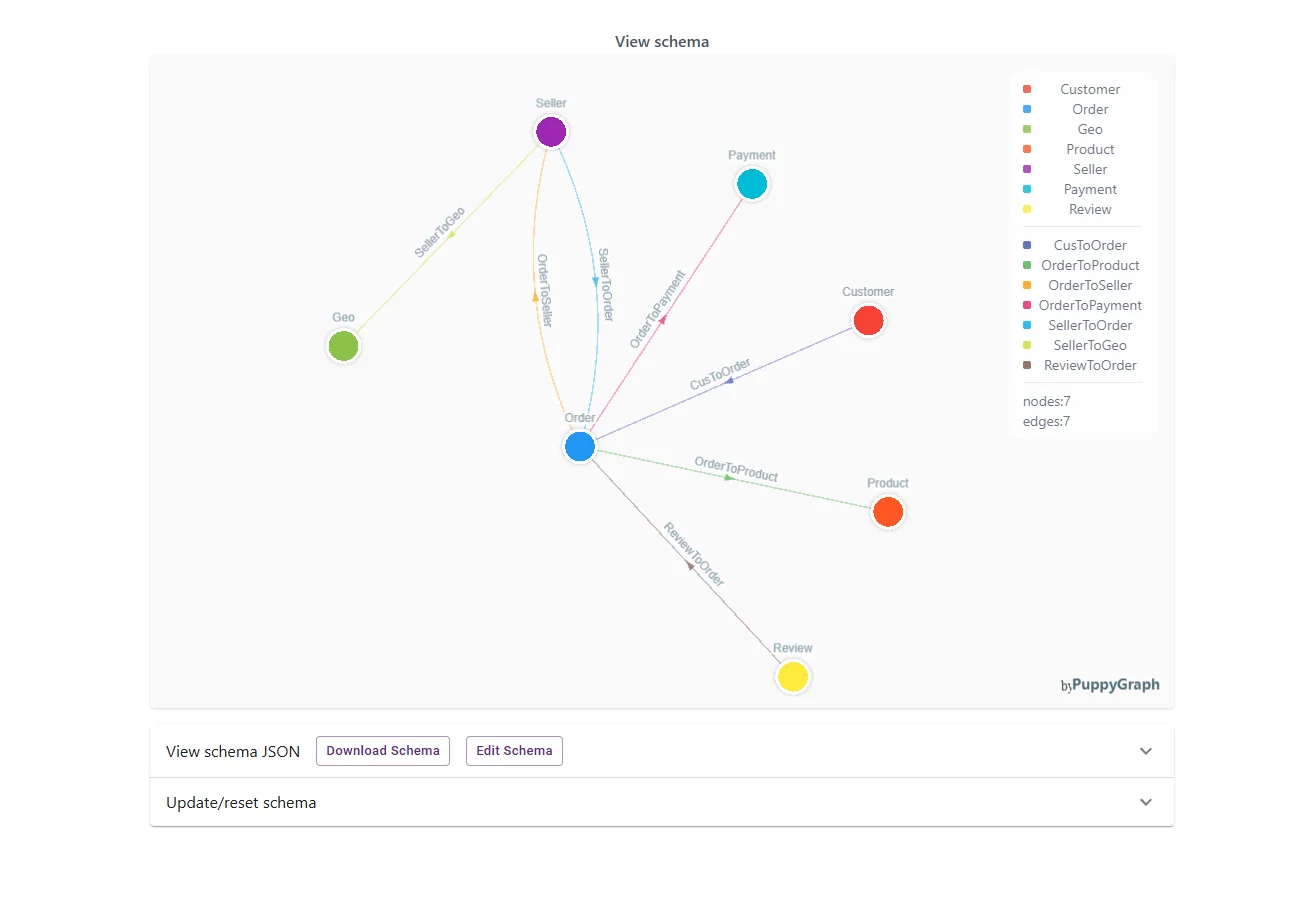
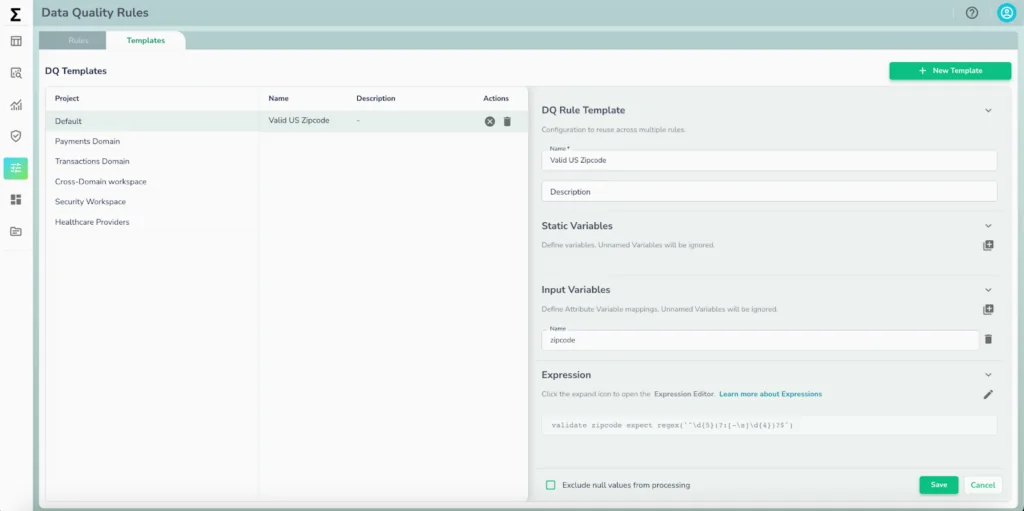
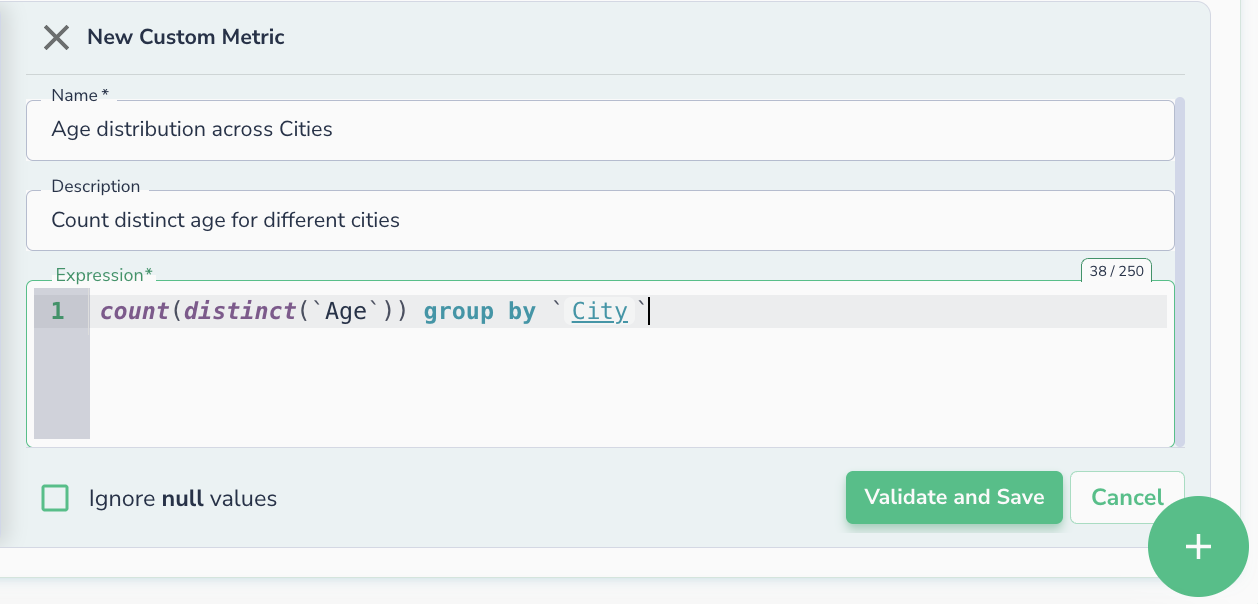
