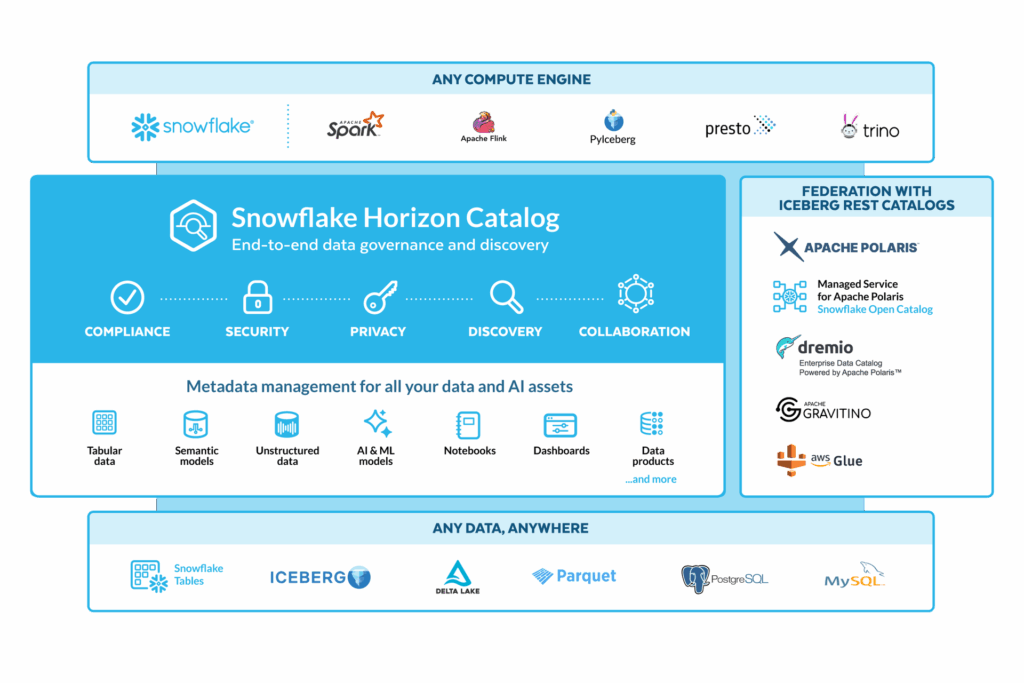
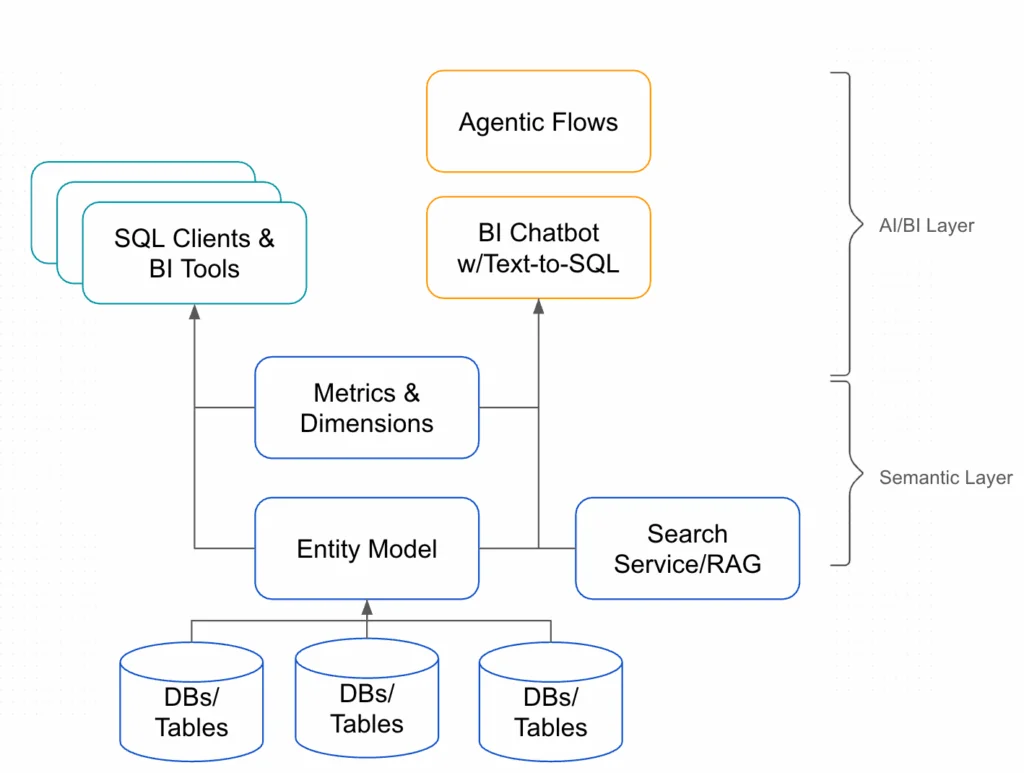
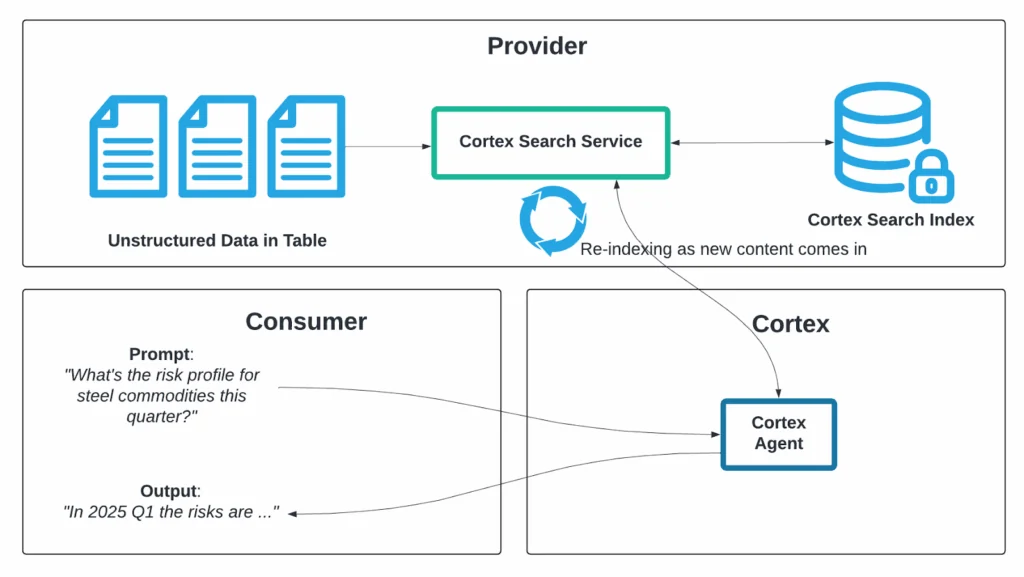
Reliable data is the foundation for every modern enterprise,from powering AI models to ensuring trusted reporting and customer experiences. But as architectures evolve toward distributed open lakehouse and multi-cloud hybrid data environments, ensuring data quality at the source becomes more critical than ever. That’s why, in the first half of 2025, Telmai continued to double down on enabling observability where the data lives—in the lake itself. From native Iceberg support that eliminates warehouse dependencies to enhanced rule logic and smarter alerting, our latest updates are built to help data teams monitor, validate, and remediate data issues earlier in the pipeline.
The result: greater trust in data-driven initiatives through automated resolution, allowing data reliability to scale alongside your growing ecosystem without adding operational overhead.
