How important is data lineage in the context of data observability?
Explore the importance of Data Lineage in the context of Data Observability with Telmai. Understand how Data Lineage, which tracks changes and transformations in data records, contributes to data quality and reliability. Discover how Data Observability, aiming to reduce issue detection and resolution time, leverages Data Lineage for effective outcomes.


This is a very long due post, predominantly because there is a lot of confusion around data lineage , data observability and the inter-dependancies.
As many of us know data Lineage is one of the most discussed topic today (only after data observability ! ), this article covers the applicability of data lineage in Data Observability.
PS: If you are specifically looking to understand lineage better, these are few of my favorites on this topic.
Building Data Lineage: netflix & Leveraging Apache spark for Data Lineage : Yelp
What is data lineage?
Data lineage tracks the changes and transformations impacting any data record. Data lineage tells us where data is coming from, where it is going, and what happens as it flows from data sources and pipeline workflows to downstream data marts and dashboards.
In short, it enables better data governance by giving you a more complete, top-down picture of your data and analytics ecosystem.
Why is it so important for data quality?
Data lineage is essential for understanding the health of the data because it ensures transparency around the source of data, ownership, access, and its transformation. These are excellent indicators of the reliability and trust of the data. However unlike other data quality indicators like Completeness, Validity, Accuracy, Consistency, Uniqueness, and Timeliness.(Read here) Data lineage can not me metricized.
The insights provided by Lineage enable data users to solve all kinds of problems encountered within mass quantities of interconnected data like Data troubleshooting, Impact analysis, Discovery and trust, Data privacy regulation (GDPR and PII mapping), and Data asset cleanup/technology migration, and Data valuation.
What is data observability?
Data Observability is a set of measures that can help predict, identify and resolve data issues.
Data Observability aims to reduce the mean time to detect (MTTD) and mean time to resolve (MTTR) data issues.
Why is lineage important for data observability?
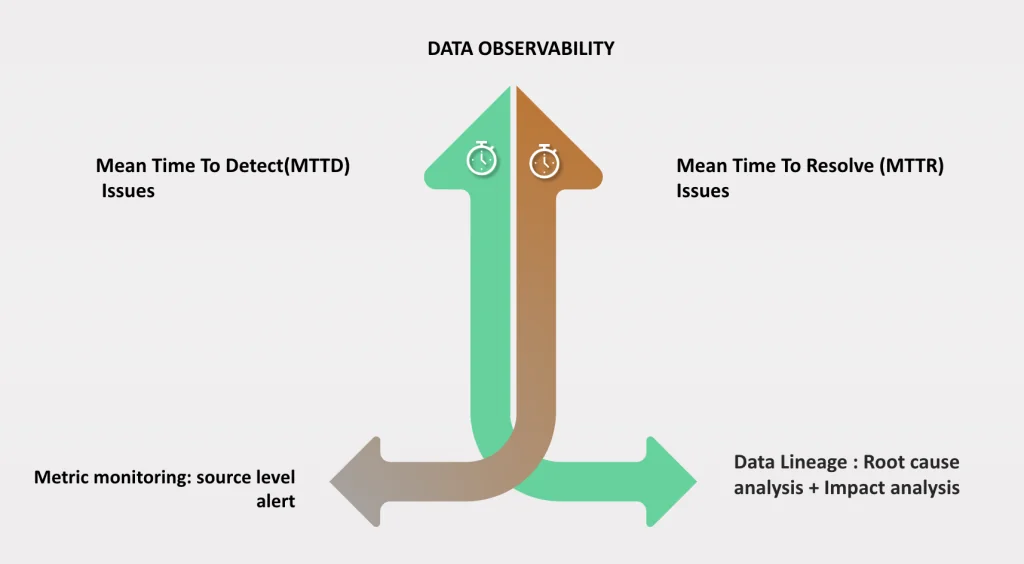
Data lineage can be very effective in getting good Observability outcomes.The insights provided by Lineage enable data users to quickly find the root cause of issues , conduct impact analysis also invoke a remediation.
So your data observability should leverage lineage information.
How is data lineage used in data observability?