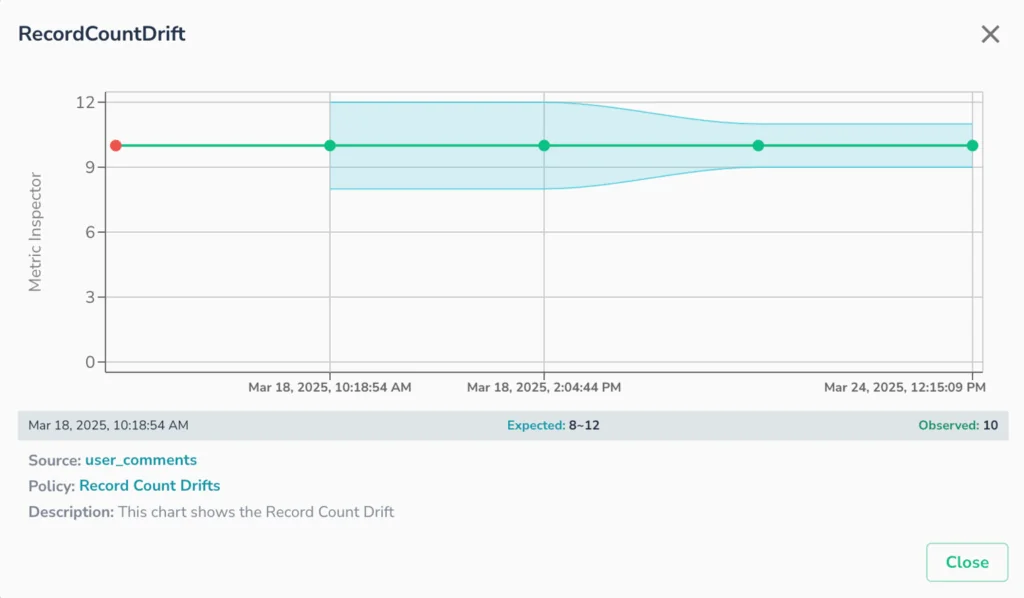
As Agentic AI adoption accelerates, the industry conversation is shifting from “Can we build AI?” to “Can we trust it?”
