
For years, data quality has been framed as a reporting problem. Analysts review dashboards, business leaders ask questions, and when something looks off, someone investigates. That model worked when data was primarily consumed by humans.
In a recent webinar, Max Lukichev, CTO and Co-founder at Telmai, and Saravana Omprakash, Co-founder at DataColor AI, made a compelling case that this approach is fundamentally broken in the age of agentic AI.
Enterprise data usage has fundamentally changed. Data is no longer accessed by a small set of known consumers on a periodic basis. It is now used broadly, continuously, and often autonomously by AI agents embedded across workflows.
This shift alone breaks most traditional data quality models. But it also forces a deeper question. If machines are acting on data directly, what does it actually mean to trust that data?
That question sits at the center of the 2026 data quality blueprint.
Why the Old DQ Playbook Fails in the Agentic Era
The classic data quality model evolved around business intelligence. Data was curated, aggregated, and periodically reviewed through reports. In practice, this meant rule-heavy frameworks that validated tables at the end of the pipeline, typically in the data warehouse. If an issue surfaced, teams had time to investigate, add a rule, and move on.
But agentic AI has shattered that predictability. As Max put it bluntly during the discussion, “Now everyone is building agents, right? You have nearly everyone on a team building something to address a narrow task. The impact of these agents is much broader, given their access to data. You kind of don’t even know how this data is being used, by whom, what decisions are being made.”
Saravana captured another dimension of this failure: many organizations respond by scaling rules instead of strategy. “One of the things I’ve observed is that organizations take a very table-schema focused approach,” he explained. “They say, ‘I’ve got 20 schemas, I’ve got 500 tables—let me run 2000 rules on top of them,’ instead of asking what’s actually important for the business.”
This shotgun approach to blanket rules across every table in the warehouse misses the forest for the trees. It’s reactive, expensive, and ultimately ineffective because it treats all data as equally important. But as both speakers emphasized throughout the conversation, you cannot boil the ocean.
In an agentic environment, data quality can no longer be reactive. Once an agent has acted on bad data, the damage is already done.
From Table-Centric Rules to Business-Centric Trust
So what does a business-first approach look like?
Saravana articulated a principle that became a throughline in their discussion. “What I have seen successfully implemented as DQ initiatives that can translate into business outcomes has been the fact that taking a KPI-first, or a metric-first kind of data quality approach,” he explained. “Because it is not about whether I’ve got the right rules. It is about whether those rules align with your business outcomes. That way, you’re focused with your energies on trying to look for the checks that need to be done on that entire pipeline of the data that matters.”
Once those questions are answered, data quality becomes purposeful. Checks are no longer generic. They are aligned to business impact. When something breaks, teams know why it matters, who it affects, and what needs to happen next.
Max reinforced this idea from a different angle. In complex enterprise environments, trying to validate everything equally is not just inefficient; it is impossible. This business-first, KPI-aligned approach enables the next shift in the blueprint. Rules alone are not enough. Observability is critical for detecting issues as they emerge, often before explicit rules are in place. Changes in volume, distribution, freshness, or structure can be identified early, without writing thousands of downstream checks.
As Max emphasized, “You cannot boil the ocean. You cannot solve it everywhere. You have to identify and isolate areas where it has the most impact.” What works instead is a decision-first approach:
- Identify the KPIs, metrics, and decisions that actually matter
- Trace the data paths that feed those decisions
- Focus quality, observability, and governance efforts there
This reframes data quality from a volume problem to an impact problem. You don’t need perfect data everywhere; rather, you need trustworthy data where decisions are made. In an agentic world, that prioritization becomes essential. You simply cannot afford to monitor everything equally, nor should you try.
Why Observability Must Shift Left
With the business context established, the conversation turned to architecture: where in the data pipeline should quality checks actually live?
By the time data reaches the warehouse, it has already passed through ingestion, transformations, joins, and aggregations. Simple upstream issues, like schema drift or missing records, are often masked by these layers, leaving teams with fewer signals and more complex failures to debug.