Ensuring data quality is made simple for Business and Engineering teams
Enhanced DQ Rule Engine to scale and unify validation across your stack
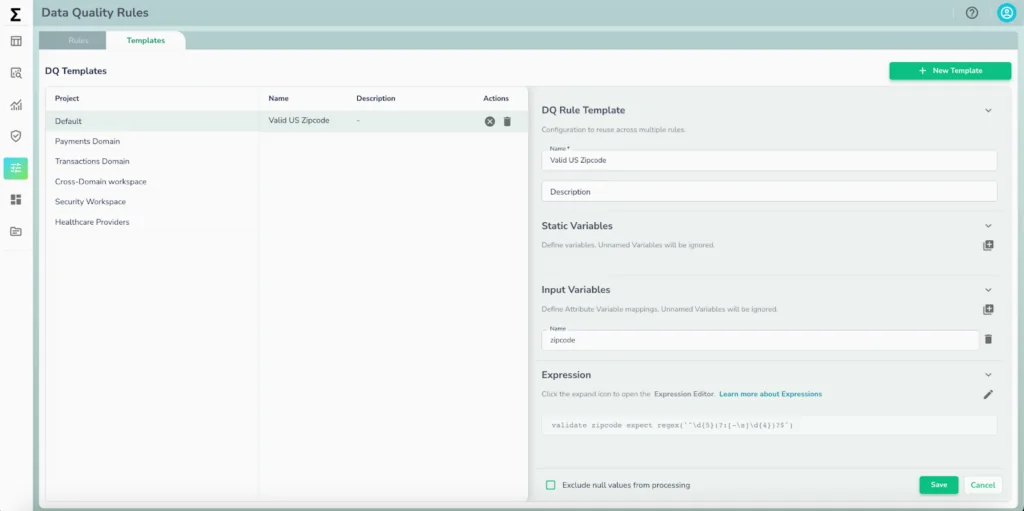
As data pipelines become increasingly distributed and complex, centrally managing the various data quality rules and validation workflows is no longer optional—it’s essential. Telmai’s enhanced rule engine offers a unified interface for creating, editing, and deploying validation rules across all systems, eliminating fragmented and siloed operations. With reusable templates, and JSON-based rule definitions, teams can standardize validations, ensure version control and further integrate into CI/CD workflows. Decoupled from warehouse compute, Telmai executes validations in its own engine, delivering performance and scalability without additional cost or operational overhead.