In the latest episode of our Data Quality podcast series, Telmai’s CEO and co-founder, Mona Rakibe, joined Ravit Jain, Alex Merced, and Scott Haines to explore how open lakehouse architectures are becoming foundational for sustainable Agentic AI infrastructures. They also highlighted critical considerations for architecting agentic infrastructures where autonomous systems and workflows don’t just analyze data, but act on it in a deterministic and trusted manner.
“Agentic-Ready” Starts With Reliable Contextual Data
“Agent-Ready” data isn’t something entirely new, it’s simply well-prepared data elevated for a new level of responsibility. Yet as AI systems evolve from analytical to autonomous, the stakes rise dramatically.
“At the end of the day, all AI is doing is understanding your data just faster,” said Alex Merced, Head of Developer Relations at Dremio. “It’ll get to the right answer faster or the wrong one faster, depending on your data quality. That means everything we’ve always cared about, accuracy, cleanliness, and semantic definitions, now matters a lot more.”
Mona Rakibe expanded on this idea, “The biggest mental shift is understanding that for agents to be truly autonomous, the data powering them must be reliable and enriched with context. It’s no longer enough to have dashboards; the data pipeline itself needs to be self-healing and self-validating.”
This shift is fundamental, as agents interact dynamically with data across diverse domains, demanding real-time observability and proactive governance. Scott Haines echoed this sentiment, noting how teams are “giving up control” to automated systems, which makes the need for guardrails and testable context even more urgent. “You have to ensure your workflows behave predictably, that’s what makes the difference between a trusted agentic ecosystem and one that’s just automated chaos,” he said.
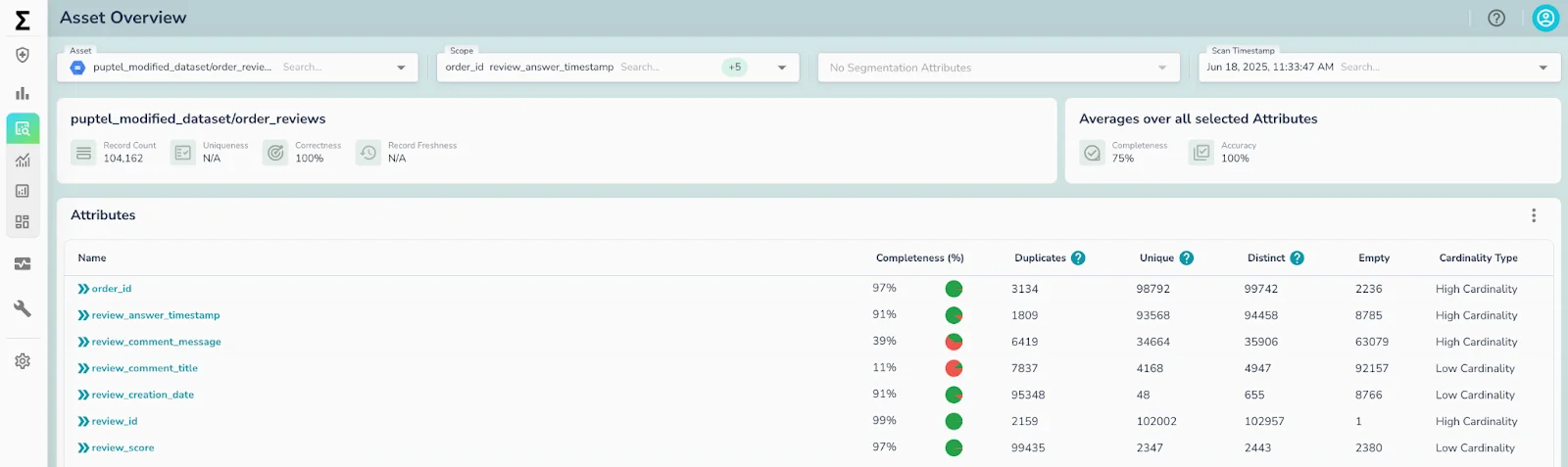
Building “AI-ready” or “agentic AI-ready” data isn’t just about accuracy, it’s about real-time reliability and contextual awareness. Systems must now deliver machine-consumable metadata, continuous validation, and semantic consistency at the speed of automation. In this world, data trust isn’t an afterthought, it needs to be baked into your data infrastructure.