Today, most data observability companies leverage Data Lineage for mean time to resolve (MTTR) issues by doing two things,
Root cause analysis (RCA)
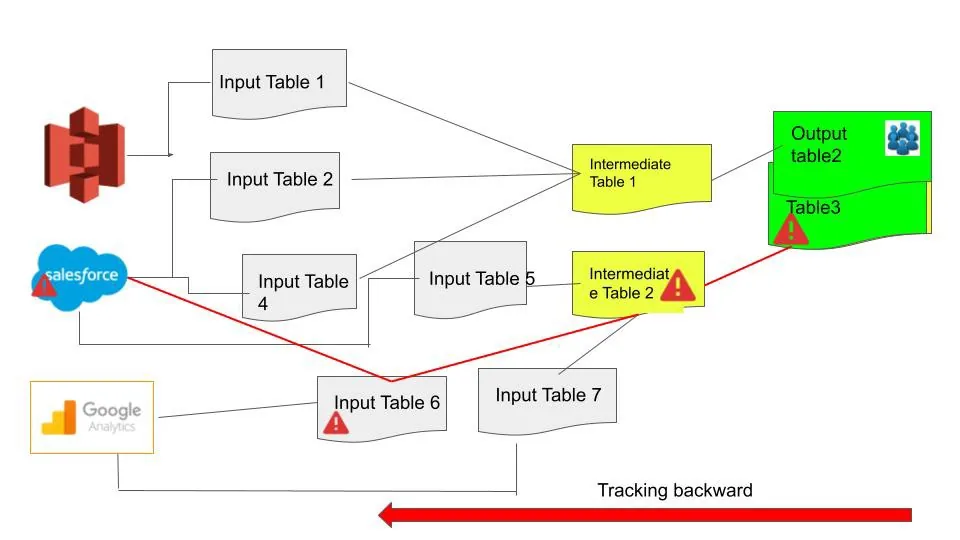
Once a monitoring system detects an issue, Lineage can help investigate the previous steps in the pipeline and changes. Specifically, if you are using Datawarehouse monitoring tools like Montecarlo data, Metaplane etc you can find table/view lineage, that can help shrink the root cause analysis time.
Downstream Impact Analysis
Often Data Lineage can help find downstream impact and invoke remediation flow. Remediation by definition is an reactive approach and can become a nightmare.
If you have a datamesh architecture, and have multiple consuming products using the data, leveraging lineage helps you identify which products are impacted and who own those products/systems. Now you can systematically notify those users. Other usecase is using Lineage you can identify the impacted dashboards.
The above methods are definitely useful but still suboptimal for data observability.
What is the correct usage of lineage in observability?
Data Observability, by definition, should be proactive. Data engineers should use Lineage to check downstream impact before adding any changes. For Example, am I making schema changes? Let me automatically check the downstream implications.
For data in motion a full pipeline monitoring approach will not only help with MTTR but also MTTD issues. Design a metric monitoring system that monitors every step in the data pipeline. So users get alerted when there is a drift or outlier in a specific step of the pipeline, and multiple data points will help detect issues even before a they have downstream impact.
Example : Get alerted that CRM system got partial data at 2pm PST.Such an alert can automatically be sent to CRM system owner, so data engineers dont have to find out about this issues inside Snowflake or BigQuery and reverse track them back to CRM system. Often this approach will also help orchestrate the date pipeline flow refer: Circuit breaker pattern.
A good analogy would be monitoring vs. tracing and logs. If you have a lot of monitoring, you may not need tracing and log review because tracking at every level will highlight the same problems but sooner. This is because all methods highlight the same issues just from different angles. So I would say that Lineage is a good tool for root cause analysis and impact analysis (MTTR) but your observability tools should focus higher on for mean time to detect (MTTD) issues i.e be more proactive.
Summary
Data Lineage is a crucial aspect of Data reliability. However, to effectively reduce the MTTD and MTTR data issues :
1: Leverage lineage to understand the downstream impact before making changes.
2: Monitoring important data metrics every step of the pipeline and leverage Lineage to identify where the metric has drifted.
Passionate about data quality? Get expert insights and guides delivered straight to your inbox – click here to subscribe to our newsletter now.
- On this page
See what’s possible with Telmai
Request a demo to see the full power of Telmai’s data observability tool for yourself.
Articles
See all articles

