Driving Reliable Graph Analytics on your Open Lakehouse Data with Telmai and PuppyGraph
Discover how Telmai and PuppyGraph enable zero-copy, validated graph analytics on open lakehouses like Apache Iceberg ensuring clean, trusted data for faster insights and smarter decisions.


As enterprise data ecosystems expand, data pipelines have become increasingly distributed and heterogeneous. Critical business information streams in from numerous sources, landing in diverse cloud systems such as data warehouses and lakehouses. With the rapid adoption of open table formats like Apache Iceberg and Delta Lake, extracting meaningful context from this complex data landscape has grown more challenging than ever.
Graph databases are emerging as a vital tool for enterprises aiming to surface nuanced insights hidden within vast, interconnected datasets. Yet, the reliability of any graph model hinges on the quality of its underlying data. Without clean, trusted data, even the most advanced graph engines can produce misleading insights.
This article examines why graph modeling on open lakehouses demands a heightened focus on data quality and how the combined strengths of Telmai and PuppyGraph deliver a robust, transparent, and scalable solution to ensure your knowledge graphs stand on a foundation of clean, reliable data.
What is a Graph Database?
A graph database models data as nodes and edges rather than rows and tables. This structure makes it ideal for querying complex relationships that include customer behavior, fraud detection, supply chain optimization, or even social behavior graphs.
Graph databases use nodes (representing entities) and edges (representing their relationships) to reflect real-world connections naturally. This model is especially powerful for answering questions like:
- How are customers, products, and transactions interrelated?
- Which suppliers, shipments, or touchpoints form a risk-prone chain?
- What are the shortest paths or networks among organizational entities?
There are two main types of graph databases:
- RDF (Resource Description Framework): Schema-driven, commonly used for semantic web applications.
- Property graphs: More flexible, allowing arbitrary attributes on both nodes and edges, making them intuitive for a wide range of use cases.
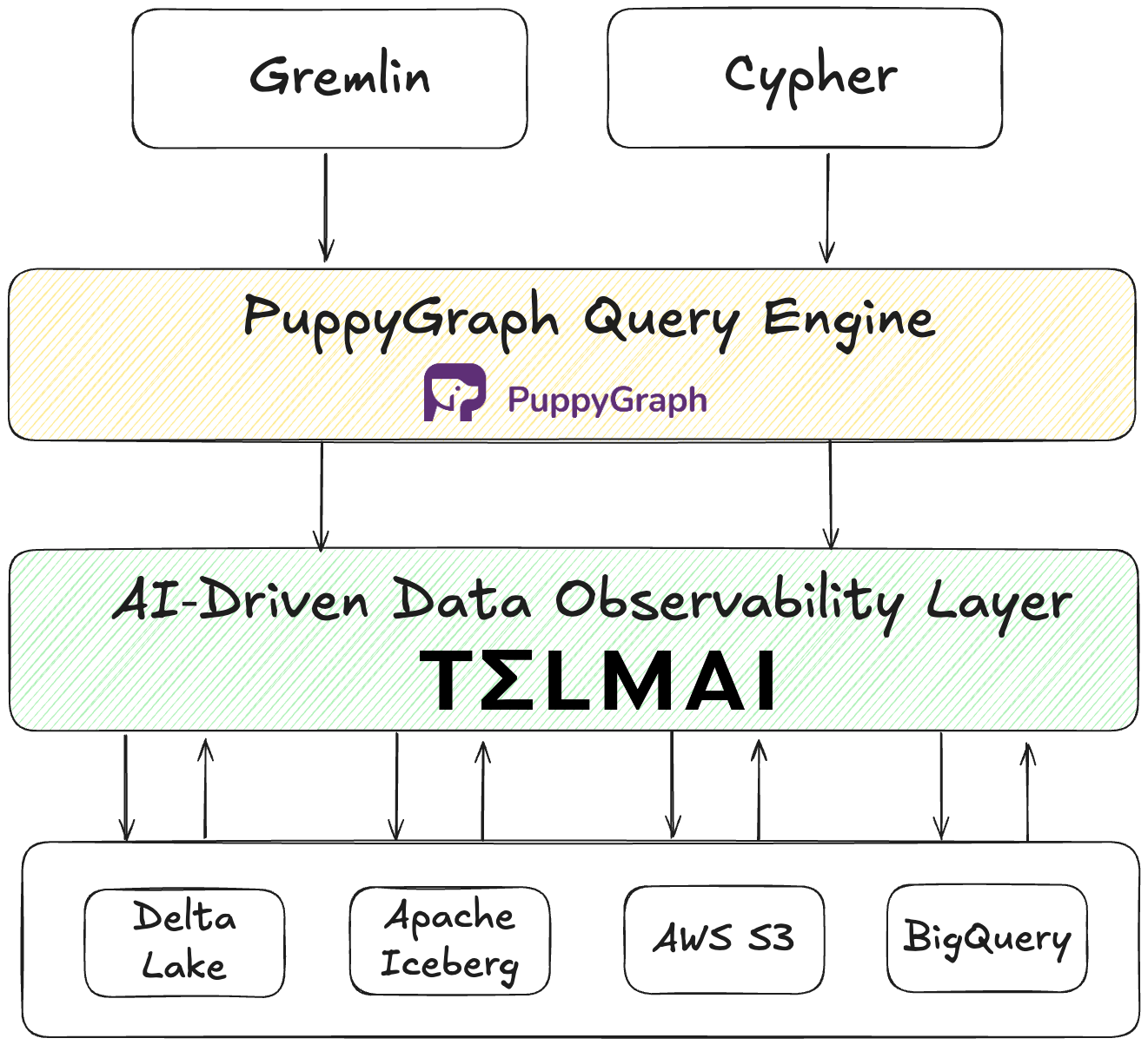
PuppyGraph is a high-performance property graph engine that lets you query structured data as a graph, making it easy to uncover relationships and patterns without moving your data into a separate graph database. It supports Gremlin and Cypher query languages, integrates directly with tabular data sources like Iceberg, and avoids the heavyweight infrastructure typical of traditional graph databases.
Graph Power Without Data Migration
Historically, running advanced analytics meant extracting data from storage and loading it into tightly coupled, often proprietary platforms. This process was slow, risky, and led to fragmentation and vendor lock-in.