Open Lakehouses: The Foundation for Trusted and Autonomous AI
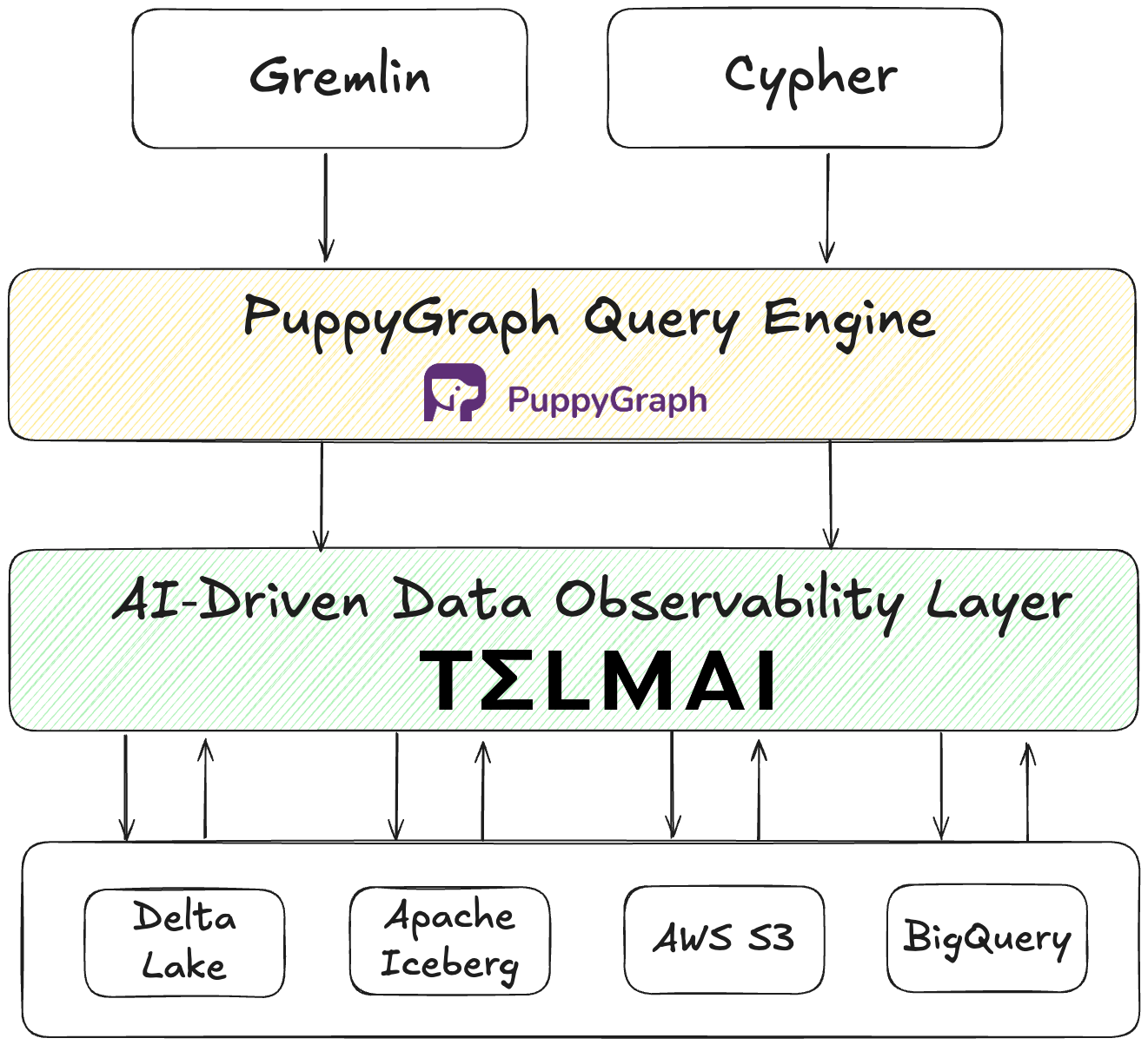
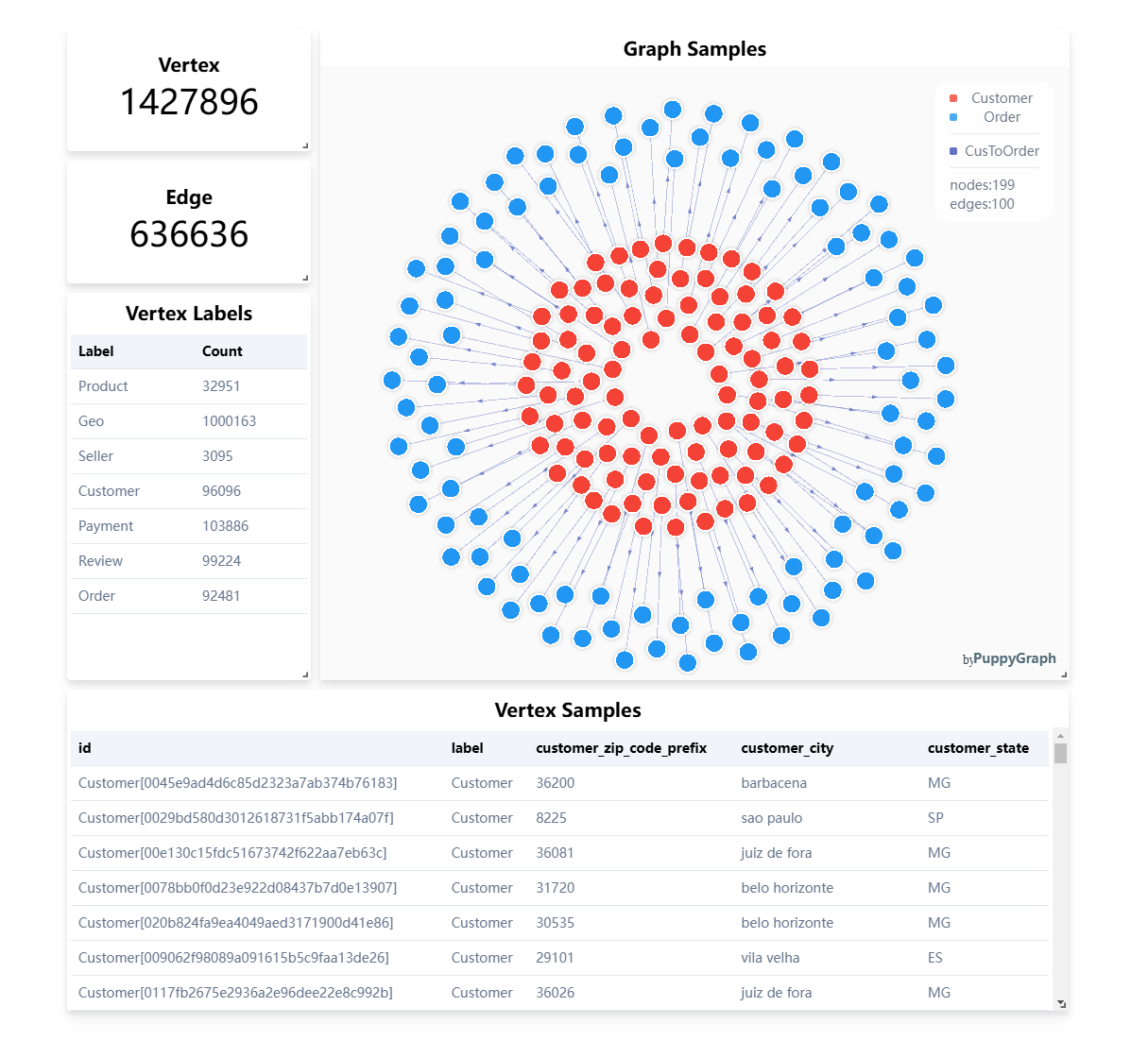
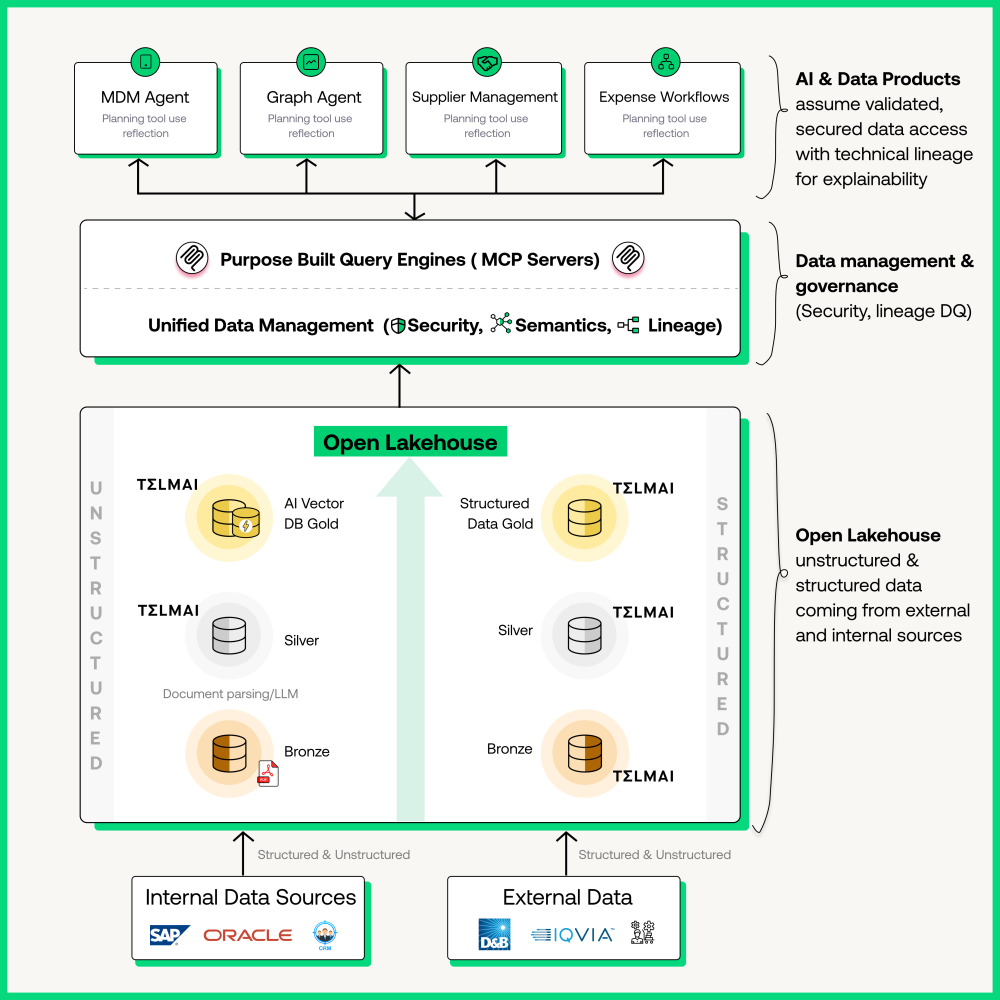
If the first step toward Agentic AI is reliable contextual data, the next is an open architecture that makes that trust accessible across every system, use case, and engine. As Mona Rakibe put it, today’s enterprises are moving toward a model where “everything lives in one lake,” but the engines and intelligence around that data are increasingly decoupled and composable.
“Historically, we used to ETL data, model it, and make it fit for purpose for every single use case,” she explained. “Now, what I’m seeing is a shift toward standardized open formats — Iceberg, Delta, Hudi — where data can be dumped into a lake and processed as-is. The models themselves are smart enough to handle JSON or XML, so the transformation moves closer to the use case. That’s where zero-ETL and zero-copy architectures are becoming real.”
