Data quality validation rules explained with examples
Data types, consistent expressions, syntax validation, and more. Explore 6 common types of data validation rules and best practices for implementing them.


Similar to how following a well-written baking recipe results in a mouth-watering dish every time, implementing data quality validation rules maintains the integrity and consistency of your organization’s data every time it’s acted upon. Data validation rules act as checkpoints, verifying that data stored in your systems conform to the required standards. What do these rules look like and how do you implement them effectively? This blog post will provide examples and share best practices for keeping your data as pristine as the ingredients in a master chef’s pantry.
Types of data validation rules
Let’s explore some common examples to understand data quality validation rules better.
Data type
Just as you wouldn’t pour milk into a measuring cup meant for flour, data type validation ensures that a specific field contains the appropriate type of information. For example, a name field should be a string, not containing any digits.
Range
Range validation is like specifying the appropriate temperature for cooking your dish. It sets the boundaries for numerical values to ensure they fall within a specific range. For instance, a data field could require a number between 0-1000 or a transaction amount greater than $0.
Consistent expressions
Consistent expressions are like the standard abbreviations used in a recipe. Data entries must use a uniform format to maintain consistency and avoid confusion. For example, using either “Senior,” “Sr.,” or “Sr” for a job title.
Controlled pick-list or reference data
This validation rule is similar to following a list of approved ingredients in a recipe. It ensures that data entries are selected from a pre-defined set of options, such as ISO-3166 country codes for location data.
Conformity to business rules
Adhering to business rules is like ensuring that your recipe’s steps are followed in the right order. For instance, a return date must always be greater than the purchase order date, preventing illogical data entries.
Syntax validation
Syntax validation is like the grammar of a recipe, ensuring data entries follow a specific format. For example, date fields should follow the DD-MM-YYYY format, and email addresses must include an “@” symbol.
Best practices for implementing data validation rules
Now that we’ve explored the most common types of data validation rules, let’s discuss some best practices for implementing them effectively.
Define clear data standards
Establishing clear data standards is like having a well-written recipe. It provides a foundation for validation rules, ensuring consistency and accuracy. Work with stakeholders to define the rules that best suit your organization’s needs.
Continuously monitor and improve
A master chef is always refining their recipe, and data quality should be approached similarly. Regularly review your data validation rules and update them as needed to accommodate changes in business requirements or regulations.
Train and educate users
Educating users about data validation rules is akin to sharing a recipe with a fellow cook. Training ensures that everyone understands the importance of data quality and adheres to the established guidelines. Regularly reinforce the rules and provide resources for users to reference.
Establish data governance
Just as a kitchen requires a head chef to oversee and manage operations, implementing data governance helps maintain data quality. Assign responsibilities and establish processes for data validation, ensuring that rules are consistently applied and updated as needed.
Test and validate
It’s essential to taste-test a dish before serving, and data validation rules should also be tested regularly. Verify that the rules are functioning correctly and make adjustments if necessary to maintain data quality.
Implement data cleansing
Occasionally, a chef may need to remove a stray ingredient from their dish. Similarly, data cleansing is the process of identifying and rectifying errors, inconsistencies, or inaccuracies in your data. Regular data cleansing helps maintain data quality and reinforces the effectiveness of your validation rules.
Automate the validation process
Just as a chef might use a mixer to streamline the cooking process, automating data validation can save time and reduce human error. The data observability platform Telmai can help you get started with data validation quickly with its real-time monitoring and alerting capabilities. You can schedule to run data validation on an hourly, daily, weekly, or monthly basis and automatically see alerts when your data validation falls outside expected norms.
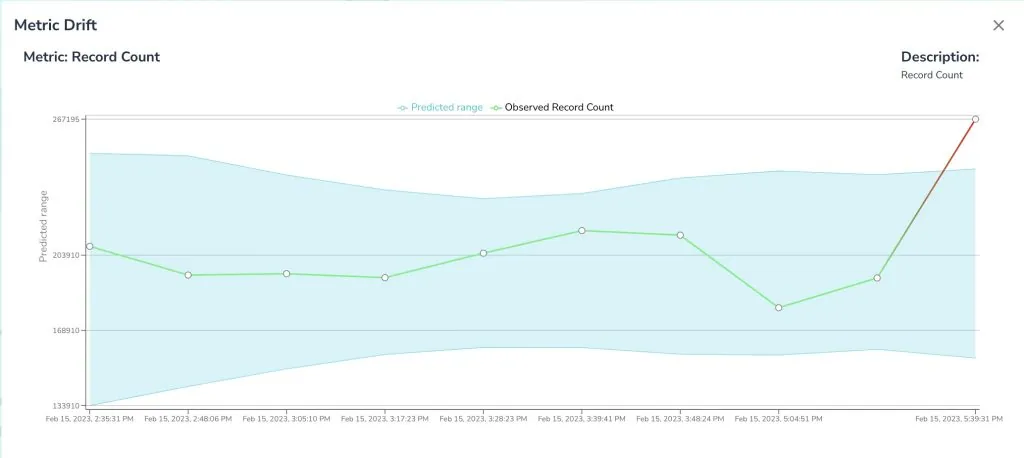
Data quality is an ongoing process
Remember, data quality is an ongoing process that requires continuous monitoring, refinement, and adaptation. Regularly review and update the data validation process as needed; outliers and anomalies could inform you to incorporate more validation rules into your workflow.
With a better understanding of data quality validation rules and their importance, you’re now equipped to embark on your own data quality journey. Bon appétit!
Passionate about data quality? Get expert insights and guides delivered straight to your inbox – click here to subscribe to our newsletter now.
- On this page
See what’s possible with Telmai
Request a demo to see the full power of Telmai’s data observability tool for yourself.
Articles
See all articles