Modern compute engines like PuppyGraph break this pattern by enabling direct, in-place graph querying over data in object storage. This creates a centralized source of truth while maintaining architectural flexibility, reducing complexity, and preserving data integrity, future-proofing your analytics stack.
Why Data Quality Must Be Built Into Your Graph Pipeline
Modern lakehouses built on open table formats like Apache Iceberg or Delta Lake promise agility, scale, and interoperability for enterprise data. However, their very openness can mask a new breed of data quality issues that quietly erode the value of downstream analytics, especially in graph modeling.
Key data quality issues common in open table formats and distributed pipelines that could affect graph modeling include:
- Schema drift and type inconsistencies: Data evolving over time may introduce mixed data types or missing columns, breaking parsing logic and causing graph construction failures or unexpected node/edge omissions.
- Null or missing foreign keys: Missing references between tables can create orphaned nodes or broken edges, fragmenting the graph and skewing relationship metrics.
- Inconsistent or mixed timestamp formats: Time-based event relationships rely on accurate event sequencing. Mixed formats disrupt these sequences, making time-based graph queries unreliable.
- Out-of-range or anomalous values: Erroneous measurements or outliers can bias graph algorithms, for example by inflating edge weights or misrepresenting geospatial relationships.
- Duplicate or partial records: These create redundancy and fragmentation, inflating graph size and complicating pattern detection.
- Referential mismatches across distributed datasets: Inaccurate joins lead to false or missing relationships, diluting the reliability of graph analytics.
The distributed and heterogeneous nature of lakehouse pipelines amplifies these challenges, as data flows through multiple ingestion points and transformations before reaching the graph layer. Without systematic, automated data quality validation before graph modeling, these hidden errors remain undetected—leading to delayed insights, costly rework, and even production outages.
Embedding rigorous data quality checks early in the pipeline ensures that your graph analytics start from a clean, consistent, and trusted foundation. This is where the combined strengths of Telmai and PuppyGraph offer a breakthrough.
How Telmai and PuppyGraph Transform Raw Data into Trusted Graph Analytics
Enterprise analytics delivers true value only when the data relationships it relies on are accurate and transparent. Telmai and PuppyGraph offer an integrated solution that validates and models data in real time ensuring every data node, edge, and relationship is trustworthy. This unified approach enables teams to interpret complex datasets with clarity and agility.
