The Critical Role of Unstructured Data Quality in the Age of Agentic AI
Agentic AI systems are only as effective as the data they act on and most of that data is unstructured, messy, and overlooked. As AI shifts from passive analysis to autonomous decision-making, enterprises must treat unstructured data as a strategic asset. This article explores why unstructured data quality is so difficult to manage, how it directly impacts AI performance, and what organizations must do to make it usable, trustworthy, and fit for purpose.

Agentic AI workflows are changing how enterprises operate, enabling systems to reason, decide, and act autonomously based on business intent. However, for this intelligence to be useful, it must be informed by context-rich knowledge.

Nearly 90% of enterprise knowledge is stored in unstructured formats, including emails, contracts, reports, logs, and audio transcripts. Despite its value, this data is often poorly labeled, inconsistently maintained, or entirely ignored.
As AI agents take on more responsibility, leveraging this untapped data holds the key to ensuring that AI-generated insights are aligned to current business goals and priorities. Yet unlike structured data, unstructured data lacks standard processes, making organizing, validating, or governing at scale challenging.
In this article, we explore the role unstructured data plays in powering agentic workflows and why managing it well is one of the most urgent data challenges facing modern enterprises.
What Makes Unstructured Data Quality so tough?
Unstructured data holds massive potential, but enterprise data teams face three major, deeply interlinked hurdles that make managing and leveraging it exceptionally hard:
- Scale and Complexity – Enterprises generate an overwhelming volume of unstructured data—from emails and contracts to logs and audio. This data arrives at increasing velocity and from countless channels, each in its own format: text, PDF, multimedia, and beyond. What makes this tough isn’t just volume; it’s the disconnect between ensuring that business needs align with the available data. Manual quality checks quickly become unmanageable at this scale, increasing the risk for mission-critical opportunities to slip through the cracks.
- Turning Raw Data Into Actionable Insight – Unlike structured database rows, unstructured content must go through layers of transformation before it can be machine readable. This preprocessing is not only labor-intensive and resource-heavy but often highly iterative. What works for one format may degrade another, making data prep unpredictable and directly slow down innovation.
- Integration and Format Inconsistency – Most enterprises operate with legacy systems and isolated data repositories, which makes integrating newer sources and systems tough. Further, Unstructured data exists in numerous and inconsistent formats, making extraction and integration difficult. The lack of standardization not only slows the flow of insight but also introduces ambiguity and hidden gaps that slow down critical processes and undermine business trust.
How Poor Unstructured Data Quality Derails Agentic AI
For agentic AI to perform reliably, unstructured data must not only be available, but aligned, contextualized, and trustworthy in the moment it’s used.
Unlike traditional AI models trained on stable, historical datasets, agentic AI systems must continuously interact with dynamic, real-time enterprise data. That means data must be accurate, current, and contextually complete. If data is outdated, missing, or imprecise, these systems risk making decisions that quickly become misaligned with business reality—creating errors that can compound over time and erode organizational trust.
Another critical challenge is the loss of context. As unstructured data moves through multiple processing and preprocessing pipelines, essential relationships and business nuances can be lost or distorted. Agentic AI systems rely on consistent understanding across disparate sources—from logs and emails to reports and contracts.But differences in terminology, structure, or classification can muddle this process, leading to inconsistent and unreliable outputs.
Finally, agents operating within enterprise environments don’t benefit from the trust signals that guide public search engines. There’s no domain authority or PageRank to rely on. If the underlying data lacks structure or metadata, the agent can’t determine what to trust—and the burden of judgment shifts entirely to the data team.
How Telmai Makes Unstructured Data AI-Ready
Telmai elevates unstructured data, alongside structured data, as a first-class citizen in your data pipeline by enabling observability across various formats, including PDFs and document scans. With its unique ability to process semi-structured content, Telmai leverages AI models to process unstructured data and convert it into semi-structured data for further analysis.
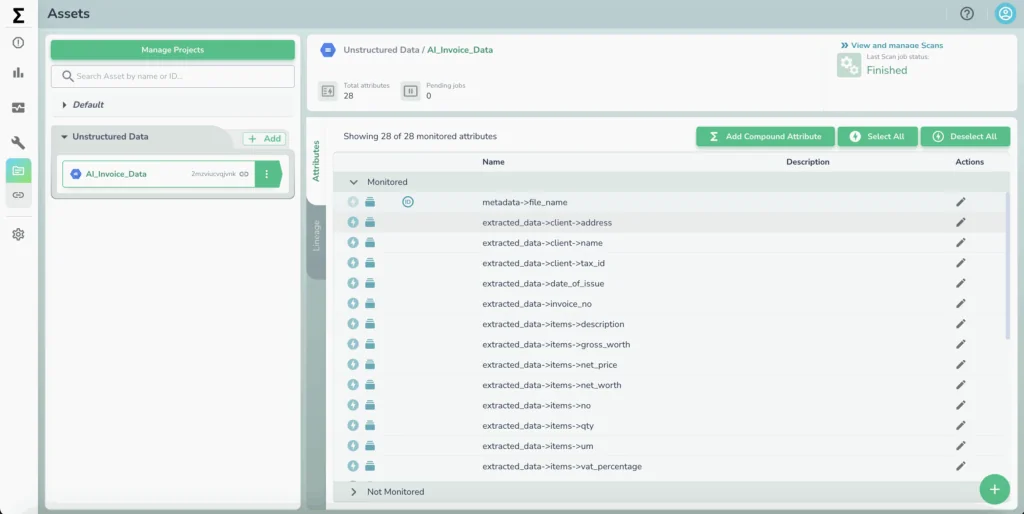
Each unstructured file, whether it’s an invoice, contract, or log, is automatically parsed into a nested, structured JSON file, transforming even the most complex unstructured documents into machine-readable and human-verifiable assets. Alongside this, Telmai captures rich file-level metadata such as timestamps, file size, and source system lineage, adding contextual depth for downstream AI or analytics.
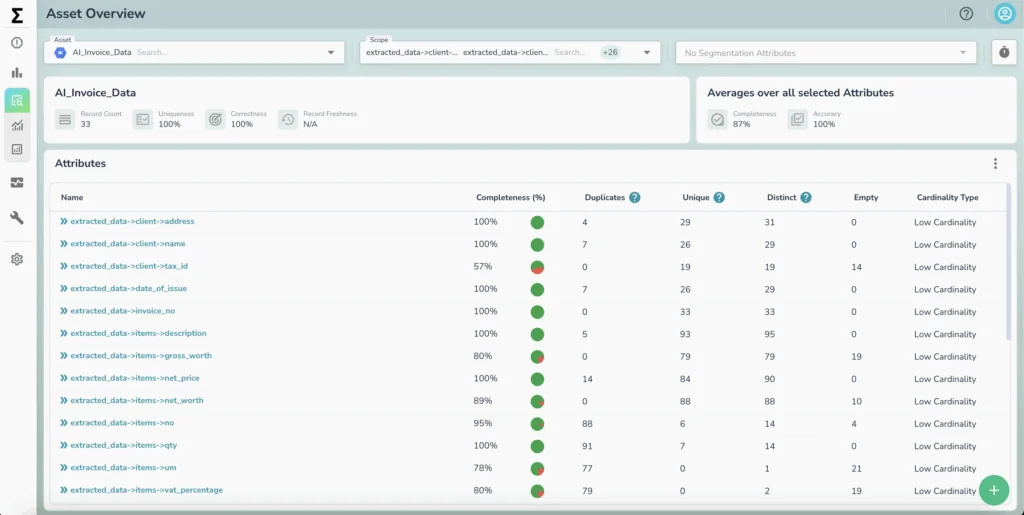
Every unstructured file is treated as an individual record. Once parsed, Telmai can leverage its AI-driven observability engine to perform profiling, anomaly detection, and validation capabilities at a granular attribute level, just as it does for structured datasets.

