How to avoid the hidden costs of bad data in your data lakehouse
Explore the importance of maintaining high-quality data within data lakehouse systems to avoid increased cloud spending and operational disruptions. Learn about effective strategies to prevent the infiltration of bad data, ensuring your enterprise’s data remains a powerful asset for competitive advantage.

One key area for organizations is controlling exploding data infrastructure costs. With the power and scale of a modern lakehouse, this is even more important, as the ease of access to large volumes of data may lead to significant inefficiencies and non-optimal use. Data quality might have a very significant impact on the budget, as it has two aspects: operational and infrastructure.
Operational assumes additional stress and load on data teams, who must investigate, reprocess, and recalculate reports when data quality issues get through lines of defense to the final product.
Infrastructure includes additional and unnecessary spending on moving, storing, and querying wrong or inaccurate data.
Cloud infrastructure cost of bad data
Ingesting bad data in a data lakehouse system causes a ripple effect on cloud infrastructure cost, increasing the cost of storing, moving, and querying data. Additionally, it could overload the downstream systems, for example, by causing a cross-product calculation while joining and enriching data. Bad-quality data can slow down or even crash the entire pipeline.
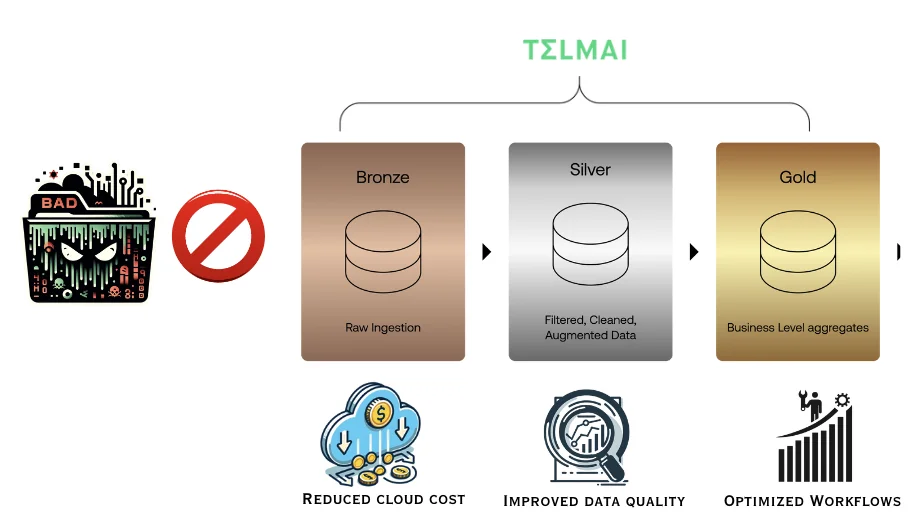
Let’s do a simple math :
If the daily ingested data across systems is 100GB, assuming 5% of this data is inaccurate (duplicate, incomplete, invalid, etc.)
If this data is not stopped at the source, you will end up transferring this data 3 times, i.e., bronze to silver to the gold layer.
Additionally, you will store the invalid 10% data in three different layers, and last but most importantly, you will constantly(ongoing) query this invalid data.
How to handle poor data quality in data lakehouses
A key strategy for handling poor Data Quality in Data Lakes is implementing a proactive safeguard against the influx of bad data at each layer from pre-ingestion, ensuring that your data lakehouse maintains a standard of excellence from the outset. This is where data quality monitoring measures like data quality binning come into play.

Data quality binning is a proactive approach to ensuring data quality from the start. This technique systematically segregates suspicious data, preventing it from entering your data pipeline. By setting up predefined rules based on data accuracy, relevance, and completeness, this method allows only verified, good data flow to your data lakehouse.
The adoption of Data Quality Binning offers significant cost savings and efficiency improvements.

Adopting data quality binning in the early stages of medallion architecture will not only minimize the influx of low-quality data and reduce the cloud cost of bad data but also allow existing data issues to be effectively isolated and addressed. This dual approach—prevention and targeted remediation—means enterprises can avoid the expenses associated with rectifying errors downstream, which are not only costly but also time-consuming.
Additionally, you will now store your inaccurate data in the data lake or cold storage, significantly reducing the overall cloud cost.
Consequently, when such proactive data quality measures are implemented, your data team can focus on their core essential tasks and will not be sidetracked by data quality firefights.
Conclusion
The challenge of managing bad data in modern data stacks like data lakehouse systems is real and costly. By strategically implementing data quality monitoring across different stages of a lakehouse, enterprises can safeguard themselves against these costs, ensuring their data remains a valuable asset rather than a liability. By focusing on a multifaceted approach to data quality, organizations can enhance decision-making processes and secure a competitive advantage, demonstrating that the value lies in the overall framework rather than an individual solution.
Passionate about data quality? Get expert insights and guides delivered straight to your inbox – click here to subscribe to our newsletter now.
- On this page
See what’s possible with Telmai
Request a demo to see the full power of Telmai’s data observability tool for yourself.