To bring the joint value of Telmai and PuppyGraph into sharp focus, let’s walk through a practical example using the Olist dataset — a publicly available e-commerce dataset rich with customer, order, product, and seller information.
In this dataset, we injected common data quality challenges such as:
- Null foreign keys (e.g., missing customer_id or seller_id), which break the critical links between customers, orders, and products
- Inconsistent timestamp formats : Mixing formats such as MM/DD/YYYY with ISO 8601 timestamps leads to unreliable temporal relationships. For graph analytics that rely on event sequencing, like tracking purchase funnels or supply chain timelines, this inconsistency results in erroneous ordering of events, skewed path analyses, and misleading temporal insights.
- Out-of-range values, like unrealistic product weights that skew relationship weighting and analytics
- Data type mismatches that lead to processing errors or dropped nodes during graph construction
If these issues remain undetected and uncorrected, the resulting graph will have broken edges, orphan nodes, and inaccurate relationship metrics,ultimately producing misleading insights and undermining trust in your analytics.
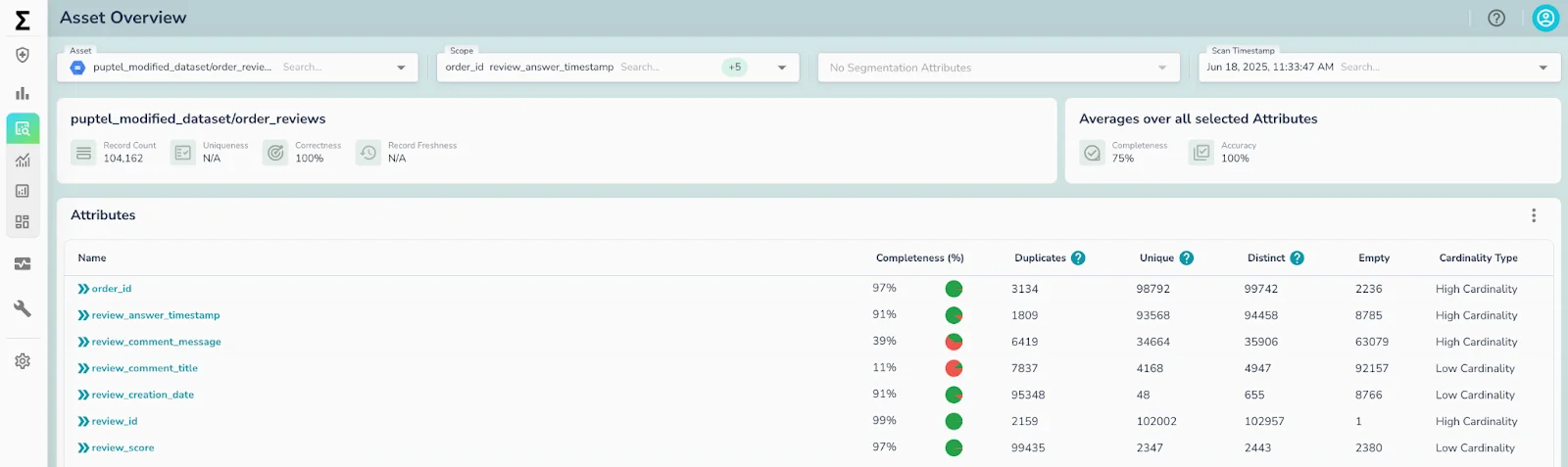
This is where Telmai plays a pivotal role. Before the data ever reaches the graph engine, Telmai performs comprehensive, full-fidelity data profiling and validation directly on the raw Iceberg tables in their native cloud storage location.