Shifting observability left fundamentally changes the economics of data quality. As Max explains, “The earlier you plug observability into the pipeline—closer to ingestion—the more proactive it becomes. Those simple problems can be detected automatically before transformations hide them. Otherwise, you only have one choice left: writing more rules downstream.”
At the raw data layer, anomalies are easier to detect automatically. A sudden drop in record count or an unexpected schema change at the landing zone takes minutes to detect and investigate. The same issue, discovered three transformations later and buried in aggregated warehouse tables, might take hours or days to trace back to its source. This upstream approach reduces the need for an ever-growing library of downstream rules while enabling teams to act before bad data propagates. The data speaks for itself if you’re listening at the right place.
Saravana expanded on the strategic value of this upstream approach, particularly when combined with lineage tracking. “The lineage view of basically the entire pipeline and incidents that are being tracked at the observable data being observed upfront on the left-hand side could also be a very good way to do root cause analysis of things that happen on the right-hand side.”
But Max emphasized that shift-left doesn’t mean abandoning rules entirely. “You cannot get rid of rules completely. You cannot implement rules everywhere. It requires balance, and you need to bring a lot of observability concepts upstream to the ingestion layer, but you also don’t want to overextend yourself and start monitoring where it doesn’t matter or where the impact is less.”
Saravana summarized this as moving from snapshot-based validation to continuous monitoring. Not just catching issues earlier, but avoiding reactive firefighting altogether.
Trust Scores: Making Data Quality Consumable by AI
Humans are remarkably good at working around imperfect data. They notice trends, ask follow-up questions, and apply intuition. Saravana drew an analogy that crystallized the concept: “It’s like basically taking a diagnostic test on somebody and you have a reference range and you basically have your score to say you are healthy, you’re not healthy.”
“In this new era where data is being used by AI, by AI agents, by ML workloads that are basically taking it without providing objective ways of measuring whether the data is trustworthy or not in a consistent way, on an ongoing basis,” Saravana continued, “these machines will find it difficult to consume and provide reliable answers.”
Max grounded this abstract concept in a concrete example to highlight that the stakes escalate when you automate, which many finance teams would immediately recognize. “Imagine now you have agents that automate these processes for you, automatically paying vendors, automatically making some decisions. If they go unchecked, you can get in big trouble.” This is the fundamental risk of agentic AI: autonomous action exponentially amplifies the impact of data errors.
Max emphasized that trust scoring is at a level of granularity that traditional DQ never contemplated. “The trust scores are now at the record level. It’s not that my table looks good, because now you are taking actions based on individual elements, like individual records, customers, vendors, whatever. So you have to evaluate all of this data at much finer granularity, calculate those trust scores, highlight potential issues, and stop agents from doing something they were not supposed to do to avoid all of those compliance problems.”
This record-level scoring transforms data quality from a passive health check into an active input for decision-making. An agent doesn’t just retrieve a vendor’s payment information—it also receives a trust score indicating whether the record is reliable enough to act on. If the score falls below a threshold, the agent can escalate to human review rather than blindly executing a potentially erroneous transaction.
The 2026 Blueprint: Continuous, Contextual, and Consumable
Saravana crystallized the modern data quality blueprint into three essential characteristics that differentiate it from legacy approaches.
- It is continuous, not snapshot-based
- It is context-aware, aligned to business decisions
- It is machine-consumable, designed for AI systems — not just humans
In AI-native environments, detecting a data issue isn’t enough. The real challenge is how quickly teams can understand the impact, identify the root cause, and take corrective action, often across multiple systems.