Alex Merced expanded on this, noting that the goal isn’t to eliminate data movement entirely, but to reduce redundancy and preserve context throughout the pipeline. “Even if you standardize on Iceberg or Delta,” he said, “you still need to move data between systems. But the transformations themselves can become more logical or virtual. That’s why semantic layers are getting so much attention. Instead of physically transforming data, you engineer meaning over it.”
This architectural evolution, from closed, pipeline-heavy data systems to open, semantically aware ecosystems, enables AI agents to operate with both context and consistency. It ensures that the rules, lineage, and quality signals that define trusted data travel seamlessly, regardless of where or how the data is consumed.
Scott Haines, who leads developer relations at Buf, added another dimension to this openness: data contracts embedded directly into schemas.“At Buf, we created something called Proto Validate,” he explained. “It lets you embed those data contracts right inside your schema definitions, basically adding guardrails at the edge, before data even enters the lake.”This “edge validation” approach ensures that governance begins at ingestion, not after a failure has already propagated downstream. It’s a natural complement to the metadata-driven validation Mona advocates for and the semantic standardization Alex envisions.
Open lakehouses aren’t just about flexibility or performance, they’re about trust at scale. By embracing open formats, shared semantics, and embedded contracts, data teams can finally align what humans understand and what AI agents act upon. In the era of Agentic AI, interoperability becomes the new reliability, and the open lakehouse serves as the foundation for both.
Metadata, MCP, and the Headless Future of Data Quality
If open lakehouses provide the foundation for trust, metadata is what animates that trust in real time. As AI agents begin to interact directly with enterprise data, the challenge isn’t just validating accuracy it’s making validation context available instantly, wherever and whenever agents need it.