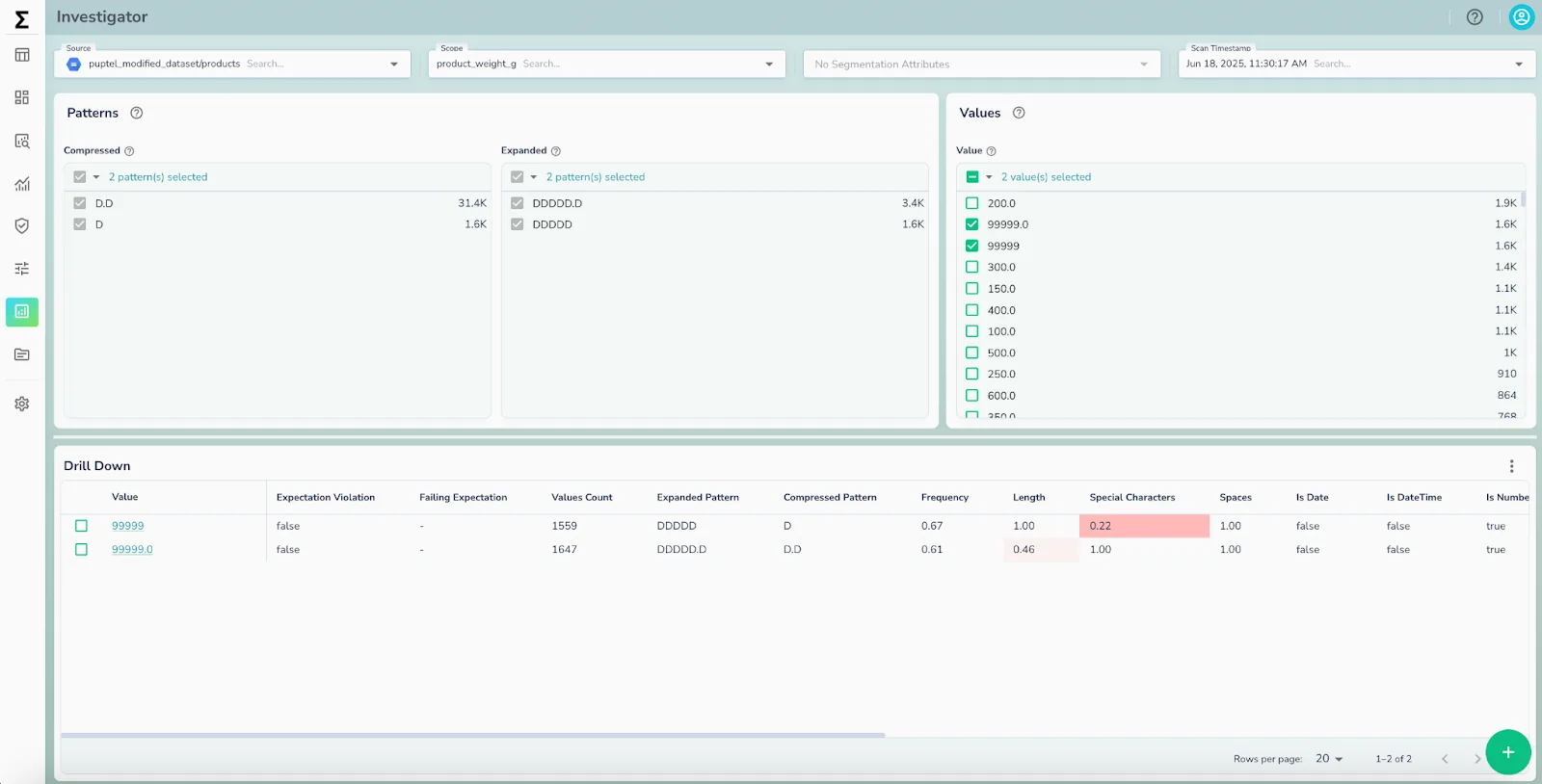
It automatically detects null keys, inconsistent formats, schema drift, and anomalous values, without resorting to sampling that might miss critical errors. Telmai surfaces these issues early, enabling data teams to correct or flag problematic data before graph modeling begins.