Custom free-form SQL metrics and advanced rule logic
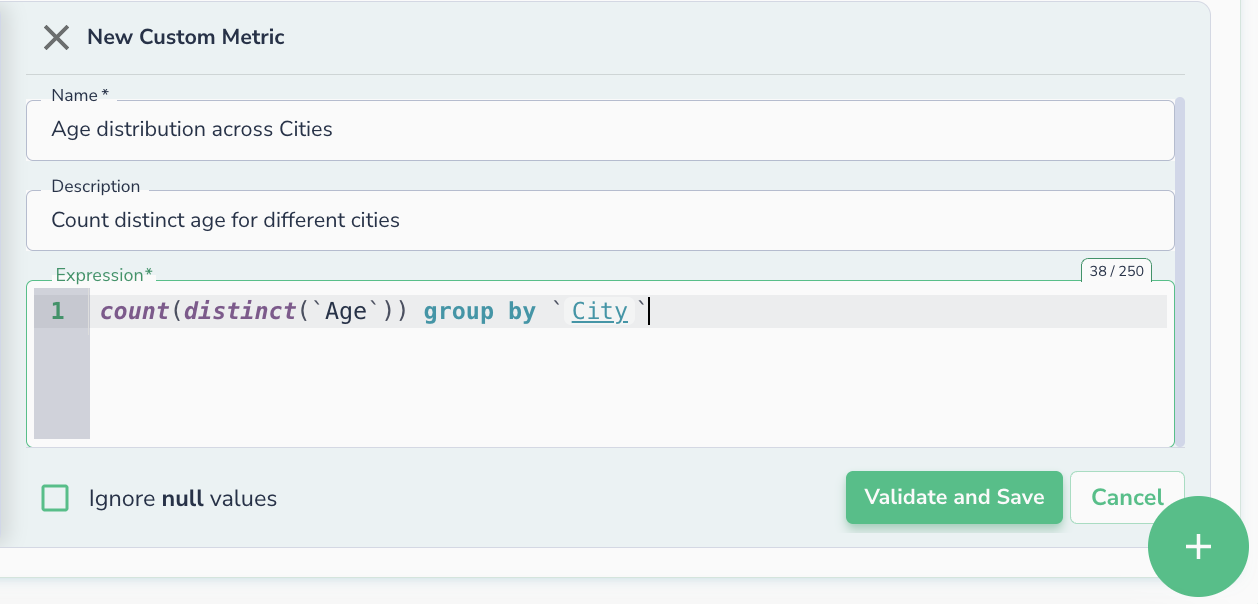
Telmai now enables users to define custom metrics using SQL and implement complex validation logic that reflects their unique data domain, all through an intuitive interface. Whether it’s tracking nuanced business KPIs or applying layered rule conditions, teams can build data quality rules that align with real-world expectations, without engineering overhead. This empowers users across technical levels to define what “data quality” means for their organization and catch edge-case anomalies that generic rules often miss.
