $50 is transformed into a negative price of -$10.
- Data Joins and Merging: Incorrect data joins or merging of datasets can lead to data integration issues and inaccurate insights. Within the “Order Fulfillment” records of the e-commerce platform, improper data joins or merging of datasets can specifically affect the integration of “Shipment Details.” An example can be that during the merging process, shipment records are incorrectly associated with orders that they don’t correspond to.
Analysis and output
The “Analysis and Output” stage of the data lifecycle moves the emphasis to producing reports from the processed data and drawing useful conclusions from it. While there might be fewer apparent data quality issues, a challenge known as business metric drift can emerge. For instance, consider a historical revenue range of $1–3 million per month, suddenly dropping to $400k. These situations often require a deeper contextual understanding and more comprehensive post-processing and transformation efforts.
It’s important to highlight that if data quality issues are discovered at this late stage, it may be expensive and difficult to fix them. Determining and resolving data quality concerns at early phases of the data lifecycle, such as data sourcing, ingestion, and transformation, becomes crucial.
Monitor data quality on a continuous basis
Given all the ways that data quality can be compromised – and that it’s constantly in motion – how can you keep a vigilant eye?

Enter Telmai, a cutting-edge data observability tool designed to monitor your data continuously and ensure impeccable data quality.
By continuously monitoring your data, Telmai identifies and alerts you to any anomalies in real time, ensuring that you’re always working with the most accurate and reliable data. Whether it’s spotting missing values, detecting format inconsistencies, or ensuring data freshness, Telmai has got you covered.
But what truly sets Telmai apart is its user-friendly interface and powerful AI-driven analytics. By leveraging advanced machine learning algorithms, Telmai can predict potential data quality issues before they even arise, allowing you to address them proactively. Furthermore, with its intuitive dashboard, you can easily visualize your data’s health, track its lineage, and gain insights into its quality metrics.
Ready to elevate your data game? Try Telmai today and make data mishaps a thing of yesteryear.
Passionate about data quality? Get expert insights and guides delivered straight to your inbox – click here to subscribe to our newsletter now.
- On this page
See what’s possible with Telmai
Request a demo to see the full power of Telmai’s data observability tool for yourself.



