Leveraging ML to supercharge data quality validation processes
Machine learning (ML) methodologies can be effectively utilized to amplify the processes of data quality validation. By automating error detection and correction, recognizing patterns and anomalies, and enhancing the precision and efficiency of the validation process, ML can significantly improve data quality validation.


Machine learning (ML) techniques can indeed be leveraged to supercharge data quality validation processes. ML can enhance data quality validation by automating the detection and correction of errors, identifying patterns and anomalies, and improving the accuracy and efficiency of the validation process.
Here are some ways to utilize ML for data quality validation:
- Data Profiling And Feature Engineering
- Anomaly Detection
- Data Cleansing
- Data Interpolation
- Deduplication
- Data Validations
- Error Prediction
- Continuous Learning And Improvement
Data profiling and feature engineering
ML techniques can be applied to profile the data and extract relevant features. By analyzing the data distributions, correlations, or statistical properties, ML algorithms can identify data quality patterns and indicators. ML models can build predictions for data quality metrics, such as data completeness, uniqueness, or distribution, and highlight potential quality issues or anomalies for further investigation.
These features can then be used to build robust data quality validation models.
Anomaly detection
ML algorithms can be trained to identify anomalies like outliers and drifts in the data via historical analysis and reviewing existing data-set.
By learning from patterns in the data, models can detect data points that deviate significantly from the expected behavior. Anomaly detection techniques can help uncover data quality issues such as out-of-range values, unexpected patterns, or duplicates etc.
There are two different approaches to this :
Anomalies based on historic learnings using Time-Series Analysis:
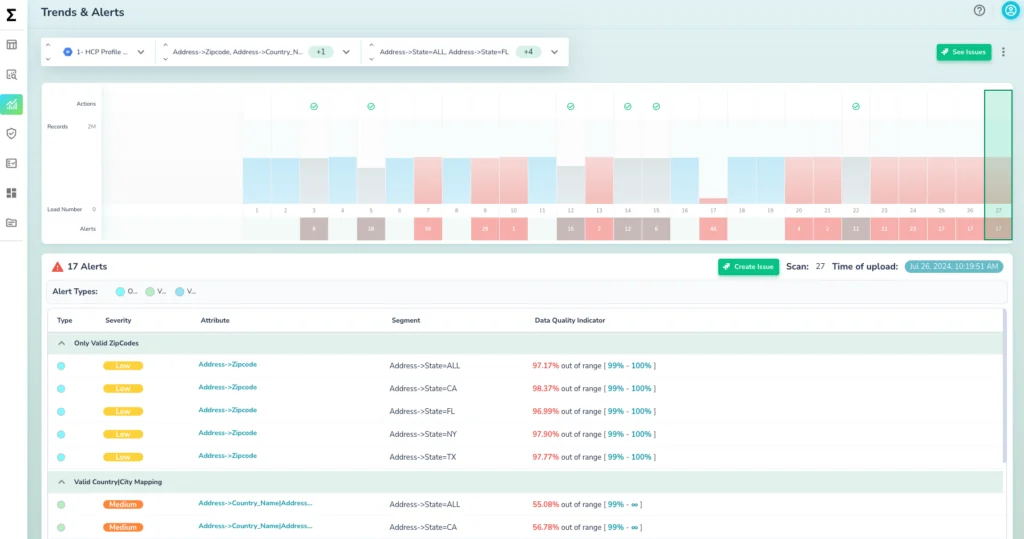
For time-series data, specific techniques can be employed to detect anomalies:
a. Statistical Methods: Statistical approaches such as Moving Averages and Linear Regression can be used to identify instances that deviate significantly from the expected statistical distribution of the data.
The concept behind moving averages is to smooth the time-series data to better see patterns, seasonal effects, and trends. This is particularly useful in detecting outliers or unusual spikes or drops in the data by calculating the average of the data points in a given time window that ‘moves’ along with the time-series data, thus the term ‘moving average’.Any data point that significantly deviates from the moving average could be considered an anomaly.
Linear regression fits a line to the time-series data. It tries to explain the data by establishing a linear relationship between the time and the value of the data. When a new data point deviates significantly from this linear relationship, it could be considered an anomaly.
b. Seasonal Decomposition: Time-series data often exhibit seasonal or periodic patterns. Decomposing the time series into its seasonal, trend, and residual components can help identify anomalies in the residual component.
c. Recurrent Neural Networks (RNNs): RNNs, particularly Long Short-Term Memory (LSTM) networks, can capture temporal dependencies and patterns in time-series data. They can be trained to predict the next data point, and instances with high prediction errors can be considered as anomalies.
Anomalies within a Data snapshot :
Anomalies within a dataset refer to data points or instances that deviate significantly from the expected patterns or behaviors observed in the majority of the data.