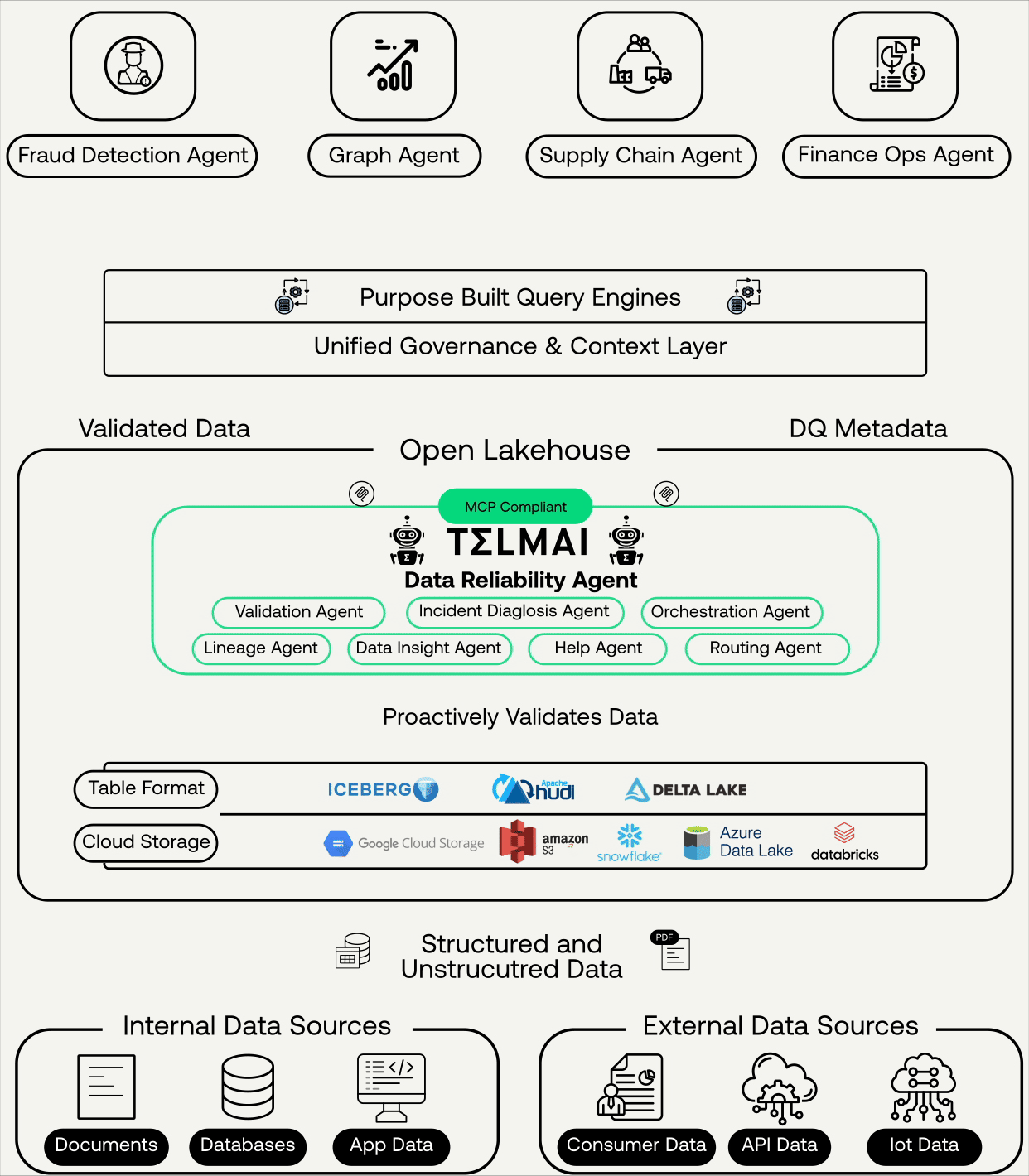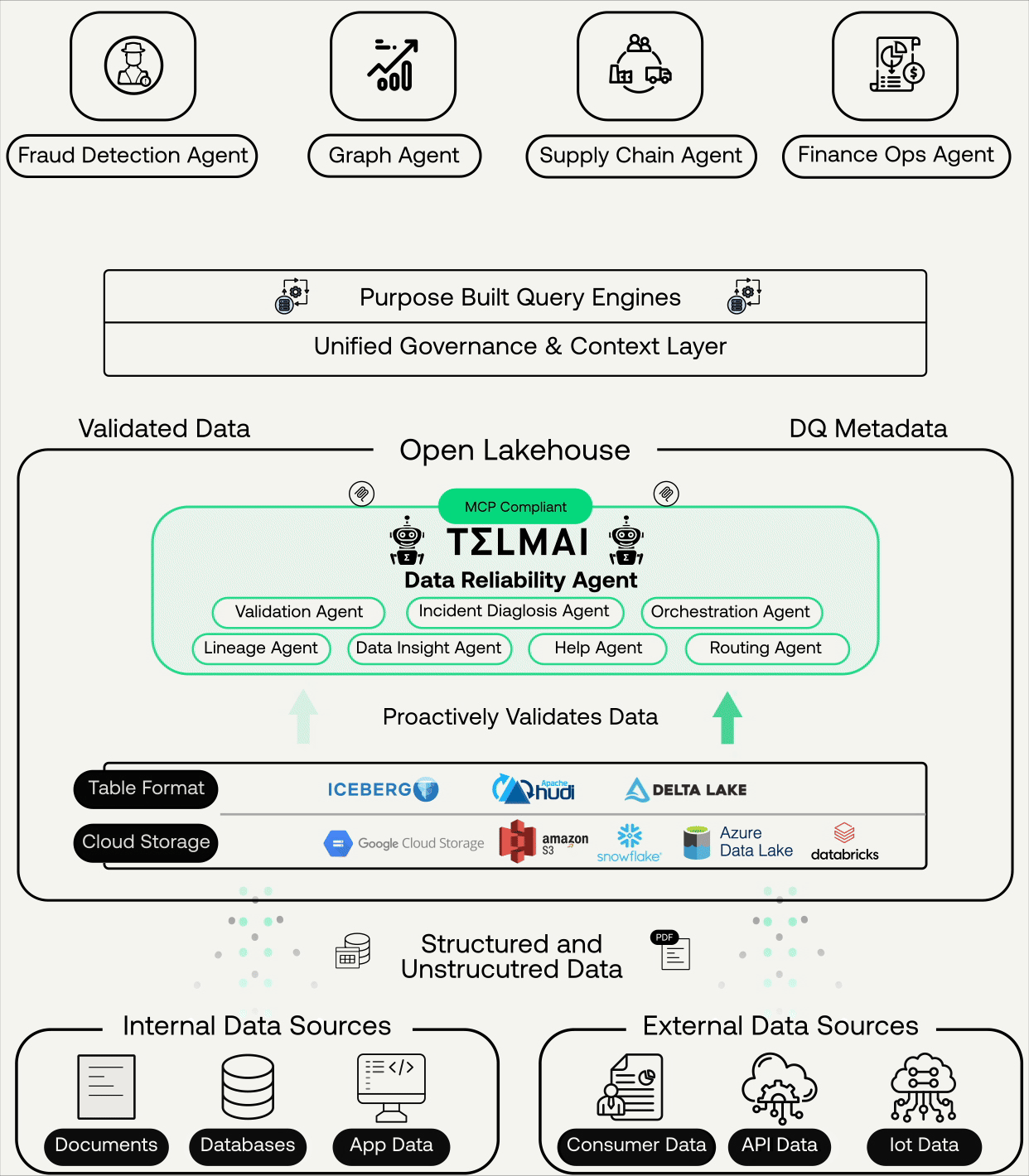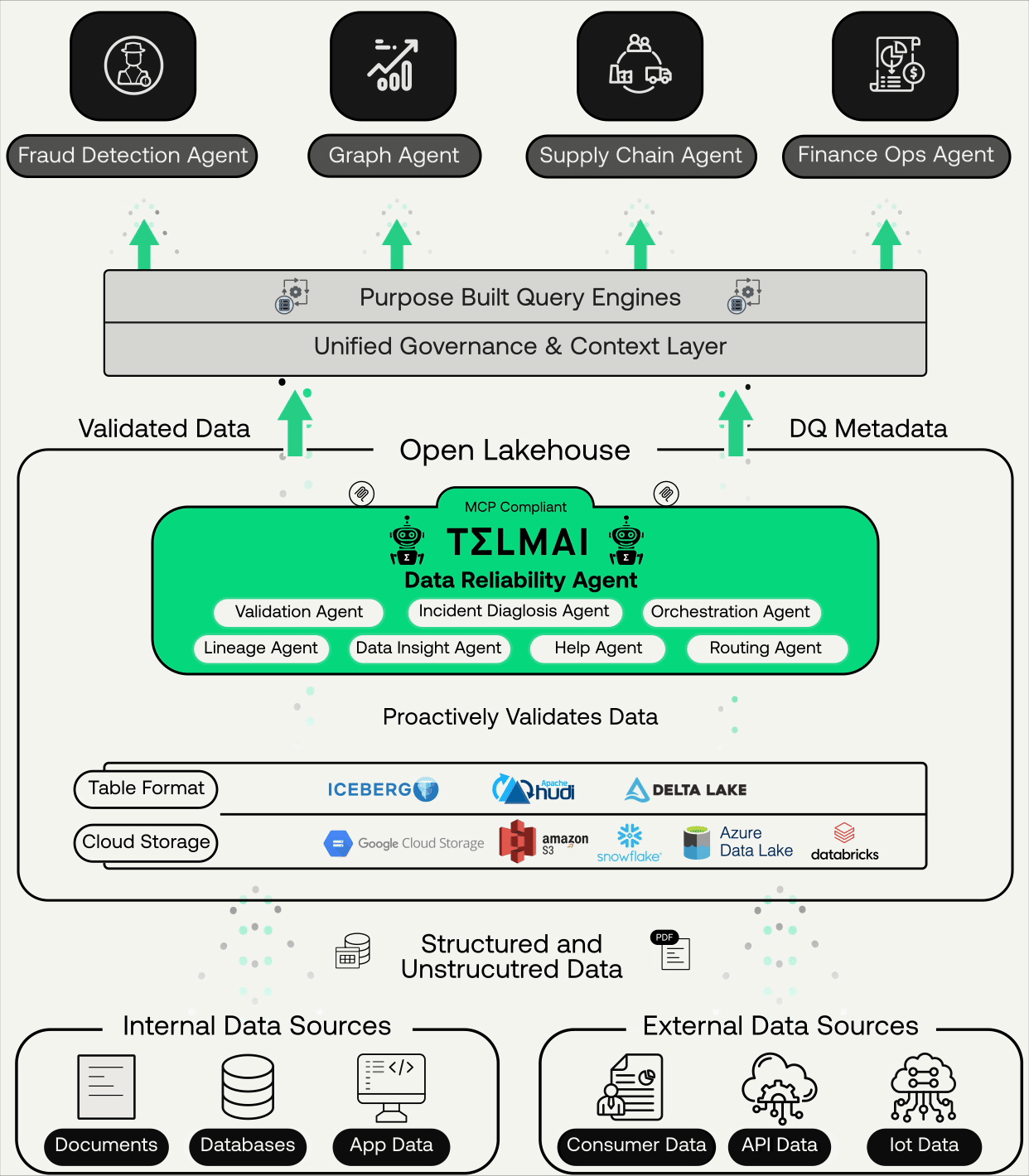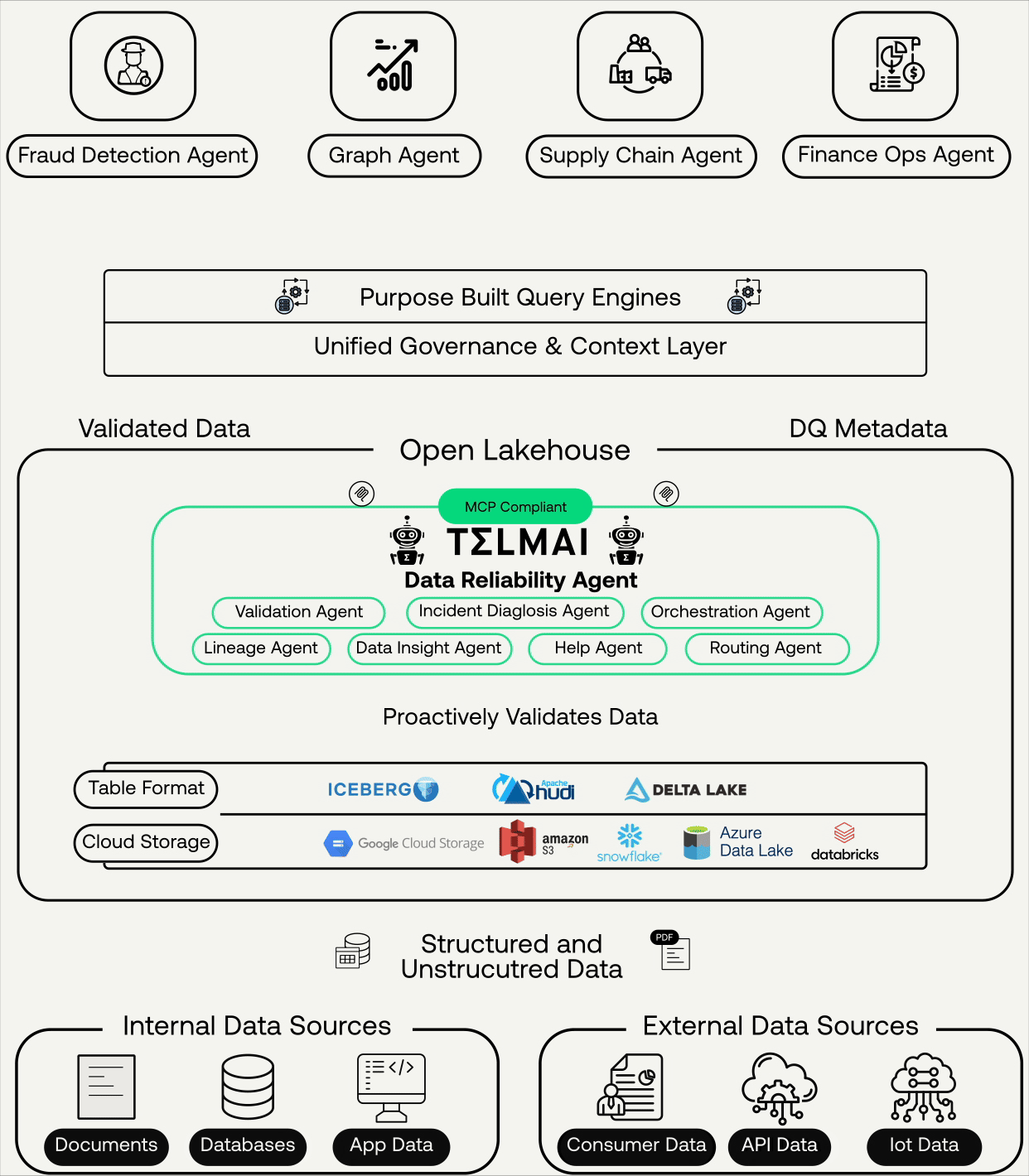
This is where modern data approaches converge, integrating:
- Data observability
- Lineage
- Incident context
- AI-assisted analysis and remediation
Instead of relying on institutional knowledge scattered across teams, AI systems can now reason over this context, suggest fixes, and even automate parts of the resolution process with humans staying in the loop where it matters. Data quality becomes part of an execution fabric, not a reporting layer.
Building Trust as Infrastructure
As enterprises race to deploy agentic AI across all domains, the organizations that succeed will be those that recognize a simple but profound truth: the agent is only as good as the data behind it.
In the world of autonomous systems making real-time decisions, trust is infrastructure. It must be continuous, contextual, and consumable by the very systems that depend on it. Building that infrastructure requires rethinking data quality from the ground up.The question for most enterprises isn’t whether this transformation is possible, but how quickly they can execute it before their AI initiatives outpace their data quality foundations.
At Telmai, this blueprint directly informs how we approach data quality in AI-native environments.
- Rather than treating data quality as a downstream control, our focus is on establishing trust early—at the ingestion layer of the data lake
- Extending quality and observability beyond structured tables to unstructured inputs like documents, logs, and conversations
- DQ patterns that can surface, isolate, and contain issues before autonomous systems act on them
This is how enterprises will scale agentic AI safely by building on trusted, validated, context-rich data.
Because in the agentic world, it’s not enough for AI to be smart. It has to be confident. Click here to speak with our team of experts to learn how leading enterprises are building trusted data foundations for agentic AI.