Monitor data quality trends with custom metric dashboards
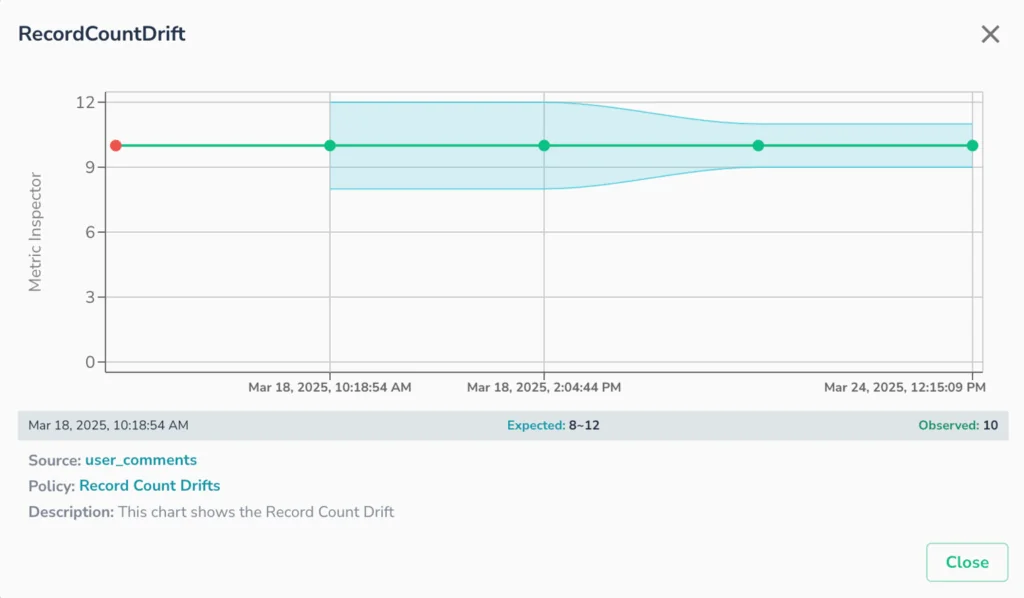
Telmai’s Metric Inspector equips teams with interactive dashboards to visualize and investigate data quality trends over time with interactive, time-series dashboards that reveal how key data quality metrics behave over time. Users can drill into data quality KPIs such as null rates, freshness lag, or custom-defined KPIs and correlate them with anomaly triggers. This level of transparency helps data teams identify patterns, validate rule thresholds, and continuously refine their data quality strategy.
Observability at the Source for Open Table Formats
As AI applications and advanced analytics become table stakes for modern enterprises, organizations are increasingly adopting open lakehouse architectures powered by table formats like Apache Iceberg, Delta Lake, and Hudi. While these formats offer the flexibility of object storage with the governance and performance of traditional warehouses, they lack native mechanisms for ensuring data quality and reliability.
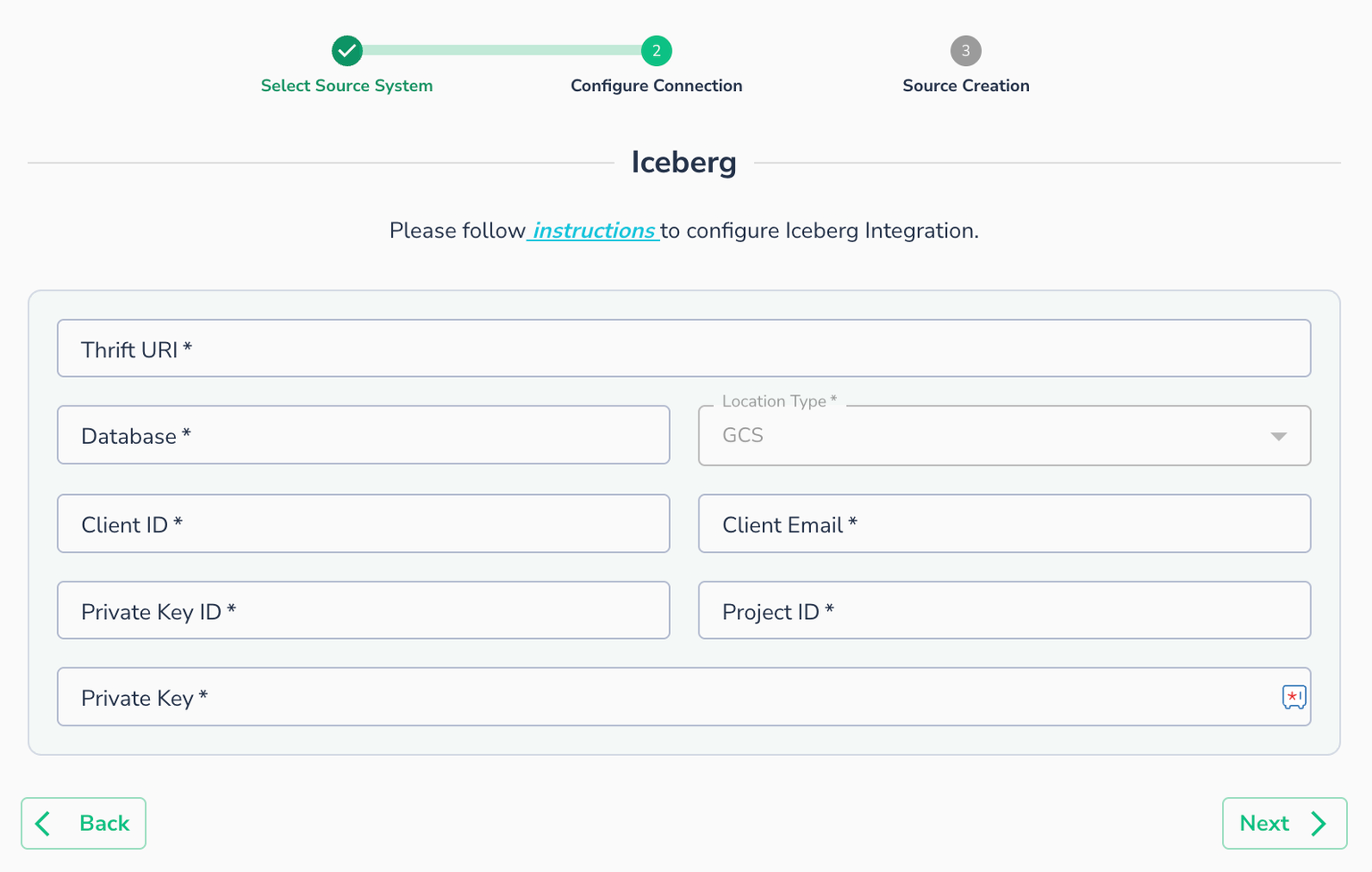
Without observability at the source, organizations are forced to validate data downstream, driving up cloud costs, delaying issue detection, and undermining the reliability of critical analytics and AI initiatives. Telmai solves this by delivering native, source-level observability for Apache Iceberg on GCP and GCS, with Delta and Hudi support on the roadmap.