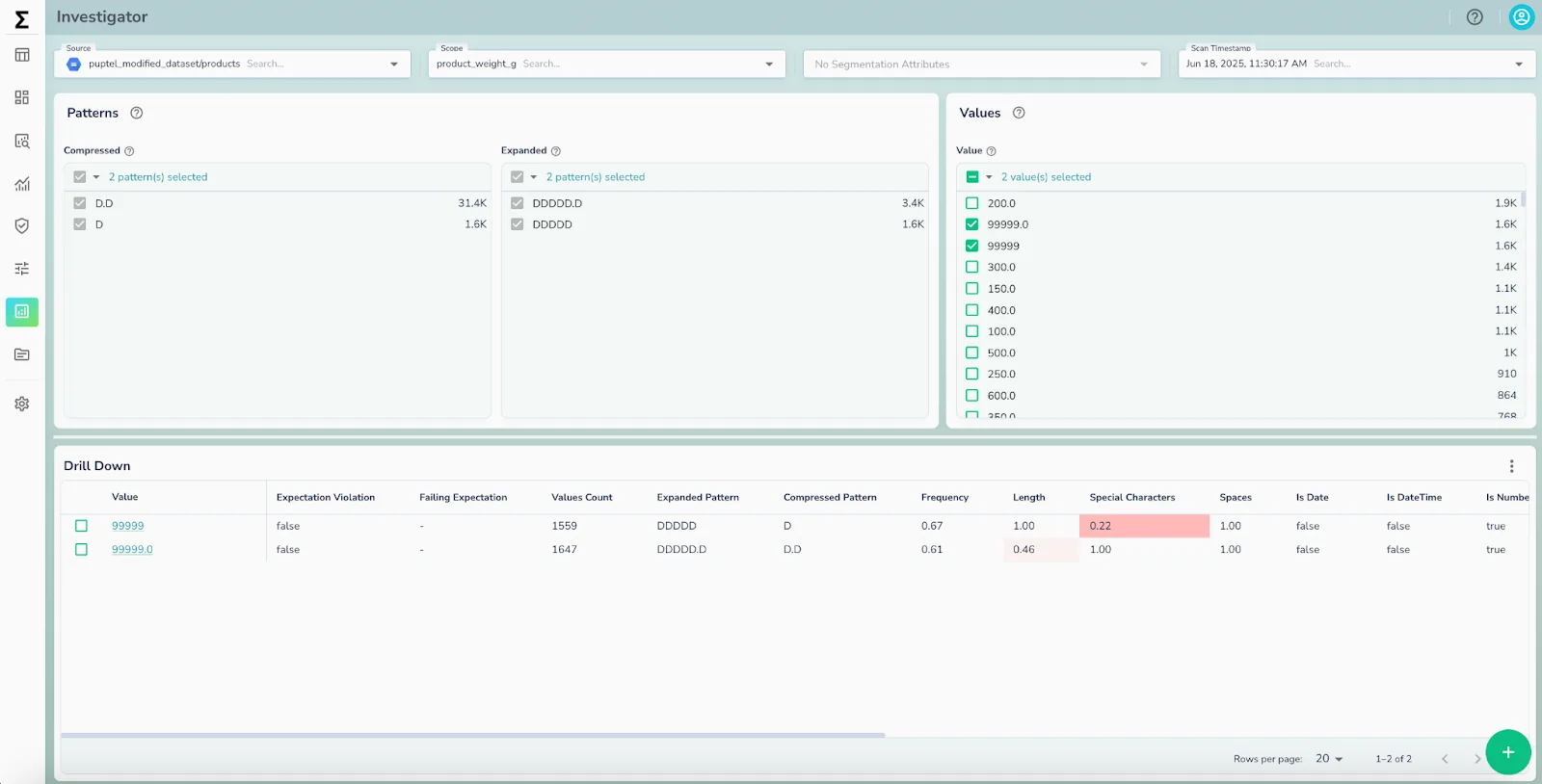
Mona Rakibe explained this shift clearly: “Unstructured data has now become a first-class citizen. The moment a PDF or a JSON file enters a pipeline, its validation becomes critical,” she said. “That validation context must also be accessible through an MCP — the Model Context Protocol — because when agents query data, they need to know which records can be trusted and which should be excluded.”
In her view, MCP represents the next evolution of interoperability, serving as a universal protocol that enables AI systems to access not only data but also its context, quality, and provenance in a standardized manner. “It’s almost like REST for AI,” Mona noted. “Everything now has to be accessible to the agent in a standardized format. It’s no longer optional.”
This real-time exposure of metadata marks the beginning of what she called the “headless data quality era.” In this model, validation isn’t something performed within a UI or a tool; it becomes an invisible, autonomous service that continuously surfaces reliability signals across every workflow, both human and machine.
“Data quality needs to become a headless application,” Mona said. “We need to get the context out as soon as data lands, make it part of the MCP so agents can operate on it. That’s the only way to make autonomous systems truly reliable.”
Alex Merced agreed, adding that headlessness isn’t limited to data quality, it’s transforming the entire data stack. “We’re walking into a world where application building is less about designing a user interface and more about building functionality,” he said. “MCP enables that. It decouples how we interact with systems from how those systems actually run.”
Scott Haines tied this back to governance and predictability, reminding that decentralization doesn’t mean disorder. NLP and automation enable teams to manage distributed quality responsibilities without compromising coherence, but metadata must remain the unifying thread. “In a world where agents can run checks and feed that context back into workflows, governance becomes a living process,” he observed — one that’s both autonomous and explainable.
Together, these ideas signal a dramatic transformation: metadata is becoming the interface between humans, machines, and trust.