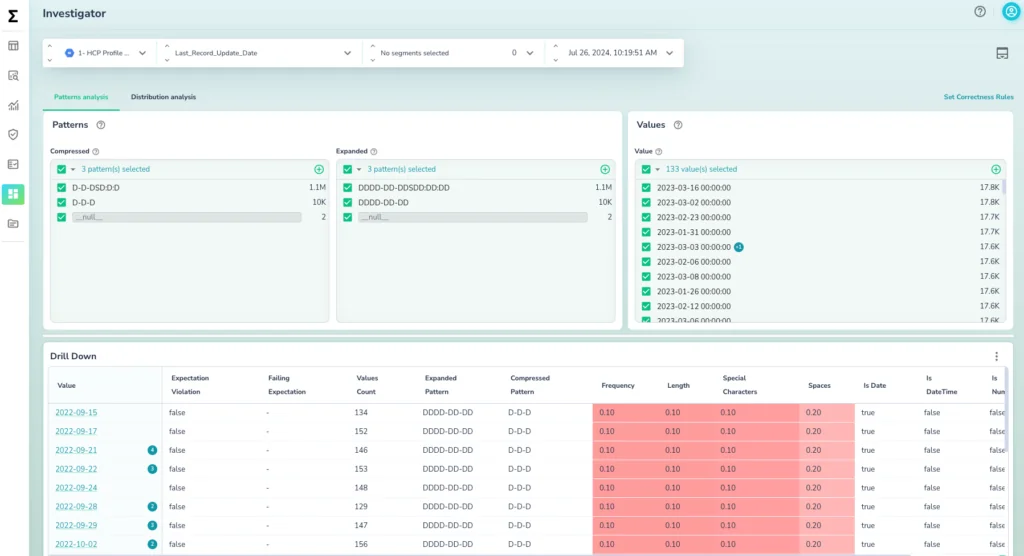
These anomalies can be caused by various factors such as errors in data collection, measurement errors, system malfunctions, fraudulent activities, or rare events.Issues like out-of-range values are hard to catch using validation checks and either need human-in-loop or ML based techniques.
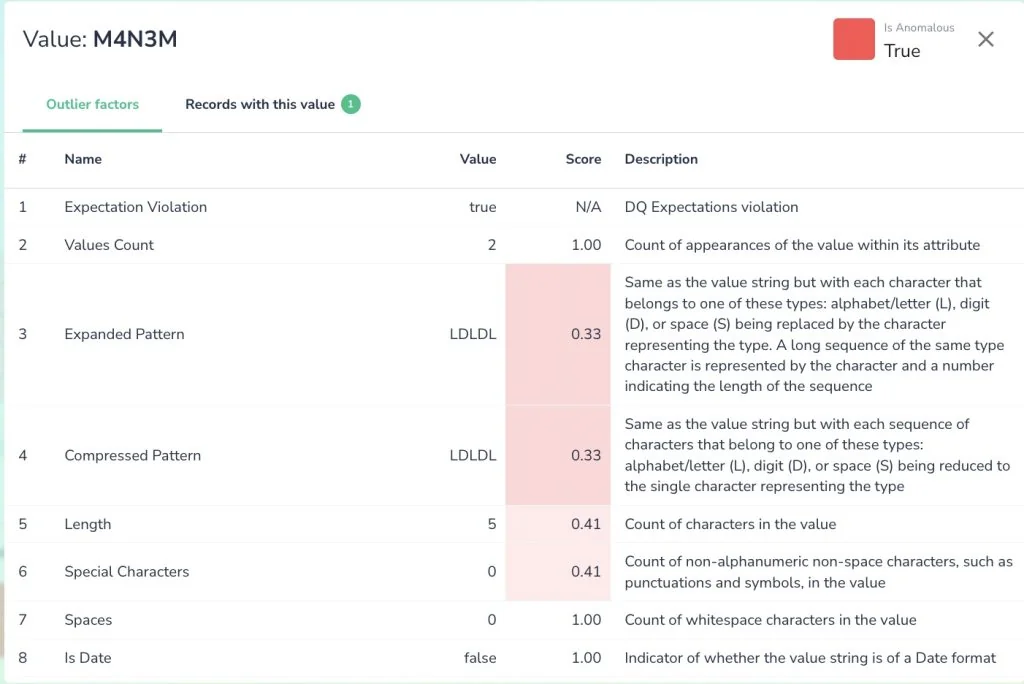
Example techniques : isolation forest, k-nearest neighbors, or one-class SVM, can help identify and remove or correct outliers.
At Telmai, we experimented with multiple models and concluded that anomaly detection based on historic data is much more powerful for Data quality use cases.
Data cleansing
ML algorithms can efficiently identify and extract different PII elements such as names, addresses, social security numbers, email addresses, phone numbers, and more from unstructured text, such as medical records, customer feedback, or online reviews.ML can recognize and mask sensitive information while also ensuring uniformity by standardizing formats. By leveraging ML for PII data cleaning, organizations can comply with data protection regulations, maintain data integrity, and confidently use the data for analysis, research, and business insights while respecting individual privacy.