Through partition-level profiling and metadata pushdown, Telmai enables full-fidelity validation without scanning entire datasets or triggering warehouse compute. This empowers teams to detect schema drift, freshness issues, and value anomalies early in the pipeline, ensuring AI models and analytical workloads operate on trusted, timely data, at scale and without architectural compromise.
Operational Efficiency Through Smarter Workflows and UX
Streamlined interface for defining and managing DQ policies
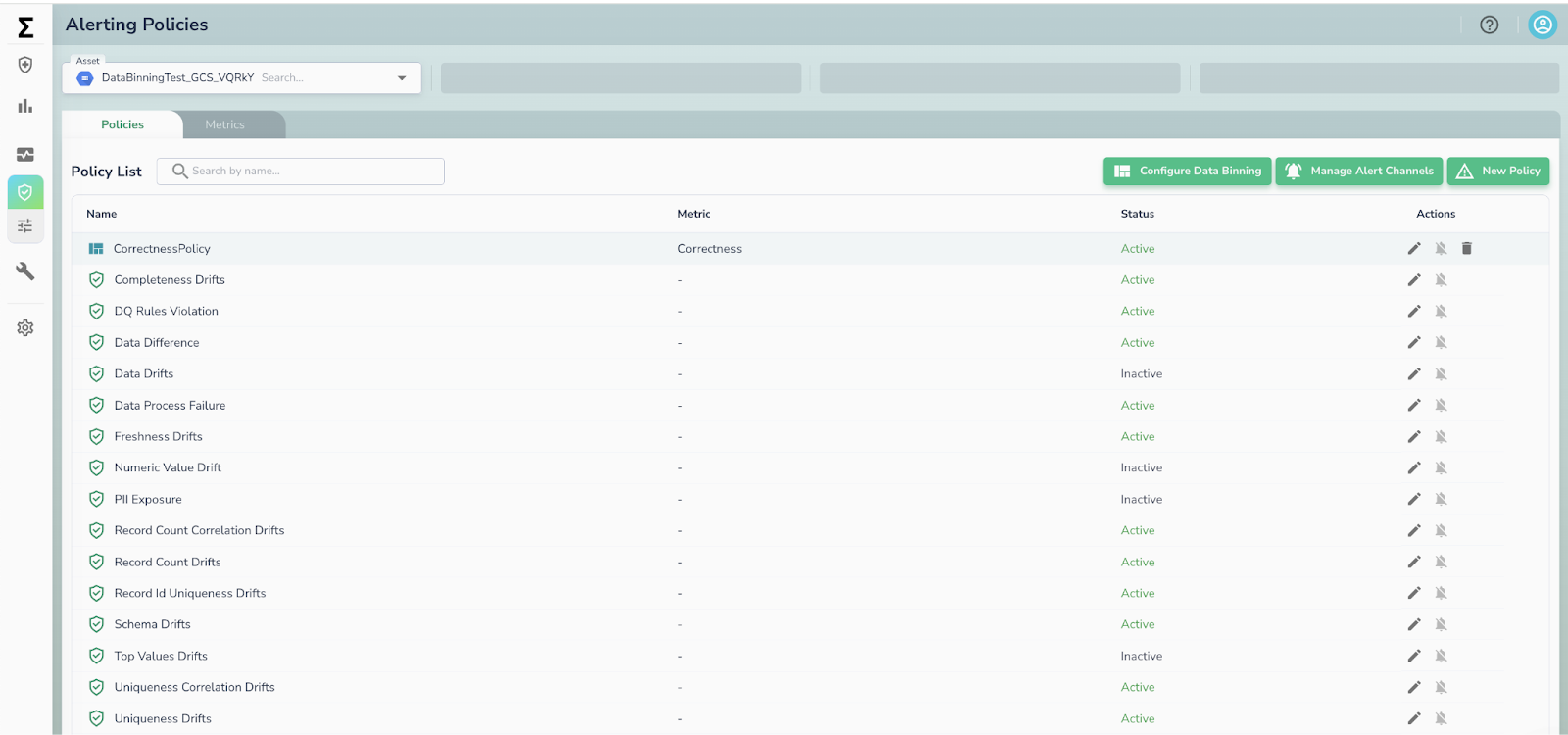
Telmai’s updated policy management UI makes it easier for users to define, configure, and review data quality policies at scale. The refreshed layout improves visibility into rule thresholds, affected datasets, and policy logic—reducing the time it takes to author or adjust checks. Designed to support both technical and operational users, this interface lowers the barrier to entry and enables more teams to take ownership of data quality without relying on engineering.