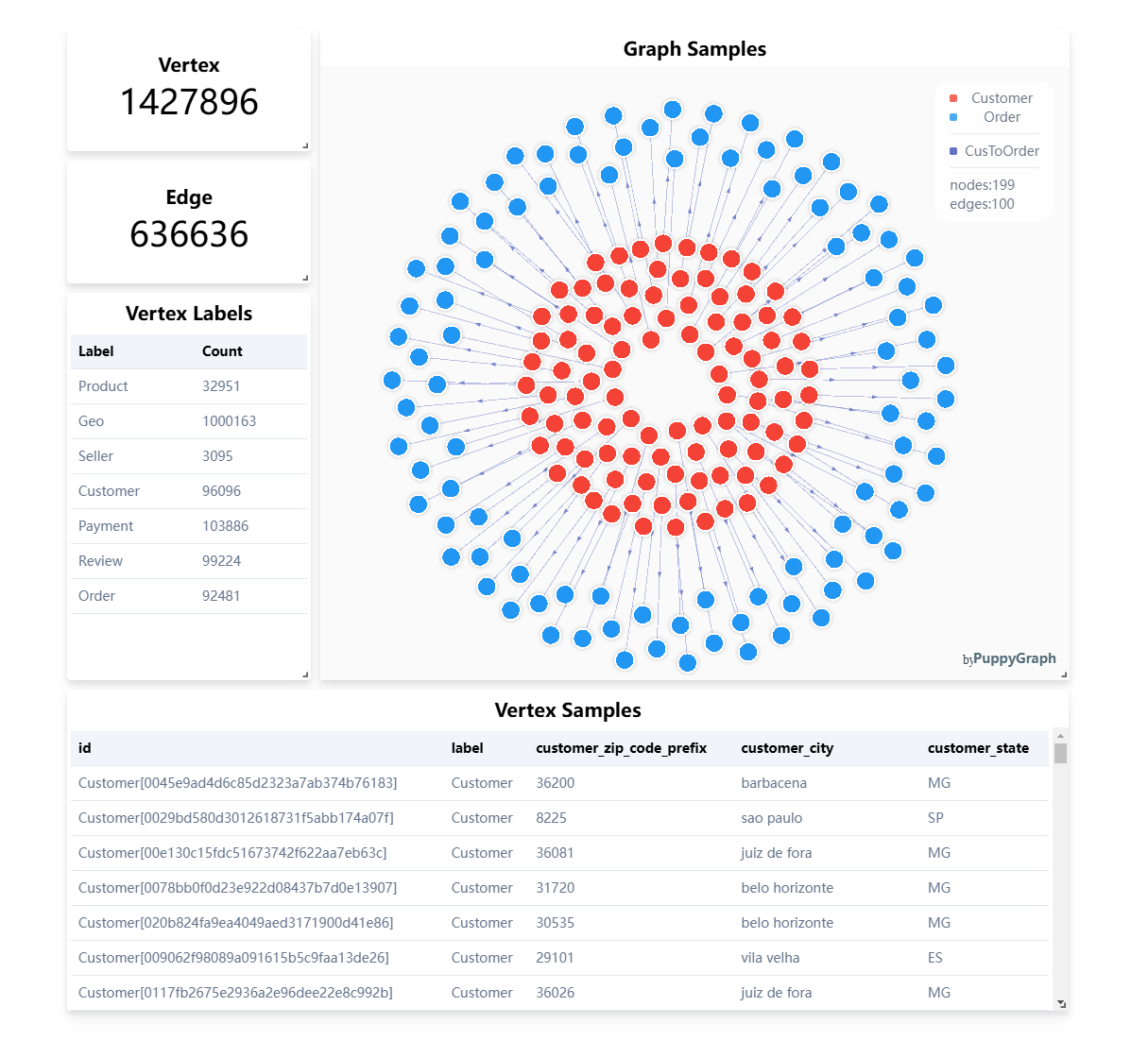
With this validated, clean data in place, PuppyGraph ingests the Iceberg datasets natively—eliminating the need for costly data migrations or fragile ETL processes. PuppyGraph then constructs accurate, high-performance property graphs that faithfully represent the true entity relationships and temporal sequences within your data.