Data teams can not only surface hidden quality issues but also implement custom validation rules against any field within the structured JSON output, enforcing highly specific fit-for-purpose policies that reflect real-world business and regulatory requirements.
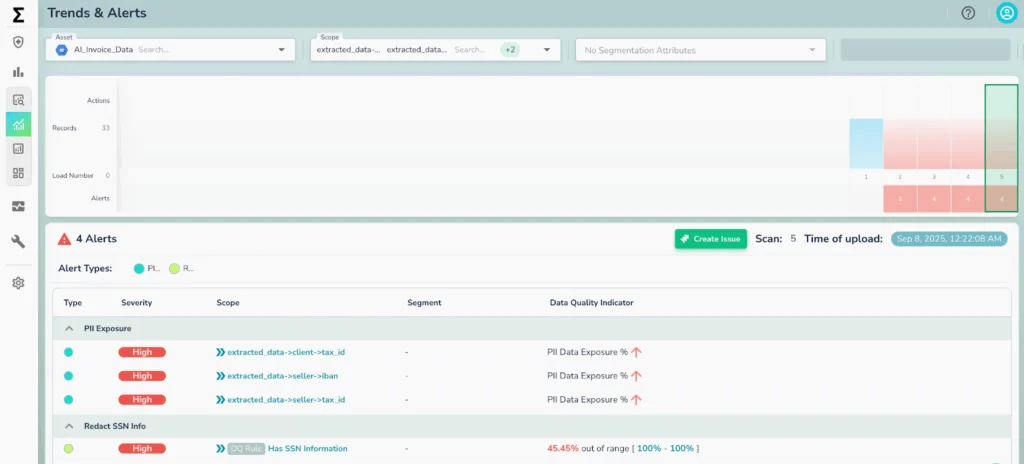
This approach enables organizations to surface hidden data issues early, enforce quality at scale, and prevent unreliable or unvalidated information from contaminating downstream AI systems and business decisions.
Conclusion
As enterprises move from rule-based automation to agentic AI, the foundation they build on—data—becomes more critical than ever. Enterprises must stop treating unstructured data as background noise and start elevating it to a first-class citizen in data governance and observability. Teams must align, enrich, and continuously monitor unstructured data to keep it fit for purpose.
Data teams must evolve beyond reactive fixes and embed validation early in data pipelines, establish clear standards for unstructured data, and implement end-to-end governance practices that keep AI decisions aligned with shifting priorities. Only with this disciplined foundation can agentic AI systems confidently operate and generate meaningful, autonomous outcomes.
Data quality will shape the future of autonomous AI just as much as model sophistication will. And for that future to work, unstructured data must be understandable, trustworthy, and ready to drive action.
Learn how Telmai can accelerate your AI initiatives with reliable and trusted data. Click here to connect with our team for a personalized demo.
Want to stay ahead on best practices and product insights? Click here to subscribe to our newsletter for expert guidance on building reliable, AI-ready data pipelines.
- On this page
See what’s possible with Telmai
Request a demo to see the full power of Telmai’s data observability tool for yourself.