Smarter alerting and workflows for faster resolution
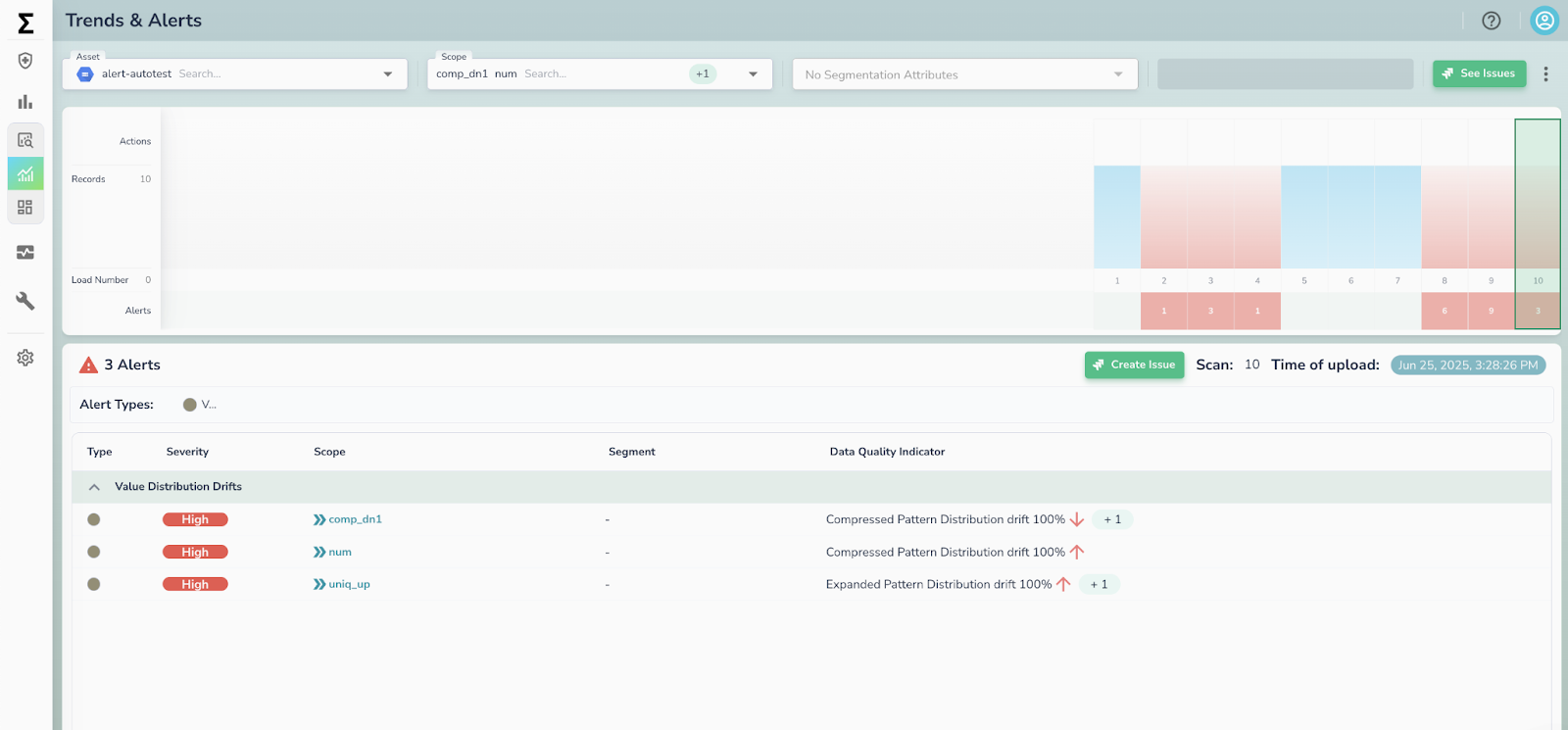
As data ecosystems scale, managing noise becomes just as important as detecting issues. Telmai now includes enhanced alert routing logic that ensures notifications are delivered based on policy type, team ownership, and relevance—so the right people are alerted at the right time. By aligning alerts with organizational context, teams can reduce alert fatigue, prioritize what matters, and accelerate resolution. This makes it easier to operationalize data quality across distributed teams and complex pipelines.
