How data quality shapes the future of generative AI?
A “shift-left” approach and automating data quality checks can help to reduce the cost and timeframe of bad quality data impacting LLM training.


Almost every facet of our everyday lives has been transformed by generative AI (GenAI), with the space continuing to evolve rapidly. And what sits at the heart of the AI models fuelling the technological advancements emerging all around us? Data.

Consider LLMs like the GPT-4 architecture that powers ChatGPT. They’re trained on enormous amounts of text from the internet, books, articles, and so on to learn the statistical patterns and structures of human language.
The success of data-driven applications like these hinges on input data quality since bad data input leads to output that’s flawed or downright inaccurate. Data quality isn’t a new concept—bad data costs the data industry trillions of dollars every year—but it has assumed a whole new level of importance with the rise of GenAI.
In this post, we’ll expand on the importance of data quality in the context of GenAI and training LLM models, as well as how a “shift-left” approach and automating data quality checks can help to reduce the cost and timeframe of any relevant data project.
Maintaining data quality is a multifaceted challenge.
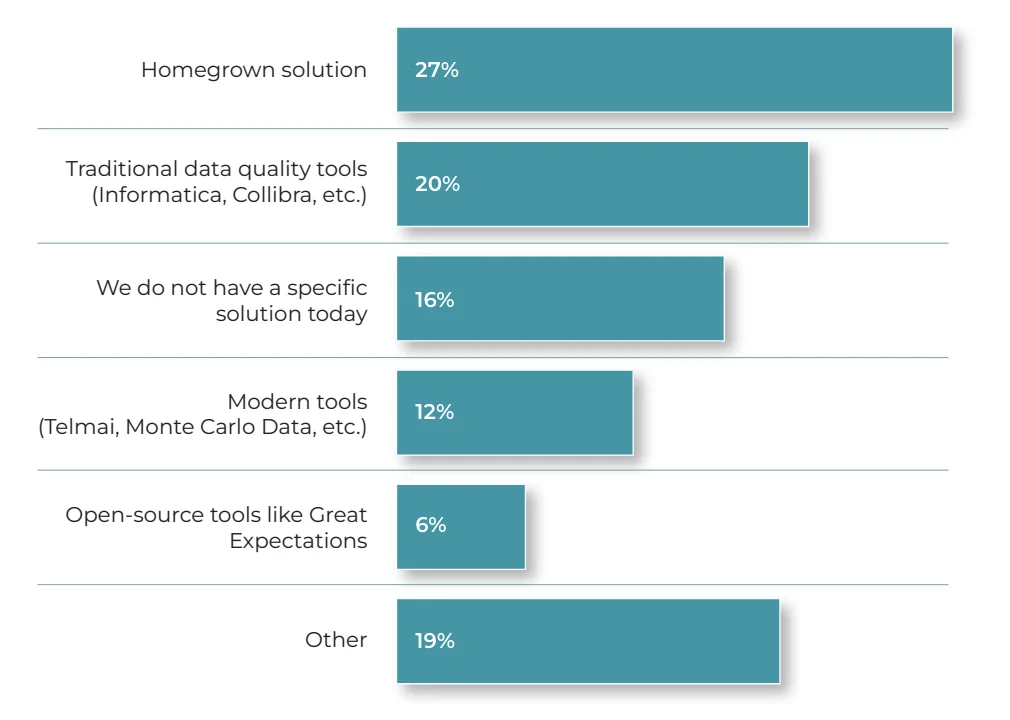
According to Telmai’s State of Data Quality Survey, which gathered information from data professionals across various industries, 27% of respondents use homegrown solutions, while 20% rely on traditional tools like Informatica and Collibra. Interestingly, 16% don’t have a specific solution in place. Modern tools like Telmai, as well as open-source tools like Great Expectations, are also being utilized, reflecting a blend of traditional and contemporary practices in data quality management.
Bad quality data impacting LLM training
The first ‘L’ – Large – of LLMs relies on big data to fill it out, which means taking advantage of massive volumes of data from a range of different sources. The model relies on this data being high quality to learn the complexities surrounding language patterns and how to generate coherent responses.
In the process of machine learning, models are shown numerous examples to generalize on new and unseen data. Likewise, LLMs learn from the underlying patterns in language data to generate text-based responses to different inputs.
Poor quality data, whether in the form of incomplete or inaccurate information, introduces harmful noise into the model’s training. This noisy data hinders the model’s ability to comprehend and generate accurate and meaningful context, which can lead to nonsensical or misleading answers. This can erode user trust in the efficacy of AI-generated content.
The cost of bad data for LLMs
Training LLMs requires significant computing resources and energy. The cost of allowing models to learn from noisy or erroneous records is significant: to put this cost in perspective, a 530-billion parameter model would cost ~$100 M in retraining. A big hit to any budget…
Of course, the cost of bad quality data isn’t limited to financial or computational resources. The iterative nature of this process results in significant time delays in building the model, which also contributes to the overall cost of its development.
OpenAI themselves have voiced concerns about making models “forget” bad data, again underscoring the importance of high quality data. In its absence, the scale and complexity of training LLMs increases substantially. So how best do we avoid using bad data?