Data interpolation
ML techniques can also be applied to interpolate missing or incorrect data values. By learning patterns from existing data, ML models can predict and fill in missing values, reducing data incompleteness and improving overall data quality.
For example: Employing a suite of ML methods like Prophet can be particularly effective for estimating missing data points in time-series datasets, such as forecasting future sales in retail or predicting web traffic for resource allocation. By learning from historical patterns and trend behavior, Prophet can effectively fill gaps and provide more accurate and reliable predictions
Deduplication
Record deduplication is a process of identifying duplicated entities in the dataset. Such records may not always be identical; for example, names can be spelled differently, and addresses can be different because they were entered at different points in time, but when considering all evidence (attributes) together, a person or system can come up with the decision of high certainty on if two records describe the same entity (ex. person) or not.
The classic approach to this problem was to write many matching rules (ex., If name and address are the same, then merge it’s the same person); sometimes rules could become very complex. But still, it would only be possible to validate if all duplicates are taken care of and taken care of correctly.
ML can be a great help in such a task. However, whatever approach is taken, it needs to be considered that there will be limited training data. One of the approaches, in this case, is Active Learning, where human inputs are used to actively retrain models after each answer, which could dramatically reduce the need for a large training corpus. Active learning is no silver bullet, though, and in many applications, it proved not to provide good results because you can not make up information from nothing. But for the task of record deduplication precisely, it proved very efficient.
Data validations
Data validation checks are used to verify the integrity and quality of data. Traditionally these data validation checks can be implemented using programming languages, SQL queries, data validation tools, or through dedicated data quality management platforms.
This approach requires constant monitoring and manual adjustments to the threshold as data trends change over time.
An ML-Based Automatic Threshold Approach addresses this gap, with an ML-based automatic threshold approach, you can leverage historical data to train a model that learns the patterns and automatically determines the acceptable threshold. The ML model can analyze historical data, identify patterns, and calculate the threshold dynamically based on statistical measures, such as standard deviation or percentile ranges. The model can then automatically flag any deviation beyond the determined threshold as potential data quality issues.
Benefits of ML-based automatic threshold
- Adaptability: The ML model can adapt to changing pricing patterns and adjust the threshold automatically, reducing the need for manual threshold adjustments.
- Flexibility: The ML model can consider various factors, such as seasonality, promotions, or market trends, to determine the appropriate threshold dynamically.
- Efficiency: ML-based approaches can process large volumes of data quickly, allowing for real-time or near real-time analysis and identification of data quality issues.
- Accuracy: ML models can capture complex patterns and relationships in the data, enabling more accurate identification of outliers or unusual data points.
While ML models offer powerful tools for data analysis, their effectiveness hinges on customization. This isn’t a one-size-fits-all game. The ML model for automatic threshold determination requires historical training data and regular monitoring. It’s the collaborative efforts of data scientists, domain experts, and data stewards that truly fine-tune the system, interpreting ML results, validating thresholds, and managing exceptional cases or domain-specific considerations. Remember, there’s always a critical need for a platform that allows these key players to efficiently tailor models for each unique situation. In the realm of data, flexible moldability and adaptive potential is key.
Error prediction
Machine Learning (ML) models are akin to our memory, they learn from historical events, in this case, data errors and quality issues. By meticulously training on past data quality problems and the intricate patterns surrounding their characteristics, ML can go beyond merely reacting to data errors. It becomes a valuable, proactive shield that predicts potential issues before they take root.
Consider a manufacturing data pipeline where sensor data is constantly fed into the system. If inconsistencies or outliers have occurred in the past under specific conditions, ML models can recognise these conditions and alert stakeholders of a potential error, almost like a data guardian angel foreseeing trouble. This can save significant resources that would otherwise be spent rectifying the error down the line.
Continuous learning and improvement
Continuous monitoring and drift detection: ML models can continuously monitor data quality metrics and detect drifts or changes in the data distribution over time. They can learn from historical data to identify when data quality starts deviating from expected patterns and trigger alerts or corrective actions.
Feedback-driven improvement: ML models can incorporate feedback from data stewards or domain experts to improve their performance. Feedback can be used to refine models, update rules, and adapt to evolving data quality requirements.
Summary
Applying ML techniques for data quality validation requires quality training data, appropriate feature engineering, and careful model selection and evaluation. It’s important to note that while ML can significantly enhance data quality management, it should be used in conjunction with human expertise and validation. Human involvement is crucial for interpreting results, understanding context-specific nuances, and making informed decisions regarding data quality. Collaboration between data scientists, data stewards, and domain experts is key to successfully applying ML techniques for supercharging data quality.
But by incorporating ML into data quality validation processes, organizations can streamline and automate validation tasks, accelerate error detection and correction, and improve overall data accuracy and reliability at a fraction of the cost.
Passionate about data quality? Get expert insights and guides delivered straight to your inbox – click here to subscribe to our newsletter now.
- On this page
See what’s possible with Telmai
Request a demo to see the full power of Telmai’s data observability tool for yourself.