Headless data quality, powered by MCP, ensures that every system, from an LLM querying customer data to an autonomous workflow reconciling transactions, has access to the same trusted, contextual truth.
From Reactive Pipelines to Autonomous Systems
For years, data quality was defined by dashboards, alerts, and manual intervention systems that reacted after something went wrong. However, in an era where AI agents process data in real-time, reactive monitoring can no longer keep pace. Enterprises now need self-governing, self-healing data ecosystems that detect, diagnose, and resolve anomalies autonomously.
Mona Rakibe described this as the natural endpoint of the shift Telmai itself has been preparing for.“We’re moving toward a world where data quality becomes autonomous,” she said. “Nobody loves doing DQ work, and that’s exactly what makes it the perfect candidate for automation. The system should be able to detect drifts, understand patterns, and correct itself without waiting for human approval.”
That autonomy, however, doesn’t mean a loss of control,it means redefining control. The goal isn’t to replace human oversight, but to embed intelligence within the data fabric, making trust continuous and invisible. In this future, metadata, lineage, and validation signals form a living feedback loop that constantly informs both human decisions and AI reasoning.
Alex Merced explained how this evolution changes the way teams build and interact with systems.“We’re walking into a world where application building is less about designing a user interface and more about building functionality,” he said. “With MCP and headless validation, the system itself becomes the interface. The agent can query, interpret, and act — and the data quality layer ensures it does so responsibly.”
The move toward autonomous trust systems also brings a cultural transformation. Teams must start designing for proactive reliability, not just reactive response. Instead of tracking SLAs and resolution times, success will be measured by how seamlessly systems prevent incidents altogether, by design, not by repair.
In the context of Agentic AI, this evolution isn’t optional; it’s existential. As workflows become more distributed and decisions become more automated, the only sustainable model is one where data quality operates as an autonomous, intelligent service that detects context, adapts to drift, and reinforces trust without human bottlenecks.
Ultimately, this is where observability meets agency. The systems that once monitored data will now reason about it, closing the loop between awareness and action, and transforming trust from a static KPI into a continuously orchestrated state.
Democratizing Data Quality in the Agentic Era
As architectures evolve and data quality becomes autonomous, one challenge persists: who owns trust? For years, organizations have swung between centralized governance and decentralized accountability, both with their trade-offs. Centralization brought standardization but lacked context; decentralization gave teams control but often led to inconsistency.
Mona Rakibe captured this tension perfectly.“Initially, data quality was centralized, which nobody liked — the people who owned it didn’t have the context. So we tried to decentralize. But then the teams who had the context struggled with SQL or with using yet another tool. Data quality wasn’t part of their KPIs; they just wanted to build and ship products.”
Her point underscores a reality that many enterprises face: data quality can’t thrive as an isolated function. It must live within the workflows where data is produced and consumed. And with the rise of natural language interfaces and AI-powered validation, this is finally becoming possible. “Decentralization is possible today because of NLP,” Mona added. “We can make quality checks accessible through simple prompts, allowing agents and business users to participate without deep technical knowledge.”
Scott Haines described this as “governance that lives where work happens.” Instead of forcing teams to adopt new tools, observability and validation flow directly into existing workflows — Git commits, notebooks, orchestration platforms, or even chat-based agents. The result is ambient governance: always present, rarely intrusive, and fully traceable.
The broader implication is that trust itself becomes decentralized, but discipline stays centralized.Central teams define the rules, while distributed teams enforce and improve them through automated systems. NLP and agentic validation create a collaborative loop in which humans guide intent, and systems ensure consistency.
Closing Thoughts: Trust Is Your Data Moat
In the rush to operationalize Agentic AI, it’s easy to focus on compute power, model accuracy, or prompt engineering. But as every enterprise soon discovers, the true differentiator isn’t intelligence, it’s integrity.
Agentic AI doesn’t just consume data; it inherits its flaws. In an autonomous ecosystem, even a minor inconsistency can amplify into a systemic failure. That’s why building trust as infrastructure is no longer optional. From contextual validation to open lakehouses, from metadata-rich MCP layers to headless observability, every architectural decision now shapes how confidently your systems can operate independently.
As enterprises design for autonomy, this trust fabric becomes their most enduring moat. It’s what enables AI agents to reason responsibly, what gives teams confidence in automation, and what allows innovation to scale without fear of fragility.In the end, trust isn’t a checkpoint in the pipeline, it’s the currency of intelligent systems. The organizations that invest in reliable, contextual, and explainable data today will be the ones defining how AI behaves tomorrow.
Want to learn how Telmai can accelerate your AI initiatives with reliable and trusted data? Click here to connect with our team for a personalized demo.
Want to stay ahead on best practices and product insights? Click here to subscribe to our newsletter for expert guidance on building reliable, AI-ready data pipelines.