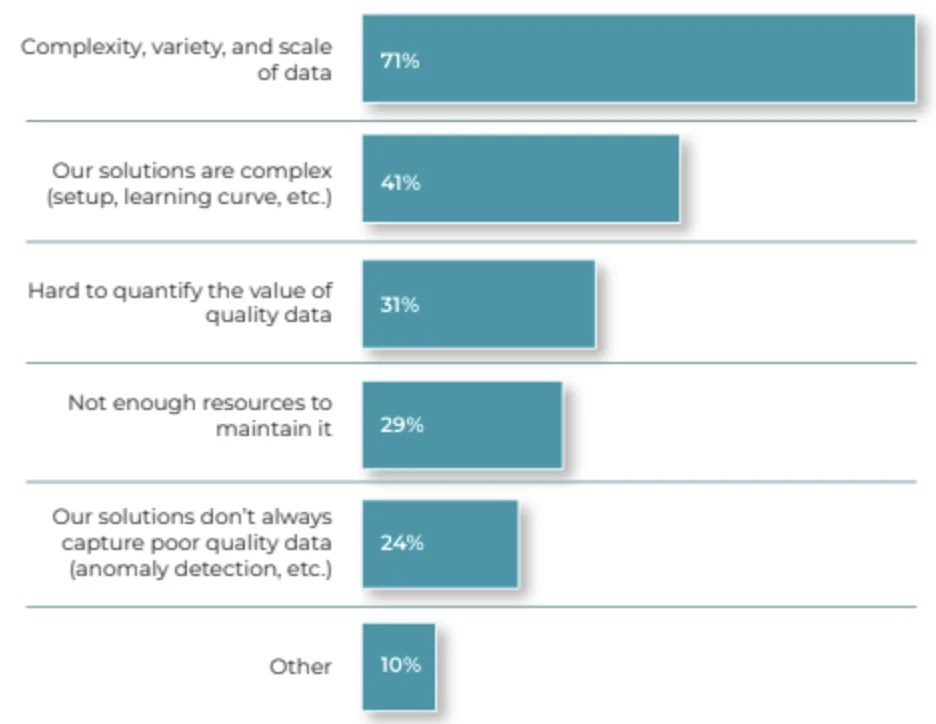
Our State Of Data Quality survey highlighted several challenges in managing data quality, including the complexity, variety, and scale of data (71%), the difficulty in quantifying the value of high-quality data (31%), and the lack of sufficient resources (29%).
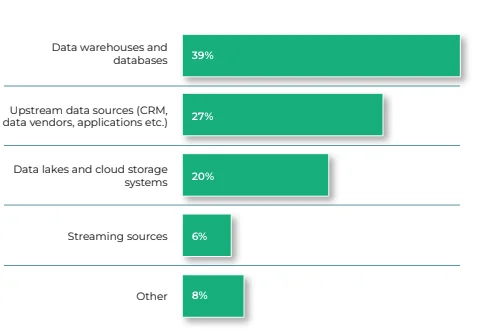
Additionally, key areas for improvement include data warehouses and databases (39%), upstream data sources (27%), and data lakes/cloud storage systems (20%).
Data monitoring and practicing “Shift-Left”
Implementing data monitoring checks at the source is a proactive approach to preserving data quality that has rapidly become a best practice. By eliminating the need for model retraining caused by data quality concerns that may arise later, it’s a way to save time and money.
The longer data quality issues persist, the more costly they become for an organization. By addressing these concerns early, shifting the focus of data quality downstream (i.e. “left”) away from consumers and towards its origin, the need for model retraining is minimized.
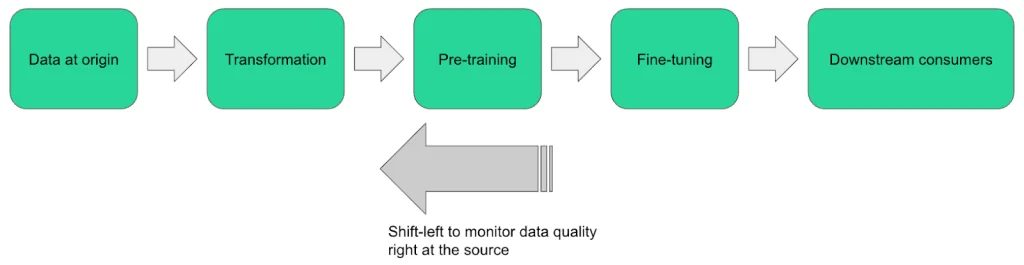
As well as reducing costs, a shift-left approach helps to reduce the strain on data teams. Model results must be assessed and validated by such teams, and their feedback is used to improve model performance. The earlier data monitoring checks are implemented, the less likely it is that teams will have to waste time assessing noisy, poor quality results.
The quest for good data
In an ideal world, we would only ever have to deal with good data. In reality, we need to take appropriate steps to ensure data accuracy, reliability, completeness, relevancy, etc. That includes extensive data pre-processing such as duplicate removal, spelling and grammar correction, outlier detection, and filtering irrelevant or low quality content.
Beyond that, we may need to analyze data in greater detail with checks like identifying:
- What values a field can entail
- Expected data type(s)
- What the schema looks like
- The definition of an outlier record
Data changes shape and form at every handshake, which requires an assessment of the intended vs. actual data transformation. Various rules and best practices – encompassing everything from in-depth business knowledge to data distributions and field types – exist for effective data assessment.
Although an understanding of these rules is vital, dealing with the big data used for LLM training is a whole different ball game. Manual monitoring is prone to human errors, not to mention being an extremely intensive process, which is why automated quality checks at scale have emerged as an essential part of the training process.
Stay ahead of data quality issues with Telmai
Ensuring high-quality data is paramount for the success of AI models like LLMs.By continuously monitoring your data, Telmai identifies and alerts you to any anomalies in real time, ensuring that you’re always working with the most accurate and reliable data. Whether it’s spotting missing values, detecting format inconsistencies, or ensuring data freshness, Telmai has got you covered.
Discover how Telmai can revolutionize your data ecosystem. Request a demo today.
Passionate about data quality? Get expert insights and guides delivered straight to your inbox – click here to subscribe to our newsletter now.
- On this page
See what’s possible with Telmai
Request a demo to see the full power of Telmai’s data observability tool for yourself.