Simplified connection and asset management for faster onboarding
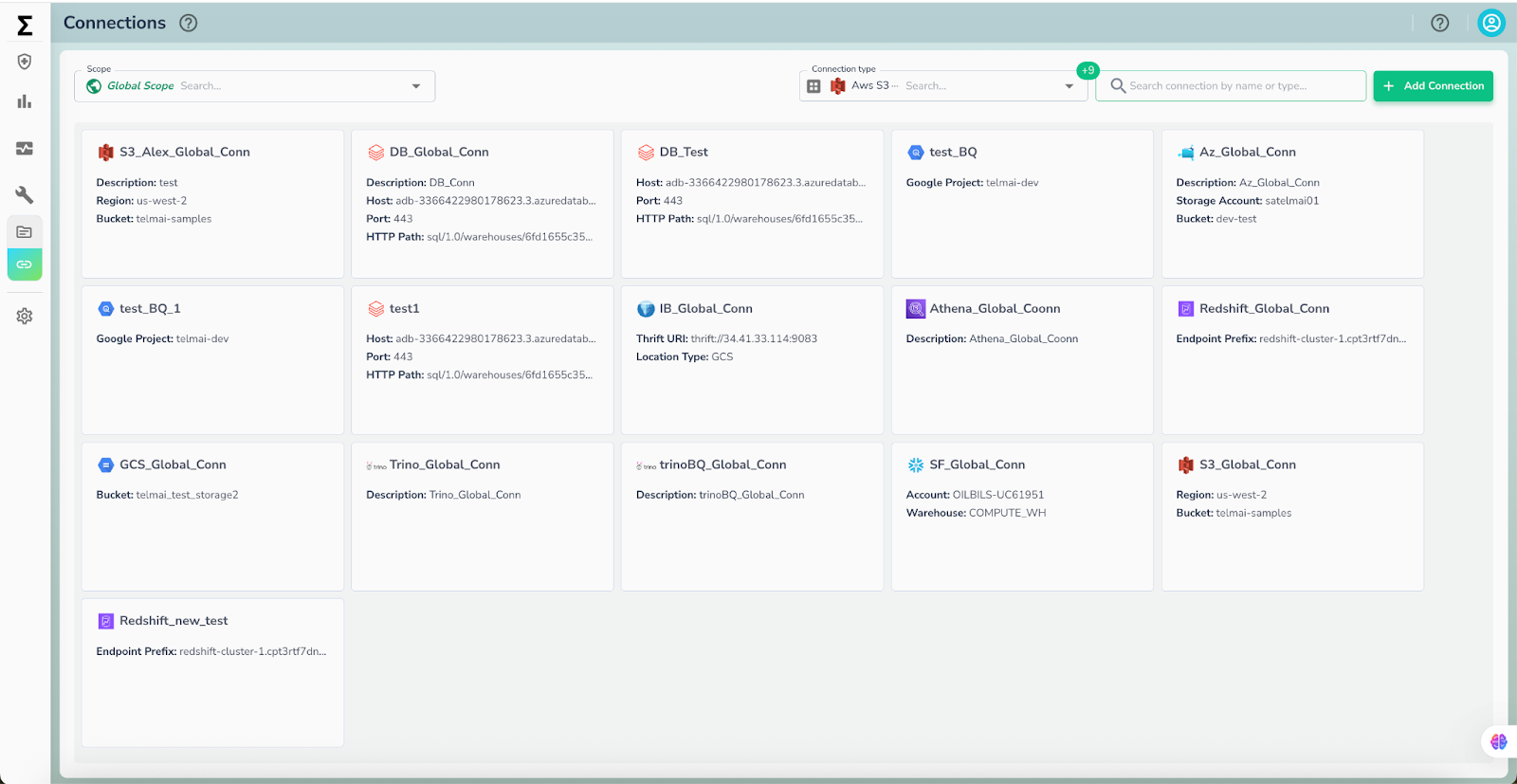
To streamline onboarding and reduce repetitive setup, Telmai has introduced a modular approach to managing connections and assets. Previously, connections were tied directly to asset creation, requiring full configuration for each new asset.
