4 Ways to do data validation
You can code scripts, use Excel, use an ETL tool, or, even better, leverage a data observability tool like Telmai. Understand the pros and cons of each method and how Telmai can automate and streamline the process.


Imagine you’re at a gas station filling up your car and you notice that the numbers on the pump aren’t matching with what you’re paying at the payment terminal. This is an example of poor data validation – the data being collected (the amount of gas being dispensed) isn’t matching with the data being recorded (the cost of the gas).
Beyond the gas pump, data validation is a critical step in machine learning, system migrations, and really any data product. Since information is constantly being updated, deleted, or moved around, having valid data is a must.
While there are many different ways to approach data validation, the four most common are writing your own scripts, using Excel’s built-in data validation tool, using an ETL tool, or leveraging a data observability tool.
In this blog post we’ll dive into the pros and cons of each method and how the data observability platform Telmai can help automate and streamline the data validation process.
1. Coding data validation
Depending on your ability to code, validating data by writing a script may be an option for you. You can write Spark jobs, Python scripts, DBT assertions, or Great Expectations to compare data values and metadata against your defined rules and schemas to verify that all the necessary information meets your required data quality parameters.
The most popular of these kinds of data validation is using SQL. SQL can easily validate data records in a database based on a specific condition. Let’s say you want to exclude the customers whose email address includes “gmail” to exclude them from your marketing campaigns. You need to use the following SQL statement: Select * from Customer where Email like ‘%gmail%’ and subsequently, write the results into a table that you can use to upload to your marketing platforms.
Although this type of data validation is pretty popular among database administrators and programmers, depending on the complexity of your data and the size of the data set you are validating, this method of data validation can be quite time-consuming. It also can send unnecessary queries into your database, and as a result, slow it down.
2. Using excel
Among the most basic ways of data validation is using Microsoft Excel or Google Sheets. Of course, this method of data validation requires you to export your data into Excel or Sheets before you can start, which granted is neither scalable nor easily maintainable. In both Excel and Sheets, the data validation process is straightforward. Excel and Sheets both have a menu item listed as Data > Data Validation. By selecting the Data Validation menu, a user can choose the specific data type or constraint validation required for a given file or data range.
However, this type of data validation is limited to the type of data or the values. For example, whether data is in a drop-down list, or has a particular type such as date, time, decimal, and text values. And let’s not forget, you can only fit a limited number of records to either of these tools before your data validation process becomes unwieldy.
3. Using ETL, ELT, or data integration tools
ETL (Extract, Transform and Load), ELT (Extract, Load, Transform), and data integration tools typically integrate data validation policies as part of their workflow. These validation rules are executed as data is extracted from one source and loaded into another, or, in the case of ELT, after extract and load are completed and transformation happens in the database. Popular tools include dbt or FiveTran.
While these tools are popular for integrating data from multiple sources together, often for integrating into a data warehouse, they can’t handle incoming real-time data streams, they have higher data infrastructure costs and more engineering time effort to build and maintain data validation rules that are subject to change as data architectures, systems, schemas, and processes change.
4. Leveraging data observability tools
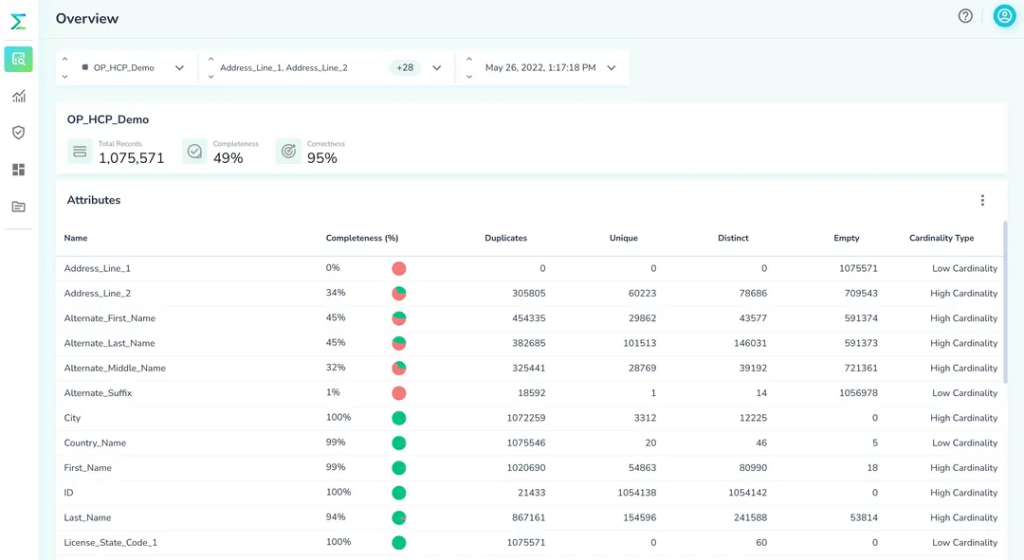
Data observability tools like Telmai enable you to customize data validation workflows precisely for your needs. You can automatically run any data validation workflow on a schedule (or on-demand) and get alerted if your data falls outside historical ranges or your predefined conditions. Plus Telmai’s ML-based learning enables you to detect data quality issues you couldn’t have even predicted would be a problem!
Passionate about data quality? Get expert insights and guides delivered straight to your inbox – click here to subscribe to our newsletter now.
- On this page
See what’s possible with Telmai
Request a demo to see the full power of Telmai’s data observability tool for yourself.
Articles
See all articles