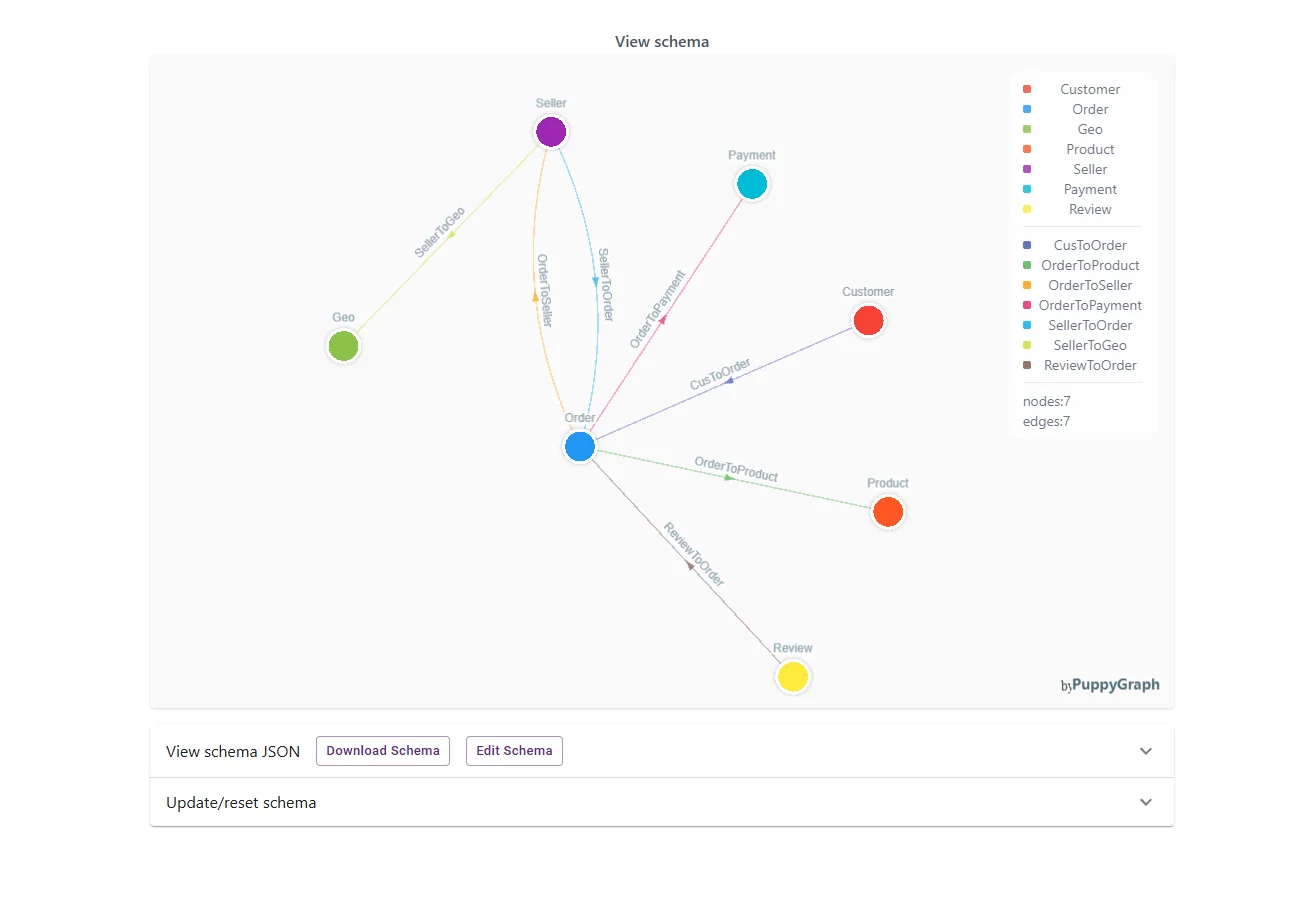
Graph algorithms depend heavily on the correctness of edges and nodes to surface meaningful relationships, identify patterns, and detect anomalies. By integrating Telmai’s rigorous data quality validation with PuppyGraph’s flexible, in-place graph computation, organizations gain confidence that their knowledge graphs are built on solid ground. This ensures faster onboarding, fewer silent errors, and graph analytics that reliably power critical business applications—from customer journey analysis to fraud detection and supply chain optimization.
The old adage “garbage in, garbage out” holds especially true here: graphs built on noisy or inconsistent data risk misleading conclusions, operational disruptions, and lost business opportunities.
Conclusion
Together, Telmai and PuppyGraph offer a seamless, scalable solution that enables enterprises to build trustworthy knowledge graphs on top of open lakehouses. By integrating rigorous data validation with high-performance graph modeling, here are the key benefits that this joint solution can offer:
- Faster onboarding: Validated data minimizes back-and-forth between data engineers and graph modelers, speeding up time to value.
- Fewer silent errors: Early detection prevents costly rework and avoids customer-facing problems caused by inaccurate graph outputs.
- Smarter data products: Reliable, high-quality graphs enable more precise personalization, recommendations, and fraud detection—driving better business outcomes.
Ready to build trusted, scalable graphs? Click here to talk to our team and learn how to turn your lakehouse into a source of clean, reliable insights.
Want to stay ahead on best practices and product insights? Click here to subscribe to our newsletter for expert guidance on building reliable, AI-ready data pipelines.
- On this page
See what’s possible with Telmai
Request a demo to see the full power of Telmai’s data observability tool for yourself.