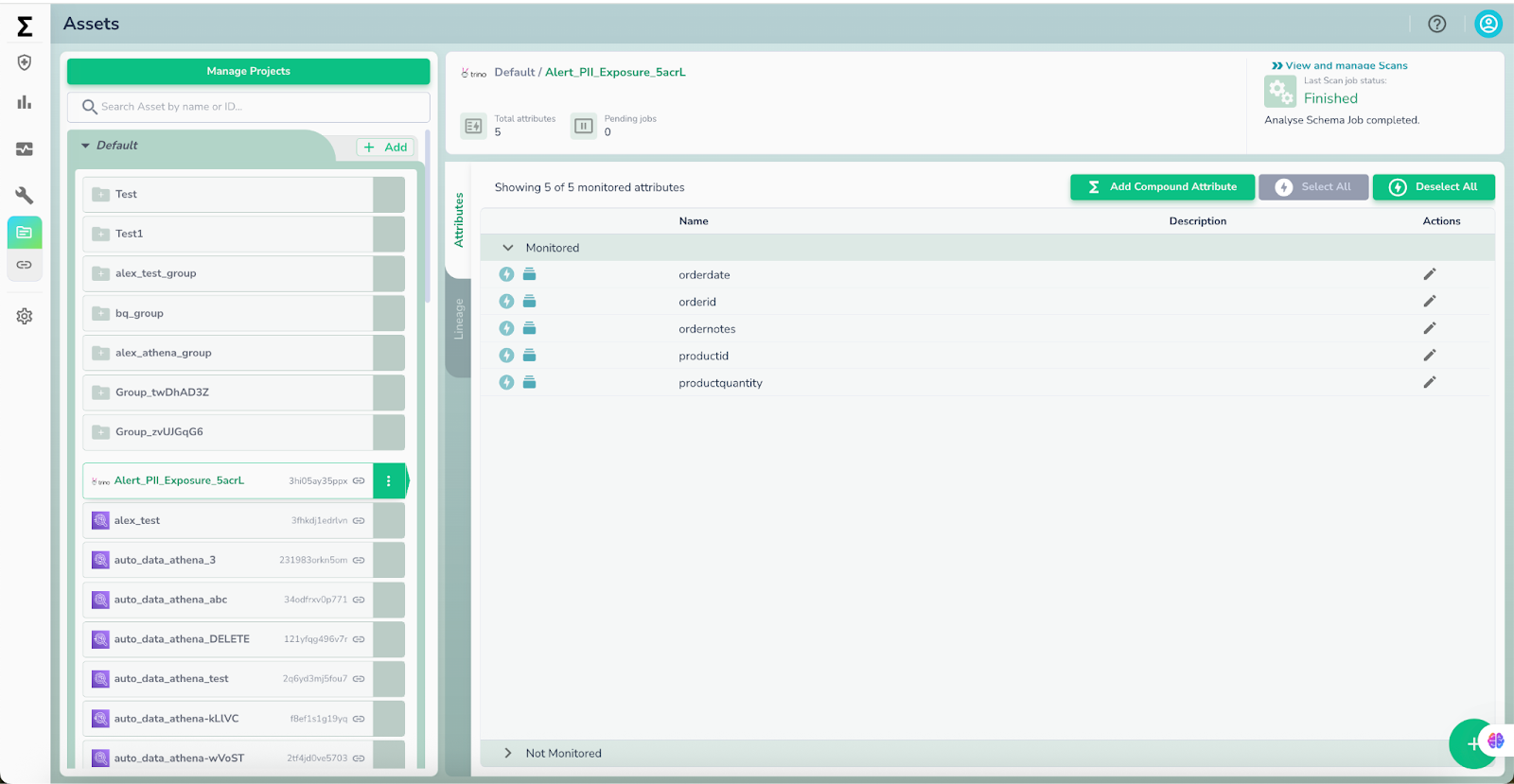
Now, source connections are created once through a centralized interface and can be reused across multiple assets. This separation simplifies setup, reduces duplication, and gives teams better control over how data sources are organized and maintained—leading to faster deployment and easier scaling across environments.
Closing Thoughts
As modern data ecosystems scale to support AI, open table formats, and real-time analytics, ensuring data quality at the source has become a strategic priority. Our latest updates reflect Telmai’s continued commitment to enabling proactive, high-fidelity AI augmented data quality monitoring, tailored to the needs of both business and data teams.We’re excited for you to explore these new capabilities and welcome your feedback as we continue to innovate.
Want to learn how Telmai can accelerate your AI initiatives with reliable and trusted data? Click here to connect with our team for a personalized demo.
Want to stay ahead on best practices and product insights? Click here to subscribe to our newsletter for expert guidance on building reliable, AI-ready data pipelines.